제미나이 2.5(Gemini 2.5)가 가져온 오디오 혁명: 단순히 읽는 AI에서, 연기하고 소통하는 AI로


2025년 12월, 구글이 내놓은 Gemini 2.5 업데이트는 단순히 텍스트를 더 잘 써주는 차원을 넘어섰습니다. 이번 변화의 핵심은 '소리'입니다. 지금까지의 TTS(Text-to-Speech)가 입력된 글자를 소리로 바꾸는 '기계적 낭독'에 그쳤다면, Gemini 2.5는 글의 맥락을 이해하고 감정을 실어 '연기'하는 단계로 진입했습니다.
이 글에서는 Gemini 2.5의 오디오 기술이 어떻게 바뀌었는지, Flash와 Pro 모델은 어떤 차이가 있는지, 그리고 개발자와 기업이 이 기술을 실무에 어떻게 적용해야 할지 아주 상세하게 뜯어보겠습니다.
1. 더 이상 '로봇 말투'는 없다: 3가지 핵심 변화
Gemini 2.5 TTS가 기존 기술과 가장 다른 점은 거대 언어 모델(LLM)의 '지능'을 목소리에 입혔다는 것입니다. 글의 의미를 먼저 파악하고 소리를 만들기 때문에 다음과 같은 놀라운 변화가 가능했습니다.
① 섬세해진 감정 표현 (Expressivity) 예전 TTS는 슬픈 뉴스나 기쁜 소식이나 똑같은 톤으로 읽었습니다. 하지만 Gemini 2.5는 다릅니다. 단순히 '기쁘게', '슬프게' 정도가 아닙니다.
디테일한 연기: sarcastic, whispering, scornful 같은 구체적인 지시를 소화합니다. 가상 비서가 내 실수에 가볍게 농담을 던지거나, 오디오북 성우가 긴박한 장면에서 숨죽여 말하는 상황을 완벽하게 재현합니다.
시간에 따른 변화: "처음엔 명랑하다가 점점 심각해지게 말해줘" 같은 복합적인 주문도 가능합니다. 문맥에 맞춰 호흡과 톤을 스스로 조절하기 때문이죠.
② 알아서 조절하는 말하기 속도 (Precision Pacing) 사람은 중요한 정보를 말할 땐 천천히, 가벼운 농담은 빠르게 말합니다. Gemini 2.5는 이 인간적인 특징을 그대로 따라 합니다.
어려운 기술 용어를 설명할 땐 속도를 늦춰 청자가 이해할 시간을 줍니다.
긴박한 액션 장면 묘사는 빠르게 몰아칩니다.
별도의 복잡한 코드를 넣지 않아도, AI가 문맥을 파악해 알아서 속도를 조절합니다.
③ 여러명이 함께 이야기 하기 (Multi-Speaker) 텍스트 하나에 여러 등장인물이 나와도 문제없습니다. 각 캐릭터의 성격과 목소리 톤을 유지하며 자연스럽게 대화를 주고받습니다.
글로벌 정체성 유지: 가장 놀라운 점은 언어가 바뀌어도 캐릭터가 유지된다는 겁니다. '냉소적인 영국 탐정' 캐릭터를 만들면, 그가 스페인어로 말하든 한국어로 말하든 그 특유의 까칠한 목소리 톤은 그대로 유지됩니다. 글로벌 콘텐츠를 만들 때 성우 캐스팅 비용을 획기적으로 줄일 수 있는 기능입니다.
2. Flash vs Pro: 어떤 모델을 골라야 할까?
구글은 용도에 따라 두 가지 모델을 내놓았습니다. 속도가 중요한지, 깊이가 중요한지에 따라 선택하면 됩니다.
