stable diffusion + controlnet 사용해 보기 - 뼈대만으로 이미지 만들기
stable diffusion에 이미지 구도만 입력하고 이걸 바탕으로 새로운 이미지를 생성해낼 수 있는 확장앱인 controlnet이 있습니다. (ControlNet - 이미지의 구조를 활용해서 새로운 이미지 만들어 내는 인공지능 모델)
뼈대나 프레임을 입력하면 이를 바탕으로 그림을 만들어 줄 수 있는 기능입니다.
오늘은 이 콘트롤넷을 사용해 보기로 했습니다.로컬에 webui를 설치하고 사용하는게 가장 정석인데 제 컴퓨터는 사양이 되지를 않네요. (그래픽카드 메모리 최소 4GB 이상) 노트북을 쓰시는 분들이나 낮은 사양의 컴퓨터를 쓰고 있다면 google colab으로 돌리면 됩니다.
camenduru의 google colab을 활용해서 실행해 보겠습니다. google colab을 공유할 때 항상 유의하고 있는데 camenduru는 찾아보니 꽤 이름 있는 유저라서 어느 정도 괜찮을 것 같습니다. colab을 사용하실 때는 구글 드라이브 권한이 필요한 노트북은 유의하시면 됩니다. 이 노트북은 구글 드라이브 권한이 필요하지 않습니다.
Drive로 복사를 눌러서 내 노트북으로 복사해 주고 실행을 눌러주면 됩니다. 이렇게 하면 필요한 패키지를 설치하는데 시간이 조금 걸립니다. 저의 경우 처음 실행 할 때 약 5분이 걸렸습니다.
그러면 some-id.gradio.live의 형식으로 url이 나옵니다.
해당 gradio 링크를 눌러서 접속하면 됩니다.
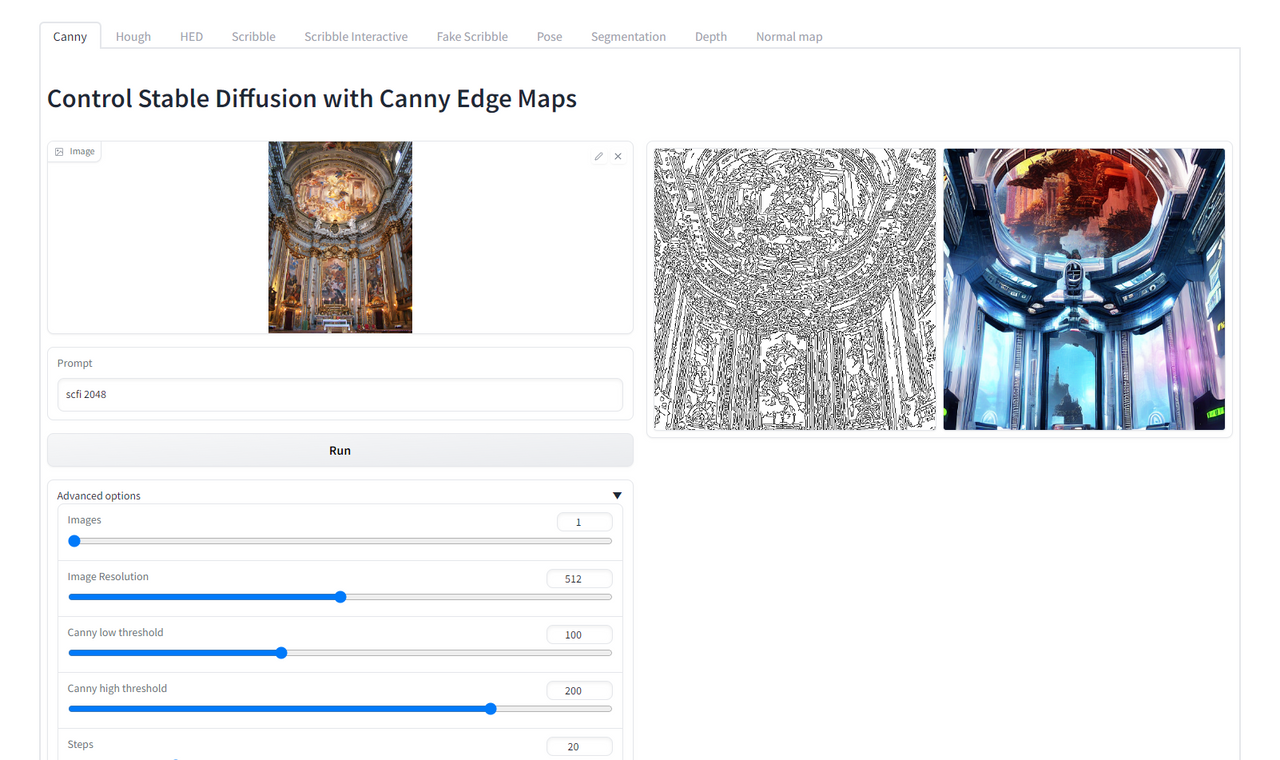
이런식의 web ui에서 사용할 수 있습니다.
