OpenAI whisper 사용법 - 음성을 텍스트로 변환할 수 있는 인공지능 10분 만에 사용하기
whisper란?
openai에서 공개한 인공지능 모델로 음성을 텍스트로 변환할 수 있는 기술이다. Speech to Text (STT)를 인공지능으로 가능하게 한다. 무료로 공개했으며 github에 코드가 올라와 있어 누구나 사용할 수 있다.
GitHub - openai/whisper: Robust Speech Recognition via Large-Scale Weak Supervision
이게 있으면 누구나 STT 기능을 쉽게 구현할 수 있다.
사용해 보기
오늘은 위스퍼를 한 번 사용해 보기로 했다. 일단은 모델별로 필요한 사양은 다음과 같다.
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en | tiny | ~1 GB | ~32x |
| base | 74 M | base.en | base | ~1 GB | ~16x |
| small | 244 M | small.en | small | ~2 GB | ~6x |
| medium | 769 M | medium.en | medium | ~5 GB | ~2x |
| large | 1550 M | N/A | large | ~10 GB | 1x |
작을 수록 속도가 빠르고 파라미터가 적다. VRAM이라는 그래픽카드 메모리가 신경쓰이기는 한데 로컬 컴퓨터에 상관없이 돌리기 위해 구글의 colab을 사용해 보자. 이렇게 하는게 로컬 컴퓨터의 환경에 이것 저것 깔리는 것을 방지할 수 있어 좋다.
https://colab.research.google.com/
무언가를 배울 때는 다른 사람이 성공한 걸 참고하면서 배우면 좋다.
Pete Warden이 github에 올려준 ipynb를 참고하면서 해보자.
해당 노트북 파일을 복사해서 실행해도 좋고 새로운 파일을 하나 만들어서 하나씩 해봐도 된다. 나는 새로운 파일을 만들어서 해보기로 했다.
구글 코랩을 열고 새로운 파일을 만들었다.
하지만 제일 먼저 런타임 - 런타임 유형 변경에서 하드웨어 가속기가 GPU로 바꿔주자. 머신러닝에는 GPU가 필수이다.
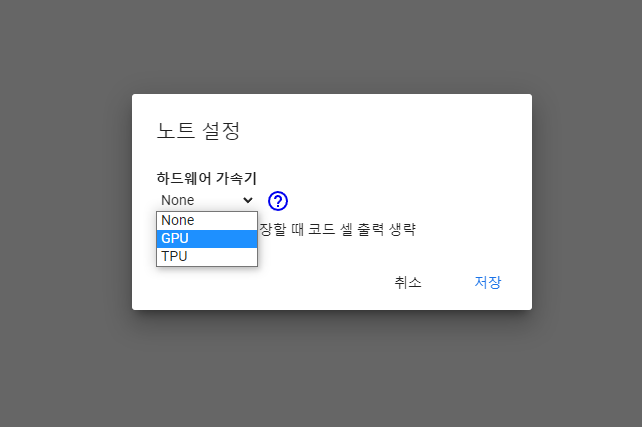
그 다음에 pete warden의 파일을 띄어놓고 하나씩 복사해서 실행해 보면서 해보면 끝이다.
