
음성 인식 AI Whisper 사용법 - 동영상 자막 무료로 생성하기
Whisper는 OpenAI에서 만든 음성을 텍스트로 변환해주는 인공지능입니다. (Speech To Text) 내가 한 말을 실시간으로 텍스트로 바꿔줄 수 도 있고 영상파일이나 음성 파일을 받아 받아쓰기를 한 후 자막 파일(srt 등)을 만들어서 활용할 수 도 있습니다. 오픈소스로 누구나 무료로 사용할 수 있게 공개되었습니다.
이 위스퍼 활용법을 실습을 통해서 학습해 봅시다. 동영상 파일을 받아서 자막 파일을 생성하는 것을 진행해 보겠습니다.
Whisper를 사용할 수 있는 방법은 다음과 같은 것들이 있습니다.
로컬 데스크탑에 설치 (높은 VRAM 필요)
구글 colab에서 사용하기
OpenAI의 Whisper 사용하기 (비용 발생)
컴퓨터의 사양이 좋다면 로컬에 설치하는 것이 가장 좋은 방법입니다. 하지만 우리는 접근성이 가장 좋은 google colab으로 진행해 보겠습니다. google colab은 무료로 파이썬을 실행할 수 있는 노트북 환경입니다. 구글 콜랩의 t4를 활용하면 약 12GB 이상의 VRAM을 활용할 수 있습니다.
참고로 모델별로 필요한 사양은 다음과 같습니다.
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en | tiny | ~1 GB | ~32x |
| base | 74 M | base.en | base | ~1 GB | ~16x |
| small | 244 M | small.en | small | ~2 GB | ~6x |
| medium | 769 M | medium.en | medium | ~5 GB | ~2x |
| large | 1550 M | N/A | large | ~10 GB | 1x |
구글 colab 사용해보기
제가 Google Colaboratory 에 미리 노트북을 만들어 놓았습니다. tilnote-whisper
노트북 복사하기
이 해당 노트북을 복사해서 여러분의 노트북으로 만들어 주세요. 노트북을 복사하지 않으면 원본 노트북의 세션에 여러분이 올린 파일이 남을 수 있습니다. 상단 메뉴에서 파일 - Drive에 사본 저장 을 누르면 됩니다.
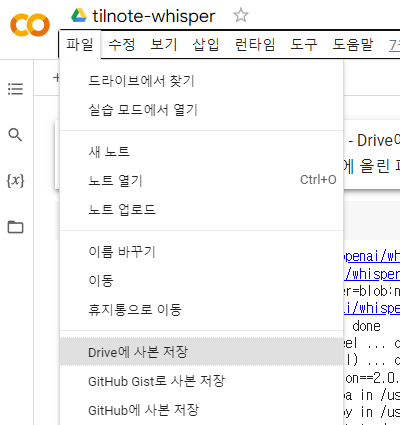
혹시 메뉴가 보이지 않는다면 우측 상단 헤더 공개 버튼이 접혀져 있지 않은지 확인해 보세요.
첫번째 코드 블록을 실행 버튼을 눌러 실행해 주세요.

! pip install git+https://github.com/openai/whisper.git 라는 명령어는 콘솔에서(!) pip 매니저를 통해 openai-whisper를 설치하는 역할을 합니다.
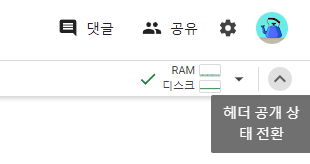
GPU 확인하기
메뉴에서 런타임 - 런타임 유형 변경에서 하드웨어를 GPU가 되어있는지 확인해 주세요.
파일 올리기
파일이 클 경우에는 구글 드라이브를 마운트해서 올리는게 훨씬 빠릅니다. 용량이 큰 경우 구글 드라이브를 마운트하는 코드를 로드해서 활용해 주세요.

마운트 된 구글 드라이브는 세션 고립이 되어 다른 사람이 볼 수 는 없습니다. 현재 세션에서만 드라이브의 파일들을 볼 수 있습니다.
구글 드라이브에 파일을 업로드 한 후 /content/gdrive 경로 부분을 적절히 수정해 주세요. 저는 youtube 폴더를 만들고 올려 다음 줄의 코드를 다음과 같이 수정했습니다.
! whisper 'content/gdrive/MyDrive/youtube/myfile.mov' --language Korean --model large
동영상의 경우 음성 파일만 export 해서 활용하면 적은 용량에서 활용할 수 있습니다. 저는 편집이 다 끝나고 마지막에 자막 작업을 할 때 음성 파일을 export 해서 작업합니다.