| 비교 항목 | Gemini 2.5 Flash TTS | Gemini 2.5 Pro TTS |
|---|---|---|
| 핵심 설계 철학 | 저지연(Low Latency), 비용 효율성, 속도 최적화 | 심층 추론(Deep Reasoning), 고품질, 복합적 맥락 이해 |
| 처리 속도 | 첫 토큰 생성까지 0.21~0.37초 소요 (초당 약 163 토큰 처리) | Flash 대비 느림; 'Deep Think' 모드 활성화 시 사고 과정 포함 |
| 추론 능력 | 표준적인 추론 및 즉각적 반응에 최적화 | 복잡한 지시사항 수행, 구조화된 출력, 논리적 사고 우수 |
| 입력비용(텍스트) | 100만 토큰당 $0.50 | 100만 토큰당 $1.00 |
| 출력비용(오디오) | 100만 오디오 토큰당 $10.00 | 100만 오디오 토큰당 $20.00 |
| 추천 활용 분야 | 실시간 음성 비서, 대규모 IVR 시스템, 단순 낭독 | 오디오북, 학습용 콘텐츠, 복잡한 감정 연기가 필요한 시나리오 |
Flash 모델: 속도가 생명인 실시간 서비스에 적합합니다. 0.2초대의 반응 속도는 사람과 대화하는 듯한 느낌을 줍니다. 비용도 Pro의 절반이라 대규모 트래픽 처리에 유리합니다.
Pro 모델: 'Deep Think' 모드가 핵심입니다. 말하기 전에 텍스트의 숨은 의도와 감정선을 깊게 고민합니다. 소설 속 인물의 미묘한 심리를 떨리는 목소리로 표현해야 한다면 Pro가 정답입니다.
3. 듣고 말하는 방식의 진화: 네이티브 오디오 (Native Audio)
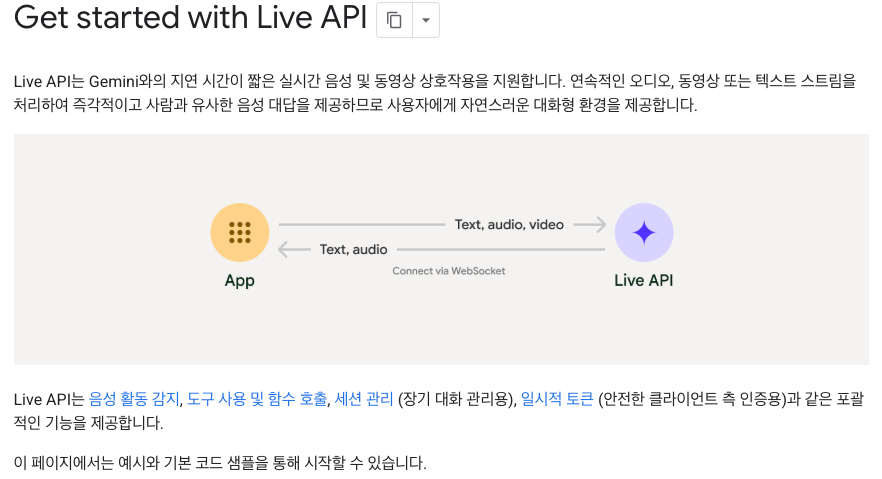
기존 API가 텍스트를 주면 오디오를 뱉는 일방통행이었다면, 라이브 API(Live API)를 이용한 네이티브 오디오는 진짜 '대화'를 가능하게 합니다.
소리를 직접 이해: 사용자의 말을 텍스트로 변환(STT)해서 이해하는 게 아니라, 목소리의 톤, 리듬, 배경 소음까지 직접 듣고 이해합니다. 그래서 말하는 사람이 진짜 말을 끝낸 건지, 아니면 생각하느라 잠깐 멈춘 건지 기가 막히게 알아챕니다.
자연스러운 끼어들기 (Barge-in): 우리가 대화할 때 상대방 말을 끊고 들어가는 것처럼, 사용자가 말을 시작하면 AI가 즉시 말을 멈추고 듣습니다.
도구 사용 (Function Calling): 대화 도중에 항공편을 예약하거나 일정을 확인하는 작업도 매끄럽게 수행합니다. 대화의 맥락을 놓치지 않으면서요.
4. 돈이 될까? 비용과 투자 대비 효과 (ROI)
비용 구조 이해하기 (오디오 토큰) 구글은 '오디오 토큰'이라는 단위를 씁니다. 1초에 약 25 토큰이 듭니다.