! pip install git+https://github.com/openai/whisper.git -q
import whisper
model = whisper.load_model("base")
model.device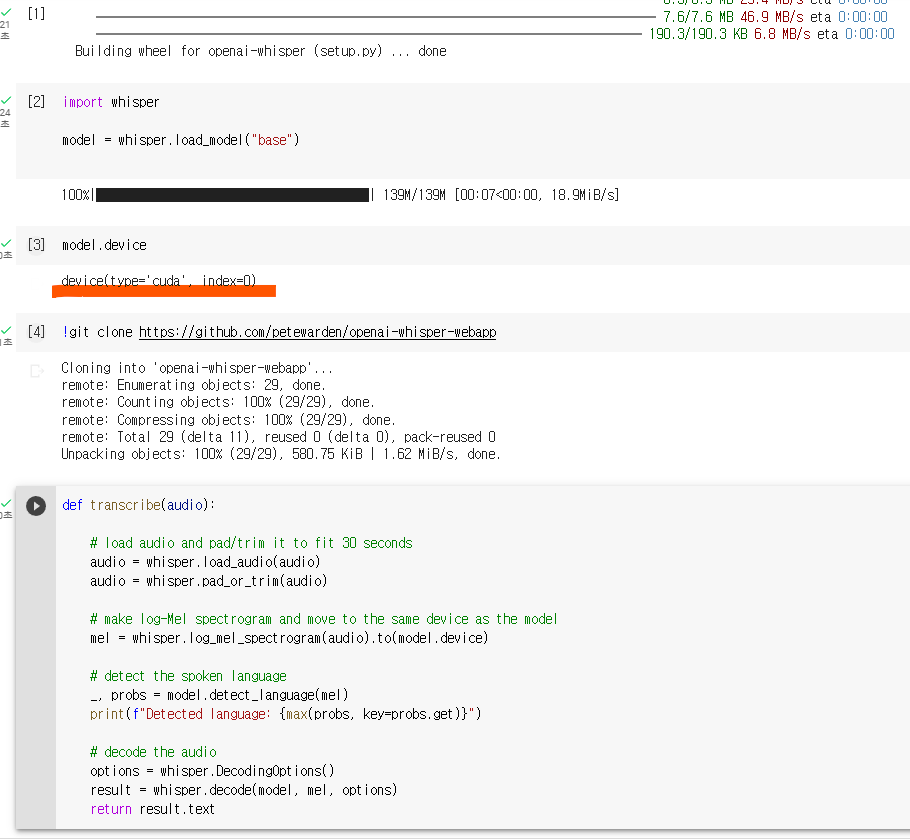
3번에서 model.device 에서 cuda라고 표시되는지 확인하자. gpu가 체크되어 있어야지 cuda라고 나온다.
transcribe 함수를 보면 어떻게 음성 파일을 받아서 텍스트로 처리하는지 로직을 볼 수 있다.
def transcribe(audio):
# load audio and pad/trim it to fit 30 seconds
audio = whisper.load_audio(audio)
audio = whisper.pad_or_trim(audio)
# make log-Mel spectrogram and move to the same device as the model
mel = whisper.log_mel_spectrogram(audio).to(model.device)
# detect the spoken language
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
# decode the audio
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
return result.text
easy_text = transcribe("/content/openai-whisper-webapp/mary.mp3")
print(easy_text)
hard_text = transcribe("/content/openai-whisper-webapp/daisy_HAL_9000.mp3")
print(hard_text)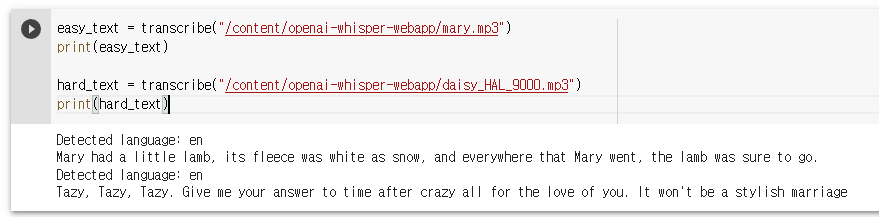
노트북 안에 준비되어 있는 파일이 2개 있는데 저런 방식으로 테스트해볼 수 있다. mp3 파일을 받아서 영어를 인식하고 받아쓰기를 한 결과를 위의 방식으로 처리할 수 있다.
마지막으로 웹캠 등 마이크가 있다면 gradio를 설치해서 웹 환경에서 사용해 볼 수 가 있다.
! pip install gradio -q
import gradio as gr
import time
gr.Interface(
title = 'OpenAI Whisper ASR Gradio Web UI',
fn=transcribe,
inputs=[
gr.Audio(source="microphone", type="filepath")
],
outputs=[
"textbox"
],
live=True).launch()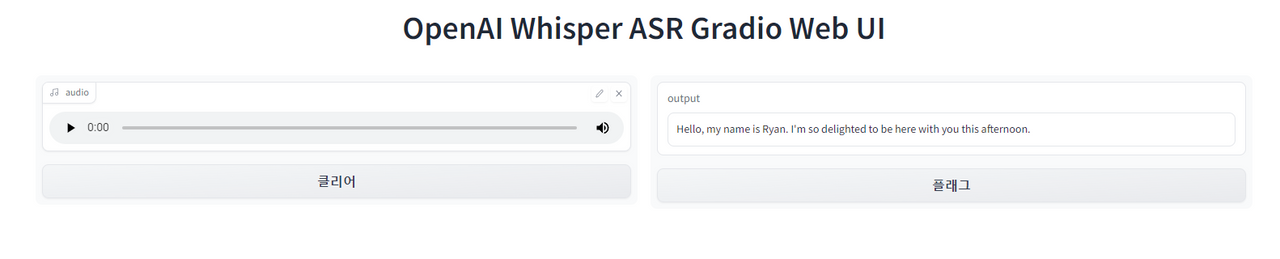
이건 영어를 받아쓰기한 내용이다. 꽤 잘 인식한다.
