
OpenAI o3 공개 - OpenAI는 AGI에 도달하는가?
OpenAI는 o3 모델을 발표 했습니다. 이 모델은 추론 모델인 o1의 후속작으로, o2가 아닌 이유는 영국의 통신사 O2와 상표권이 겹치기 때문입니다. o3는 기본 모델과 미니 모델로 나뉘며 특정 조건에서 일반 인공지능(AGI)에 접근할 수 있다고 주장하고 있습니다. o3와 o3 미니는 아직 널리 공개되지는 않았으나, 안전 연구자들은 테스트에 참가 신청 할 수 있습니다.
o3 mini는 1월 말 경에 공개될 예정이며, o3는 그 후 곧이어 공개될 것입니다.
o3는 "추론 시간"을 조정할 수 있는 능력을 갖추고 있으며, 계산 수준에 따라 성능이 향상됩니다. 모델은 낮음, 중간, 또는 높은 계산(즉, 사고 시간)으로 설정할 수 있으며, 계산이 높을수록 o3의 성능이 향상됩니다.
특정 벤치마크에 따르면 OpenAI는 AGI에 점차 가까워지고 있습니다. AI 시스템이 훈련된 데이터 외부에서 새로운 기술을 효율적으로 습득할 수 있는지를 평가하기 위해 설계된 테스트인 ARC-AGI에서, o3는 최고 성능에서 87.5%의 점수를 기록했습니다. 낮은 컴퓨팅 환경을 가지고 있는 최악의 환경에서도 o1의 기능을 세 배 이상 상회하는 성적입니다.

Arc-AGI에서는 훈련 데이터에 없는 패턴을 알아낼 수 있는지 확인한다. 인간은 빈 칸에 진한 파란색이 채워진다는 것을 직관적으로 알아차릴 수 있을 것이다.
o3는 "심의적 정렬(deliberative alignment)" 기법을 사용합니다. 이는 인간이 작성한 안전 사양 텍스트를 학습시켜 LLM이 이를 추론하며 답변하도록 훈련하는 새로운 정렬 전략입니다. 또한, 대부분의 모델과 달리 o3는 스스로 사실 확인을 수행하기 때문에 물리학, 과학, 수학 등의 분야에서 신뢰성을 보입니다. 이 팩트 체크에 추가로 수초에서 몇 분까지 걸릴 수 있다고 합니다.
o3의 주요 성능 수치는 다음과 같습니다:
소프트웨어 엔지니어링 벤치마크 (SWE-bench, 실제 깃허브 이슈 해결) : 약 71.7%의 정확도 (o1보다 20% 이상 높음)
Codeforces 컴페티션: 약 2727 ELO
수학 컴페티션 벤치마크: 약 96.7% 정확도
GPQA Diamond 벤치마크: 87.7% 정확도
Epic AI의 Frontier 수학 벤치마크: 약 25% 정확도.
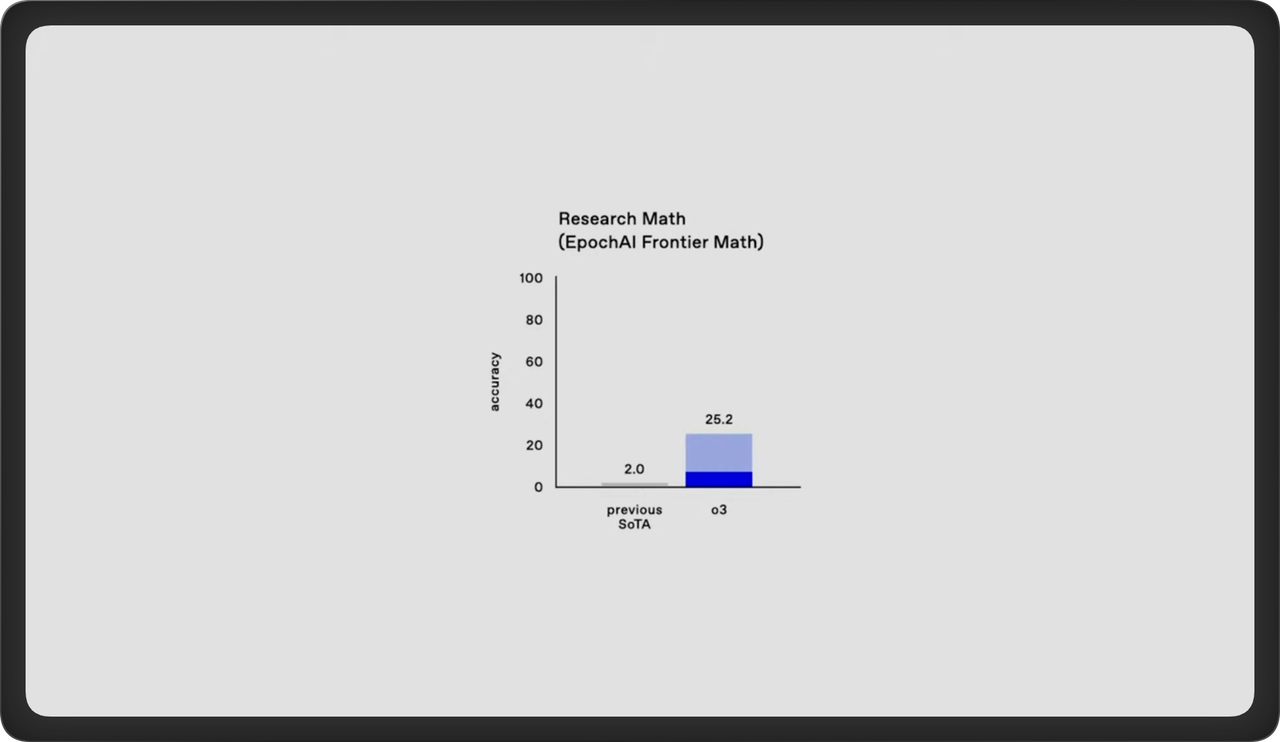
Epic AI 의 Research Math 벤치마크는 가장 어려운 수학 문제들을 모아놓은 데이터 세트이다.