위의 사진은 바로크 양식의 사진을 넣고 SF 양식으로 바꿔달라고 프롬프트를 넣은 형식입니다. 위에서 모델을 선택할 수 있는데 Canny는 canny edge detection의 뜻으로 사진의 검은 선으로 표시된 윤곽과 같은 그림으로 바꾸어 줍니다. 그리고 이를 바탕으로 새로운 이미지를 만들어내는 방식입니다. 오른쪽에 보시면 푸른 색의 SF 풍으로 바꾸어 준 것을 보실 수 있습니다.
모델은 Canny, Hough, HED, Scribble, Scribble Interactive, Pose, Segmention 등 다양하게 있습니다. 이 중 유명한 것은 Pose 입니다.
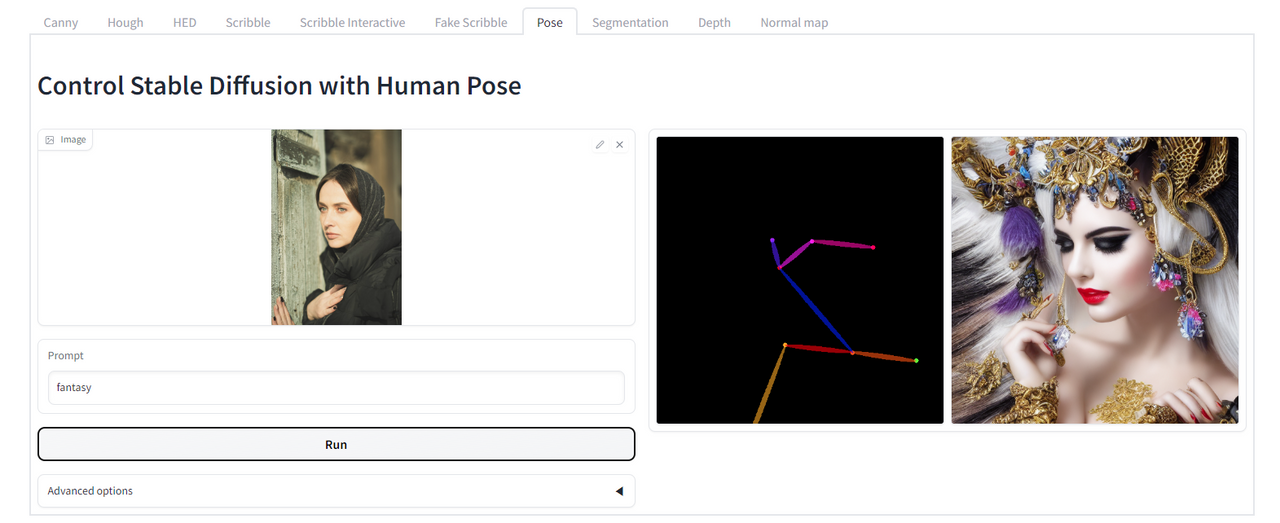
사진을 입력하면 졸라맨과 비슷한 뼈대 모양으로 바꾸어 주고 이를 바탕으로 prompt를 활용해 새로운 이미지를 만들어 줍니다.
인물의 사진을 넣고 판타지 풍으로 바꾸어 달라고 하니 오른쪽의 그림과 같이 나왔습니다.
이 colab에서 사용된 것은 stable diffusion model 1.4 입니다.
이런 방식으로 이미지를 생성하는데 조금씩 콘트롤하는 방법들이 생겨나고 있습니다. 예를 들어 프레임으로 뼈대를 그린 후 스테이블 디퓨전으로 완성된 그림을 얻는 방식으로 작업할 수 있습니다.
이런 기술들이 발전되면 어떤 특정한 캐릭터의 연속적인 움직임도 만들어 낼 수 있을거라고 봅니다. 이를 바탕으로 영화를 만들거나 다양한 작품들을 만들어 낼 수 도 있겠죠.
지금은 이미지 생성 AI는 랜덤한 이미지 생성이지만 사용자가 결과물을 통제할 수 있는 방법들이 계속 개발되지 않을까 예측해 봅니다.
컨트롤넷을 기억하시면 stable diffusion을 이해하는데 도움이 되실거 같습니다.