
랭체인/랭그래프 V1, AI 에이전트 개발의 판도가 바뀝니다: 개발자라면 반드시 알아야 할 5가지 혁신

1.0 서론: 복잡한 AI 에이전트 개발, 이제는 안녕
최근 대한민국은 자체 LLM 개발에 대한 뜨거운 관심과 기대로 가득합니다. 국가대표 AI의 등장은 분명 자랑스러운 일입니다. 하지만 우리만의 강력한 엔진(LLM)을 가졌다고 해서 모든 것이 해결될까요? 엔진만으로는 자동차를 완성할 수 없습니다. 바퀴를 달고, 핸들을 달아 멋진 자동차를 만들어내는 과정이 반드시 필요합니다.
저는 바로 이 지점에서, 우리가 ‘LLM 애플리케이션 아키텍처’라는 분야에 더 많은 관심을 가져야 한다고 열정적으로 주장하고 싶습니다. 모델 자체에만 집중하다 보면, 정작 그 모델을 활용해 실제 가치를 만들어내는 아키텍처 설계 역량을 놓칠 수 있습니다. LangChain/LangGraph V1 업데이트는 바로 이 ‘LLM 애플리케이션 아키텍처’를 고민하는 우리 개발자들에게 주어진 가장 강력한 무기입니다.
AI 에이전트를 개발하며 겪었던 예측 불가능한 동작, 컨텍스트 관리의 어려움, 끝없는 디버깅과의 싸움은 이제 과거의 이야기가 될 것입니다. 이번 업데이트는 실험적인 예술 같았던 에이전트 개발을 체계적인 공학의 영역으로 끌어올렸습니다. 본 포스트에서는 모든 AI 개발자가 반드시 알아야 할 가장 혁신적인 5가지 업데이트를 심도 있게 분석해 보겠습니다.
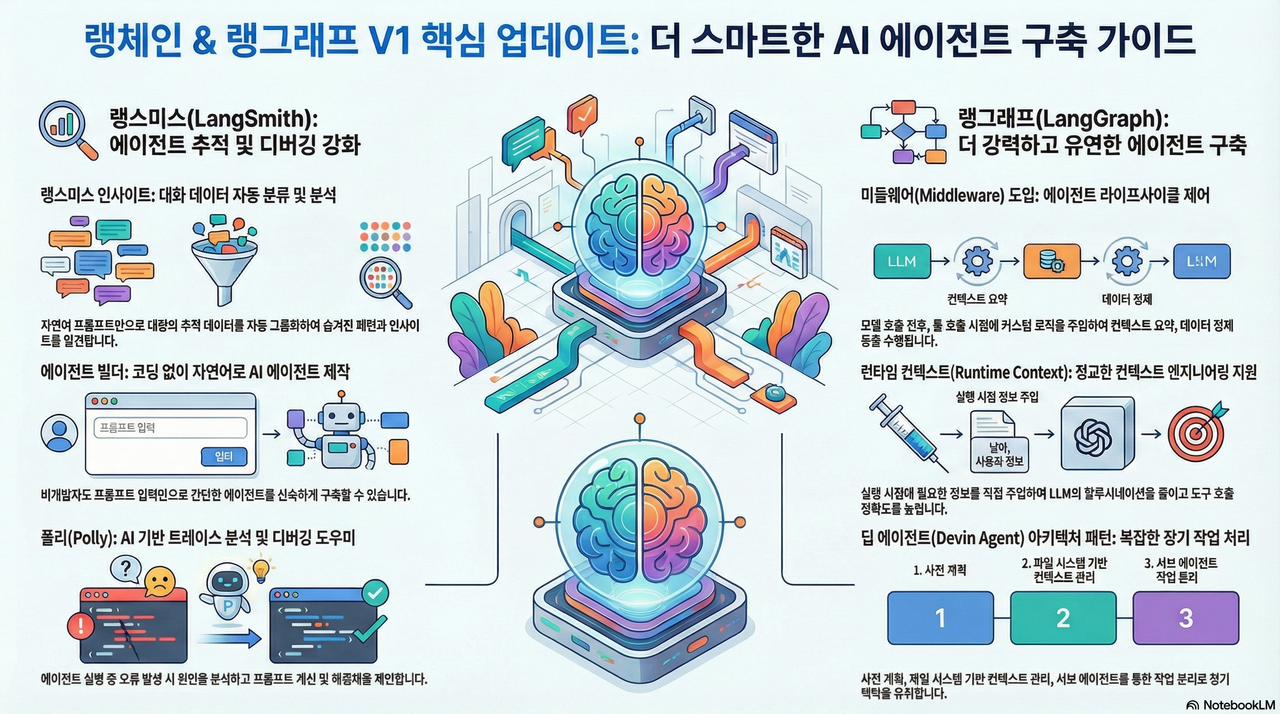
2.0 Takeaway 1: 에이전트의 '라이프사이클'을 제어하다: 혁신적인 미들웨어의 등장
LangGraph V1에서 가장 주목할 만한 기능은 단연 '미들웨어(Middleware)'입니다. 저는 과거 안드로이드 앱 개발자였는데, 그때 처음 배운 가장 중요한 개념이 바로 '앱 라이프사이클'이었습니다. 앱이 실행될 때, 백그라운드로 전환될 때, 다시 활성화될 때 등 각 시점에 맞는 로직을 실행하는 것이 핵심이었죠. 미들웨어는 바로 그 라이프사이클 개념을 AI 에이전트 세계에 도입한, 정말 참신하고 강력한 아이디어입니다.