파일이 작거나 테스트를 하시는 경우는 구글 드라이브 로드 부분을 넘기고 아래 코드를 실행하면 됩니다.
'코드 블록의 재생 버튼'을 누른 후 파일 선택 버튼을 눌러 전사할 (transcribe) 음성 파일을 올려 주세요. (직접 파일을 올린 후 밑에 코드에서 경로만 바꿔주셔도 됩니다.)

파일이 없으시다면 제가 파일 2개를 샘플로 준비해 놓았습니다. (브루로 생성한 인공지능 목소리입니다.)
korean-sample.mp3 : 짧은 버전
korean-sample-long.mp3 : 긴 버전
짧은 버전으로 테스트해 봅시다. 참고로 파일을 올리면 좌측 상단의 파일 아이콘의 /content 폴더에 저장됩니다.
전사하기 (transcribe)
그 다음 코드 블록을 실행해 whisper를 실행해 봅시다.
! whisper '/content/{file_names[0]}' --language Korean --model large
large-v3 처음 실행 시 다운로드를 받습니다. 언어 모델은 large-3가 나왔기 때문에 large를 입력하면 v3 버전으로 연결됩니다. `large-v3` release · openai/whisper · Discussion #1762
다운로드를 받는 동안 명령어는 중요하기에 같이 살펴보겠습니다. --language 는 Korean으로 선택을 했습니다. 음성의 입력 파일이 한국어라는 뜻입니다. 영어의 경우 language 지정이 필요없고 다른 언어의 경우 마찬가지로 지정을 해주면 됩니다.

이런 식으로 음성 파일의 내용을 타임스탬프와 함께 받아쓰기한 결과를 받을 수 있습니다. 좌측의 파일 아이콘을 누르시면 다양한 자막 파일이 생성된 것을 확인할 수 있습니다.
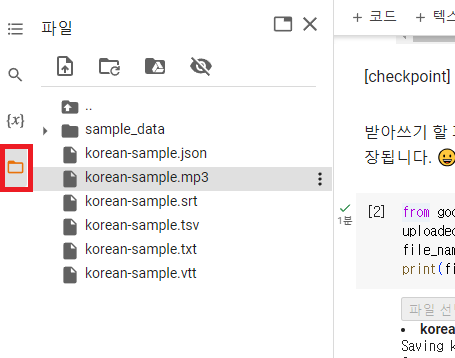
여기에서 srt 파일을 프리미어 프로나 다빈치 리졸브, 브루 등 동영상 편집프로그램으로 옮겨서 작업을 하면 됩니다.
진짜 엄청나지 않나요? 개인적인 경험으로 유료인 프리미어 프로의 자동자막 보다 더 잘 인식이 되는 것 같습니다. 이를 활용하면 회의록 녹취록이나 음성 메모를 텍스트로 바꾸는 등 다양한 일들을 수행할 수 있습니다.
지금 우리가 사용한 인터페이스는 데스크탑에 설치해서 커맨드라인 인터페이스를 사용한 것과 동일합니다. 데스크탑 설치 방법과 모든 사용법은 openai 공식 github에 있으니 참고해 주세요.
공식 github : GitHub - openai/whisper: Robust Speech Recognition via Large-Scale Weak Supervision
지금 우리가 만든 코드는 앞으로도 실제로 사용할 수 있는 코드입니다. 여러분의 동영상 파일에 자막을 만들 때 앞으로 활용해 보세요.
사용하면서 느낀점
다음은 제가 사용하면서 느낀점과 추가로 알아두면 좋은 것을 정리한 것입니다.
장점
인식율이 정말 좋습니다. 프리미어 프로 자동자막은 한글과 영어 등 언어가 섞여있을 때 인식을 잘 못하는데 위스퍼는 잘 구별해서 인식합니다.
비싼 Whisper API와 동일한 기능을 무료로 사용할 수 있습니다.
Colab을 활용해 10GB VRAM 정도의 하드웨어가 필요한 large 모델을 무료로 사용할 수 있습니다.
단점
파일을 직접 올릴 때 시간이 오래 걸립니다. 구글 드라이브를 연결해서 올려야 빠르게 업로드할 수 있습니다.