10분짜리 팟캐스트(약 1,500 단어)를 만든다면?
Flash: 약 $0.15 (약 200원)
Pro: 약 $0.30 (약 400원)
생각보다 매우 저렴합니다. 하지만 Pro 모델은 말하기 전에 '생각하는 과정'에서도 토큰을 쓰기 때문에, 복잡한 연기를 시키면 비용이 좀 더 나올 수 있습니다.
산업별 효과
고객 상담(CX): 기계적인 ARS 대신 "많이 불편하셨죠?"라고 공감해주는 AI 상담원은 고객 이탈을 막습니다. 실제로 단순 문의 방어율이 높아져 운영 비용이 크게 줄어듭니다.
교육/접근성: 어려운 교과서 내용을 쉽게 풀어서, 친절한 선생님 목소리로 읽어주는 '이지 리드(Easy Read)' 콘텐츠를 자동으로 만들 수 있습니다. 시각 장애인을 위해 복잡한 차트를 말로 풀어서 설명해주기도 합니다.
5. 바로 써보기: 프롬프트와 코드 예시
1. 제미나이 TTS 섹션 접속 및 기본 설정
이미지 우측 하단의 'Turn text into audio with Gemini' 버튼을 클릭하면 음성 생성 전용 인터페이스로 이동합니다.
모델 선택: 현재 화면에 강조된 Gemini 3 Flash 또는 기존의 Gemini 2.5 Pro/Flash TTS 모델 중 하나를 선택할 수 있습니다. 고품질과 복잡한 감정 표현이 필요하다면 Pro 모델을, 빠른 속도와 효율성이 중요하다면 Flash 모델을 권장합니다.
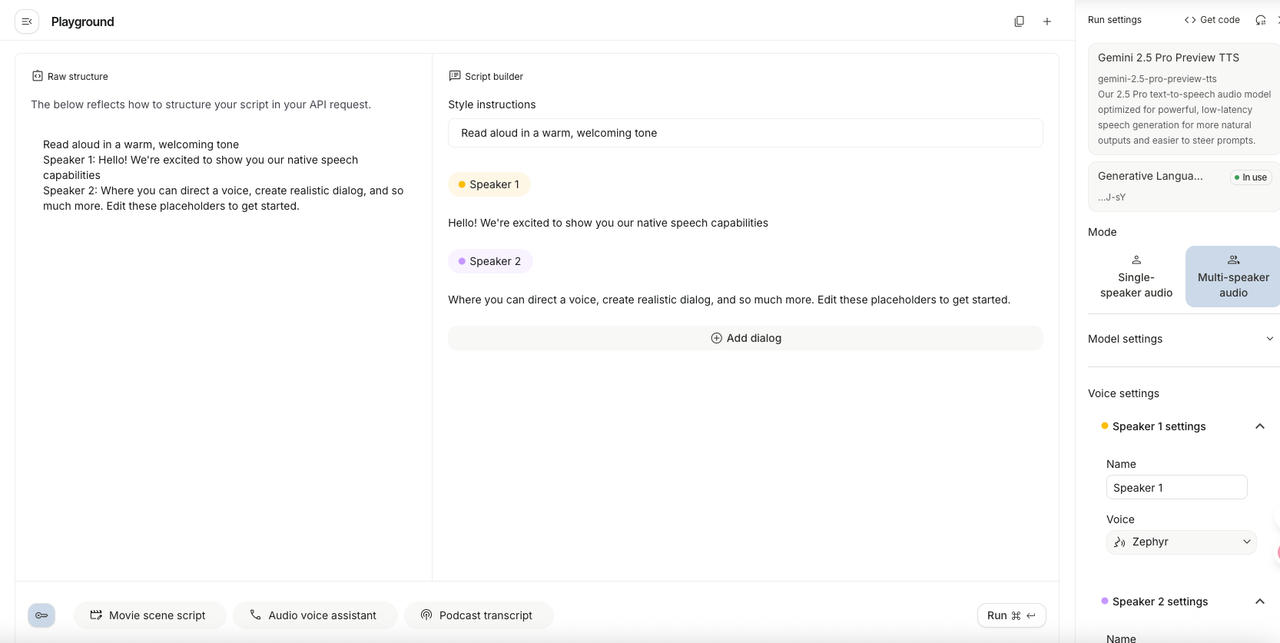
음성(Voice) 선택: 'Kore', 'Alnilam', 'Enceladus' 등 구글이 제공하는 30여 가지 이상의 자연스러운 목소리 중 하나를 선택합니다.