미들웨어는 에이전트의 동작 흐름 속 특정 시점에 개발자가 원하는 로직을 주입할 수 있는 '생명주기'를 제공합니다. 주요 라이프사이클 지점은 다음과 같습니다.
• before_agent: 에이전트가 동작을 시작하기 직전
• after_model: LLM 모델이 호출된 직후
• wrap_tool_call: 에이전트가 외부 도구(Tool)를 호출하는 시점
이것이 왜 게임 체인저일까요? 미들웨어를 통해 우리는 에이전트의 핵심 구조를 건드리지 않고도 매우 구체적이고 실용적인 기능들을 깔끔하게 추가할 수 있습니다. 예를 들어,
• 쿼리 라우팅(Query Routing): 사용자의 질문을 분석해 적절한 도구나 하위 에이전트로 보내야 한다면? before_agent 훅에 로직을 추가하면 됩니다.
• 컨텍스트 요약(Context Summarization): 대화가 길어져 컨텍스트 창이 가득 차기 시작하면? after_model 훅에서 메시지 큐의 길이를 확인하고, 특정 길이를 넘으면 자동으로 요약 로직을 발동시킬 수 있습니다.
• 데이터 정제(Data Cleaning): 웹 검색 도구의 결과물에 포함된 불필요한 내비게이션 바나 광고 텍스트 같은 노이즈가 걱정되시나요? wrap_tool_call 훅에 정규표현식 필터를 추가해 모델에 깨끗한 데이터만 전달할 수 있습니다.
LangGraph는 Human-in-the-loop(사용자 개입), model fallback(모델 실패 시 대체 모델 호출) 등 강력한 미들웨어를 내장 기능으로 제공하여 개발 편의성을 극대화했습니다.
"기존에는 에이전트의 동작 중간에 무언가를 추가하려면 전체 구조를 뜯어내야 했습니다. 하지만 미들웨어는 개발자가 원하는 시점에 원하는 로직을 손쉽게 주입할 수 있는 '생명주기'를 제공합니다. 이것은 에이전트 아키텍처를 설계하는 방식을 근본적으로 바꾸는, 정말 참신하고 강력한 아이디어입니다."
3.0 Takeaway 2: 단순한 챗봇을 넘어: '딥 에이전트'로 배우는 장기 기억 아키텍처
단순한 질의응답을 넘어 복잡하고 긴 작업을 수행하는 AI 에이전트는 어떻게 만들 수 있을까요? LangGraph의 Deep Agent 패키지는 Claude Code나 Mentat과 같은 고도화된 시스템의 아키텍처를 오픈소스로 구현하며 그 해답을 제시합니다. Deep Agent는 장기 기억과 복잡한 태스크 처리를 위해 세 가지 핵심 전략을 사용합니다.