o3 벤치마크에서 짙은 부분은 단 한번의 시도이고, 25.2%는 모든 옵션을 고려하여 여러 시도의 합의.
Arc AGI 벤치마크: 낮은 컴퓨팅 설정에서 75.7%, 높은 컴퓨팅 설정에서 87.5%
추가적으로, o1 mini의 API는 함수 호출과 구조화된 출력, 개발자 메시지 기능을 지원하며 비용 효율적으로 사용할 수 있습니다.
비용
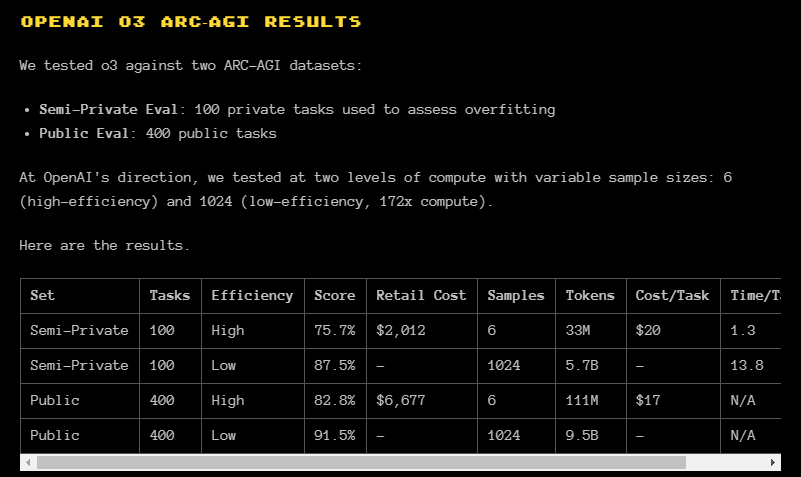
아크 AGI의 벤치마크에서 살짝 o3의 비용을 추론해 볼 수 있습니다. 저사양에서 작업 당 17~20달러 정도의 컴퓨팅 연산 비용이 드는 군요. 이는 인간이 하나의 작업 당 5달러가 드는것에 비하면 아직 높은 편입니다. 최고 성능의 연산은 아크에서 TBD로 아직 밝힐 수는 없다고 하지만 172배 정도 일 것이라고 보면 될 것 같습니다.
Retail Cost는 Semi private 100번, Public 400번해서 최종 스코어를 얻기 위한 총 비용인 것 같습니다.
LLM이 "단순 암기, 불러오기, 적용"의 한계를 갖는 반면, o3는 테스트 시점에서 새로운 프로그램(Chain of Thought)을 탐색, 생성, 실행 합니다.
AlphaZero 방식의 몬테카를로 트리 탐색(MCTS)과 유사하게, 토큰 단위에서 프로그램을 탐색하는 과정을 활용하는 것으로 추정된다고 합니다.
참고로 ARC-AGI를 만든 프랑스와 숄레 (François Chollet) 는 Keras의 창시자입니다.
참고
시사점
o3의 등장으로 우리가 AGI 의 길목에 실제로 들어선 것을 알 수 있습니다. 빠르면 내년 2월 또는 1/4 분기에 o3를 볼 수 있게 될 것 같은데요. 이는 사람과 거의 유사하게 작업을 할 수 있는 AI가 등장한다고 보면 될 것 같습니다.
하지만 대규모 인간 레이블(CoT)을 필요로 하며, 스스로 프로그램 생성·평가 능력을 학습하는 자율시스템(AlphaZero 등)과는 차이가 있습니다.
또한 일부 쉬운 문제도 놓치며, 비용이 인간 해결보다 비싸지만 빠른 비용 절감과 성능 개선이 예상된다고 합니다.
추론 모델은 생성 전에 AI가 인간의 CoT를 모방하여 사고를 하는 과정을 추가한 것인데요. 이전 OpenAI 수석 과학자였던 일리아 서츠케버가 냈던 아이디어로 알고 있습니다. (현재 Super Safe Intelligence 회사 운영)
또한 추론 모델은 지능이 높아지면서 인간을 속이려고 하는 시도도 발생한다고 하기 때문에 안전 문제에 주의를 기울여야 할 것 같습니다.
o3를 통해 AGI에 도달했다고 말하기는 어렵지만 기존 LLM의 한계였던 즉석 지식 재조합 문제를 상당 부분 해결하며, 실제 '돌파구'를 보여주는 사례입니다.
지금은 비용이 비싸지면 인간과 대등한 비용 대비 효율에도 도달 할 것으로 보입니다.
여러분은 어떻게 생각하시나요?