2. 주요 기능 및 사용 팁
제미나이 TTS는 기존 방식과 달리 자연어 지시(Natural Language Prompting)를 통해 목소리의 연기를 조절할 수 있는 것이 가장 큰 특징입니다.
감정 및 스타일 제어: 텍스트 입력창에 단순히 읽을 내용만 쓰는 것이 아니라, 말투에 대한 지시를 함께 입력할 수 있습니다.
예시:
[extremely fast](아주 빠르게),[whispering](속삭이듯), "슬픈 목소리로 읽어줘" 등.다중 화자(Multi-Speaker) 설정: 두 명 이상의 목소리가 필요한 경우(예: 팟캐스트, 대화문), 설정에서 'Multi-speaker'를 선택하고 각 인물에게 서로 다른 음성을 배정할 수 있습니다.
파라미터 조정: 텍스트의 온도(Temperature) 값을 조절하여 음성의 창의성이나 일관성을 제어할 수 있습니다.
3. 생성 및 결과 활용
실시간 미리보기: 텍스트를 입력하고 'Run' 버튼을 누르면 즉시 음성이 생성됩니다. 재생 버튼을 눌러 결과물을 바로 확인할 수 있습니다.
파일 다운로드: 생성된 음성이 만족스럽다면
.wav형식의 고음질 파일로 내보내어 영상 편집이나 프레젠테이션에 바로 활용할 수 있습니다.
2. 실제 테스트(아주 어려운 상황)
[프롬프트 구성: 긴박한 데이터 센터 복구 시나리오]

스타일 지시어: "처음에는 차분하고 전문적인 분석가의 톤으로 시작해. 하지만 상황이 급박해짐에 따라 목소리에 불안함과 속도감을 더해줘. 중간에 나오는 영어 전문 용어는 한국어 문맥 속에서 아주 유창하게 발음하고, 마지막에는 모든 것이 해결된 듯한 깊은 안도의 한숨과 함께 속삭이듯 마무리해줘."
[전체 텍스트]
"현재 시각 03시 42분, 메인 서버 룸의 온도가 비정상적으로 상승하고 있습니다. [calm and professional] 시스템 로그 확인 결과, 리퀴드 쿨링 시스템(Liquid Cooling System)에 심각한 리크(Leak)가 발생한 것으로 보입니다.
[getting faster and anxious] 잠깐, 이게 뭐지? 데이터 커럽션(Data Corruption)이 시작됐잖아! 안 돼, 이대로라면 백업 클러스터까지 전부 무너질 거야. 빨리, [rapidly] 'Override critical thermal protocol' 명령어를 실행해! 쿼리(Query) 실행 속도가 너무 느려... 제발, 조금만 더...!
[long pause - 2 seconds]
[relieved and slow] ...후우. 다행이다. 세이프 모드(Safe Mode) 진입 성공. [whispering] 정말 한 끗 차이였어. 이제 시스템 복구 프로세스를 시작하자. 고생했어, 모두들."
실제 결과 확인 - 꼭 한번 들어보세요
마치며: 에이전트(Agent) 시대의 개막
Gemini 2.5는 AI가 텍스트를 읽어주는 기계에서, 생각하고 느끼며 대화하는 존재(Agent)로 진화했음을 보여줍니다.
불쾌한 골짜기를 넘어선 자연스러운 목소리, 상황에 맞는 속도 조절, 그리고 누구나 쉽게 개발할 수 있는 환경까지. 다가올 Gemini 3.0 시대에는 비디오와 오디오가 완벽하게 결합된 더 놀라운 경험이 기다리고 있을 것입니다. 지금 바로 여러분의 서비스에 이 '새로운 목소리'를 입혀보세요. 고객 경험의 차원이 달라질 것입니다.