사전 계획 (Planning): 에이전트는 작업을 시작하기 전, 먼저 수행할 일의 목록(To-do list)을 생성합니다. 여기서 핵심은 이 목록을 대화 기록이 아닌 별도의 파일에 저장한다는 것입니다. 대화가 길어지면 초기의 계획이 컨텍스트 창 위로 밀려나 소실될 수 있지만, 파일로 관리하면 에이전트는 언제든 자신의 목표를 다시 확인하고 일관성 있게 작업을 수행할 수 있습니다.
컨텍스트 오프로딩 (Context Offloading): 대규모 코드베이스나 방대한 문서를 다룰 때, 모든 정보를 프롬프트에 넣는 것은 토큰 낭비이자 불가능에 가깝습니다.
Deep Agent는 파일 시스템을 활용해 컨텍스트를 관리합니다. 과정은 이렇습니다. 먼저, 에이전트는mcp.txt,agent.txt처럼 설명적인 이름의 파일 목록을 확인합니다. 그리고 정보가 필요할 때, 파일 전체를 읽는 것이 아니라 200줄과 같은 작은 덩어리(chunk) 단위로 읽기 시작합니다. 만약 첫 덩어리에서 필요한 정보를 찾으면, 나머지 부분을 읽지 않고 작업을 멈춥니다. 이로써 우리는 엄청난 양의 컨텍스트 이득, 즉 토큰 비용 절감을 얻게 됩니다.컨텍스트 격리 (Context Isolation): 메인 에이전트의 컨텍스트는 장기 작업을 위해 항상 '팩트 기반의 깨끗한(factual and clean)' 상태를 유지해야 합니다. 이를 위해
Deep Agent는 검색, 코드 분석 등 특정 작업에 특화된 하위 에이전트(Sub-agent)를 사용합니다. 메인 에이전트는 복잡한 작업을 하위 에이전트에게 위임하고, 수많은 중간 과정과 도구 호출로 지저분해진 컨텍스트는 하위 에이전트가 모두 감당합니다. 그리고 오직 최종 결과, 즉 '알짜배기' 정보만 간결하게 보고받습니다. 이것이 바로 장기 기억과 지속적인 성능을 유지하는 비결입니다.
Deep Agent는 단일 작업을 넘어 여러 단계에 걸친 장기 프로젝트를 수행할 수 있는 정교한 AI 어시스턴트를 구축하기 위한 구체적인 청사진을 제공한다는 점에서 매우 중요한 시사점을 가집니다.
4.0 Takeaway 3: 자연어로 만들고 AI로 디버깅한다: LangSmith 에이전트 빌더와 Polly
LangChain 생태계의 모니터링 및 디버깅 도구인 LangSmith 역시 획기적인 기능들로 개발 경험을 한 단계 끌어올렸습니다.
먼저, LangSmith 에이전트 빌더(Agent Builder)입니다. LangChain의 CEO 해리슨 체이스는 Mpal이나 Dify 같은 도구들을 복잡한 로직 구현이 가능한 강력한 '워크플로우 빌더'로 정의했지만, 동시에 진입 장벽이 높다는 점을 지적했습니다. LangSmith 에이전트 빌더는 이와 다른 방향을 지향합니다. 바로 비개발자를 포함한 누구나, 오직 자연어 설명만으로 에이전트를 만들 수 있도록 극도로 낮은 진입 장벽을 제공하는 것입니다. "웹 검색을 수행하는 에이전트를 만들어 줘"라고 입력하기만 하면 필요한 도구와 프롬프트를 자동으로 구성해 줍니다.
다음으로, 정말 너무나도 사랑스러운 존재, Polly를 소개합니다. Polly는 LangSmith 내부에 탑재된 AI 어시스턴트, 즉 '디버깅을 위한 코파일럿'입니다. 에이전트 실행 중 오류가 발생하면, 더 이상 복잡한 추적(trace) 기록을 일일이 들여다볼 필요가 없습니다. Polly에게 "오류가 왜 났는지 분석해 줘"라고 물어보기만 하면, Polly가 전체 추적 기록을 분석해 "어디가 왜 잘못되었고, 어떻게 수정해야 하는지"를 정확히 알려줍니다. 심지어 더 나은 결과를 위해 프롬프트를 개선해 달라고 요청할 수도 있습니다.
자연어 기반의 에이전트 생성과 AI 기반의 디버깅 지원이 결합되면서, 개발자들은 아이디어를 프로토타입으로 만들고 문제를 해결하는 반복(iteration) 주기를 극적으로 단축시킬 수 있게 되었습니다.