Hello, my name is Ryan. I'm so delighted to be here with you this afternoon.
이번에는 한글을 해보자.
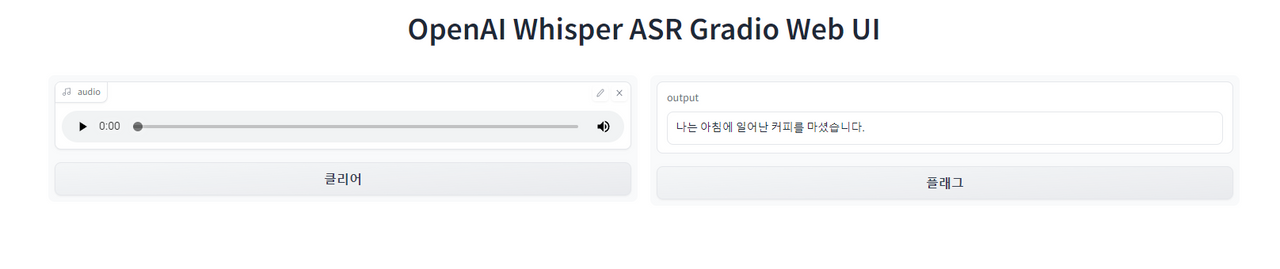
나는 아침에 일어나 커피를 마셨습니다. 라고 말했는데 나는 아침에 일어난 커피를 마셨습니다로 받아쓰기 됐다. 사용해 보면 영어나 한글 모두 약간의 오타율은 존재한다. 영어가 더 잘 인식된다.
다음은 whisper의 단어 오류율(Word Error Rate)을 표시한 그래프이다.
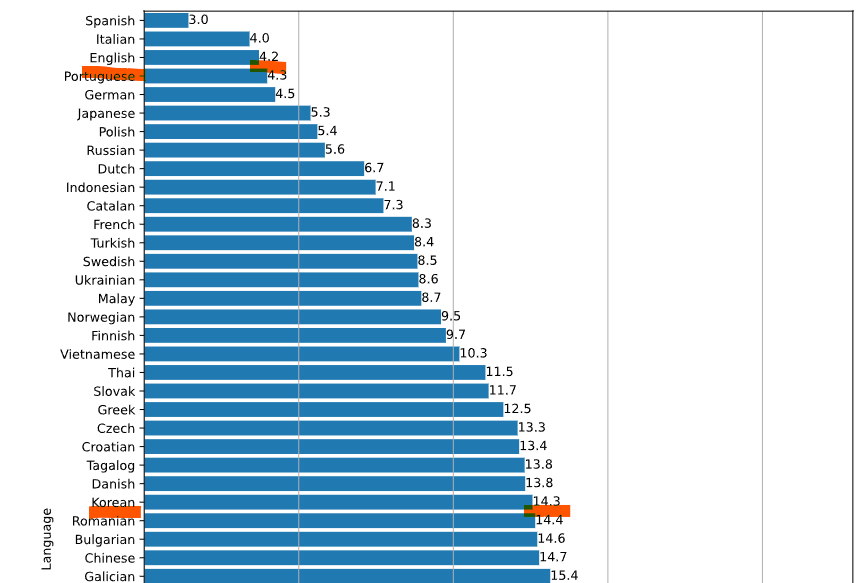
영어는 4.2 한글은 14.3 인 것을 알 수 있다. 낮을 수록 좋은 점수이다.
한 번 보고 돌려보는데 10분 정도 밖에 안걸렸던 것 같다. 10분 정도면 나만의 stt 머신을 가질 수 있다.
이 whisper가 있으면 클로바 노트와 같은 서비스가 가지고 있는 받아쓰기 기능이나 동영상 대본 받아쓰기 등의 기능을 쉽게 만들 수 있을 것 같다. 물론 한글 인식의 정확도는 기존 서비스를 따라가기는 힘들겠지만 이 정도가 가능한 것 만으로도 엄청난거 같다.
관심있으면 한 번 시도해 보자!