
Riffusion - 텍스트와 이미지에서 음악을 생성하는 인공지능 모델
텍스트나 이미지를 넣으면 음악을 생성해 주는 인공지능입니다.
위의 url은 웹 데모 영상입니다.
오른쪽 위에 빨간색 플레이 버튼을 누르면 음악을 플레이 해줍니다.
input 값에 내가 원하는 음악의 텍스트를 입력하면 이에 맞는 음악을 만들어 줍니다.
스테이블 디퓨전 1.5를 기반으로 했다는데 신기하네요.
모델과 코드 모두 공개되어 있습니다. 코드도 공개되어 있기 때문에 파이썬으로 다운을 받아서 돌리거나 코랩을 활용해서 돌릴 수 있습니다.
riffusion/riffusion-model-v1 · Hugging Face
스테이블 디퓨전을 파인튜닝해서 스펙토그램을 만들 수 있게 했다고 합니다.
그리고 이 스펙토그램을 음악으로 바꿀 수 있다고 합니다.
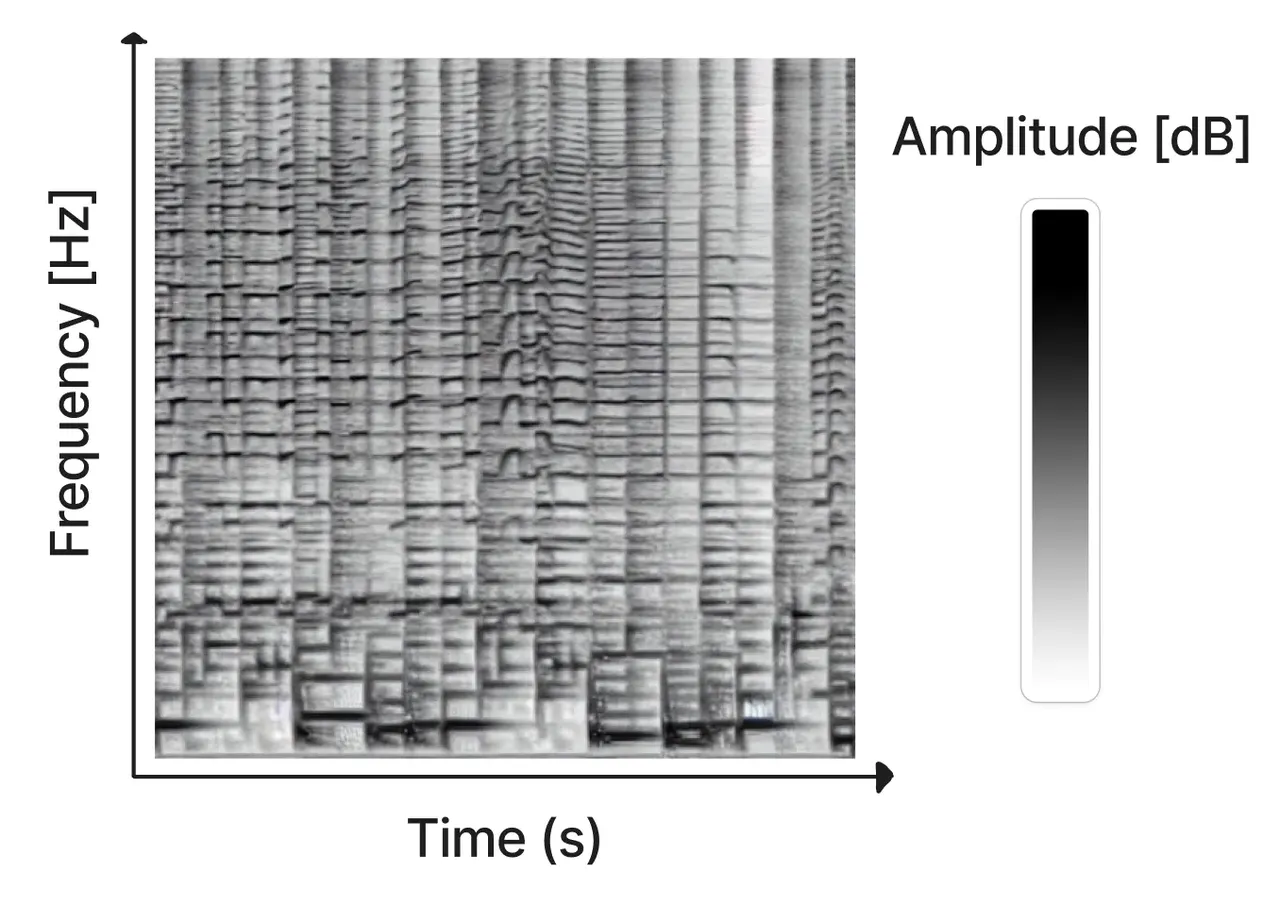
텍스트나 이미지를 이런 형식의 스펙토그램 (Spectrogram)으로 바꿔줍니다.
GPU 성능에 따라 한번에 5~10초 이상의 음악을 생성할 수 있습니다.
개발자들이 만들고 싶었던 것은 무한한 음악 재생이라고 합니다. 하지만 랜덤으로 생성된 음악을 하나의 음악으로 합치는 것은 어려웠다고 하네요. 그래서 Latent space (모델이 만들어 낼 수 있는 모든 가능한 공간을 포함하는 특징 벡터)의 가까이 위치한 시드들을 부드럽게 연결하는 방법을 고안했다고 합니다.
예를 들어 같은 시드 프롬프트에서 생성된 음악을 보간 (Interpolation) 을 활용해 연결해 긴 형태의 음악을 생성할 수 있습니다.

Riff의 원래 뜻은 2소절 또는 4소절의 짧은 멜로디를 반복하는 재즈 연주법이나 멜로디를 말합니다.
아직은 완벽한 긴 음악이라기 보다는 짧은 음악의 반복같은 느낌이 나기는 합니다.
어떻게 만들었는지 about 페이지에서 자세하게 설명하고 있습니다.