세션이 초기화되면 다시 실행해야 합니다. 구글 colab의 세션 최대 유지 기간은 12시간입니다. 이 시간이 지나면 다운로드 받은 모델과 올린 파일이 사라집니다. 이 시간이 지나면 처음부터 다시 돌려줘야 합니다.
colab의 사용량 한도가 넘으면 사용할 수 없습니다. (물론 유료를 사용할 경우 사용량 한도를 높일 수 있습니다.) 구글에 따르면 사용량 한도는 정해져 있는게 아니고 상황에 따라 달라진다고 합니다. 그렇기 때문에 노트북을 다 사용하셨으면 탭을 닫아서 종료해 주세요.
추가 기능 (선택 사항) : 마이크로 목소리 텍스트로 변환하기
추가로 하나를 더 진행해 보도록 하겠습니다. 목소리를 마이크로 입력받아 텍스트로 변환하는 것입니다. gradio 의 웹 인터페이스로 목소리를 입력받아 whisper로 텍스트로 변환해 보겠습니다. 이 기능이 필요하지 않으시거나 마이크가 없으시다면 이 파트는 넘어가셔도 좋습니다.
우리 노트북 끝에 다음과 같이 코드를 추가합니다.
import whisper
model = whisper.load_model("base")
# 음성을 받아서 텍스트로 처리하는 함수
def transcribe(audio):
# load audio and pad/trim it to fit 30 seconds
audio = whisper.load_audio(audio)
audio = whisper.pad_or_trim(audio)
# make log-Mel spectrogram and move to the same device as the model
mel = whisper.log_mel_spectrogram(audio).to(model.device)
# detect the spoken language
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
# decode the audio
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
return result.textwhisper 모듈을 import 하고 모델을 추가했습니다. 모델은 빠른 속도를 위해 base 모델로 선택했습니다. 그리고 실제 음성을 처리하는 부분인 transcribe 함수를 정의했습니다.
다음 코드를 추가해 봅시다.
# gradio 설치 및 런칭
! pip install gradio -q
import gradio as gr
import time
gr.Interface(
title = 'OpenAI Whisper ASR Gradio Web UI',
fn=transcribe,
inputs=[
gr.Audio(source="microphone", type="filepath")
],
outputs=[
"textbox"
],
live=True).launch()두 코드를 실행을 하면 gradio의 web ui에 접속할 수 있는 링크가 나오게 됩니다. 해당 링크로 접속하면 다음과 같은 UI를 볼 수 있습니다.
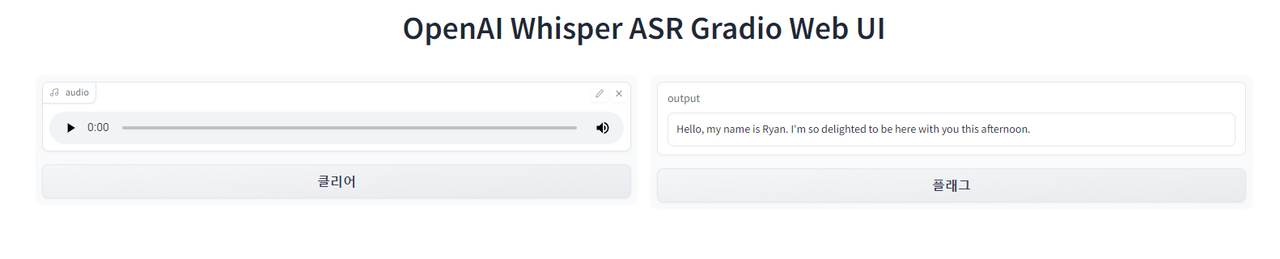
여기에서 마이크를 누르고 이야기를 하면 됩니다. 다음은 제가 영어와 한글을 받아쓰기한 내용입니다.
영어 : Hello, my name is Ryan. I'm so delighted to be here with you this afternoon.
한글 : 나는 아침에 일어난 커피를 마셨습니다
약간의 오타율은 존재합니다. 이렇게 인터페이스를 구축하면 음성으로 입력받아 ChatGPT API에게 처리를 시키는 등 다양한 기능을 구사할 수 있겠죠? 이렇게 하면 클로바 같은 받아쓰기 기능이나 음성 인터페이스를 구축하는 것도 가능해집니다.
Whisper는 정말 유용합니다.
저는 위스퍼를 동영상의 자막을 만들 때 가장 많이 사용합니다. 유튜브 영상을 만들거나 강의의 자막을 만들 때 받아쓰기 (transcript) 를 할 때 정말 좋습니다.
감사합니다.