5.0 Takeaway 4: 골치 아픈 입출력 문제의 종결자: 정형화된 출력과 런타임 컨텍스트
에이전트 개발에서 가장 빈번하게 발생하는 오류 중 하나는 LLM의 입출력(I/O)을 안정적으로 제어하지 못하는 것입니다. LangGraph V1은 이 문제를 해결하기 위한 두 가지 강력한 기능을 기본으로 탑재했습니다.
정형화된 출력 (Structured Output): 이제 복잡한 출력 파서(Output Parser) 없이도 안정적인 JSON 형식의 출력을 얻을 수 있습니다. Pydantic 모델로 원하는 출력 스키마를 정의하고 이를 지정하기만 하면, 에이전트는 항상 약속된 형식에 맞춰 결과를 반환합니다. 이는 후속 자동화 시스템과의 연동을 매우 안정적이고 편리하게 만들어 줍니다.
런타임 컨텍스트 (Runtime Context): 이 기능은 LLM의 파라미터 생성 단계를 건너뛰고 특정 정보를 도구(Tool)에 직접 주입하는 아주 영리한 방법입니다. 예를 들어, 특정 도구를 호출할 때 사용자 ID가 필요하다고 가정해 봅시다. 기존 방식에서는 LLM이 이 ID를 직접 생성해서 파라미터로 넘겨야 했고, 이 과정에서 형식 오류나 환각(hallucination)이 발생할 수 있었습니다. 하지만 런타임 컨텍스트를 사용하면, 개발자가 이 사용자 ID를 런타임에 직접 도구로 '주입(injection)'할 수 있습니다. LLM의 파라미터 생성 과정 자체가 생략되므로 오류 가능성이 원천적으로 차단되고 토큰 비용까지 절약할 수 있습니다.
이 두 기능은 전통적으로 에이전트의 불안정성을 야기했던 입출력 문제를 해결하여 시스템 전체의 신뢰성과 예측 가능성을 크게 향상시킵니다.
6.0 Takeaway 5: 로그가 스스로를 분석한다: LangSmith 인사이트
프로덕션 환경에서 운영되는 사내 챗봇이 있다고 상상해 봅시다. 이 챗봇은 '내부 문서 검색'과 '이메일 자동화' 두 가지 기능을 제공하며, 하루에도 수천 개의 대화 로그가 뒤섞여 쌓입니다. 여기서 실패 패턴을 분석하려면 어떻게 해야 할까요? 기존에는 모든 로그를 엑셀로 내려받아 "한 땀 한 땀" 수작업으로 태그를 달아야 하는 고된 작업이었습니다.
LangSmith 인사이트(Insights)는 바로 이 문제를 해결하기 위해 등장했습니다. 개발자가 "사용자 의도에 따라 대화를 그룹화해 줘"와 같이 분석하고 싶은 내용을 자연어로 설명하기만 하면, LangSmith 인사이트는 LLM을 활용해 전체 추적(trace) 데이터를 자동으로 분류하고 요약해 줍니다.
이 기능은 지루한 수동 로그 분석을 자동화된 데이터 분석 프로세스로 전환시킵니다. 이를 통해 개발팀은 시스템의 실패 패턴을 신속하게 파악하거나, 사용자들이 에이전트를 어떻게 활용하고 있는지에 대한 고수준의 통찰력을 손쉽게 얻을 수 있습니다.
7.0 결론: 에이전트 개발, 이제 '공학'의 영역으로
LangChain/LangGraph V1 업데이트가 시사하는 바는 명확합니다. AI 에이전트 개발이 실험적인 '예술'의 단계를 지나 체계적인 '공학'의 영역으로 성숙하고 있다는 것입니다. 미들웨어를 통한 구조적 설계, Deep Agent를 통한 장기 기억 아키텍처, 그리고 LangSmith를 통한 효율적인 개발 및 운영 환경은 모두 우리가 LLM 자체뿐만 아니라, 이를 둘러싼 'LLM 애플리케이션 아키텍처'에 집중해야 한다는 사실을 다시 한번 일깨워 줍니다.
이처럼 강력하고 체계적인 도구들을 손에 쥔 지금, 우리는 어떤 새로운 차원의 AI 에이전트를 상상하고 만들어낼 수 있을까요?