
AI 시대 문서 작성법: 기계 가독성 높이는 워드·한글 최적화 전략


서문: 읽는 존재의 변화와 문서의 본질적 위기
인류 역사상 문서는 지식을 보존하고 '인간'에게 전달하는 수단이었습니다. 보기 좋은 편집, 현란한 도표, 함축적인 개조식 문장은 인간의 인지 부하를 줄이기 위한 장치였죠. 하지만 생성형 AI(Generative AI)와 거대언어모델(LLM)의 등장으로 문서의 독자층에 지각 변동이 일어났습니다.
이제 문서는 인간뿐만 아니라 AI가 읽고, 해석하고, 처리해야 하는 '데이터 소스(Data Source)'가 되었습니다. 특히 기업과 공공기관에서 검색 증강 생성(RAG, Retrieval-Augmented Generation) 시스템 도입이 가속화되면서, 기존의 '인간 친화적 문서'가 AI에게는 해독 불가능한 '노이즈(Noise)' 덩어리로 전락하고 있습니다. 텍스트 상자, 복잡한 표, 한국어 특유의 고맥락 화법은 AI의 환각(Hallucination)을 유발하는 주범입니다.
이 글에서는 개발자 중심의 급진적 포맷 변경 대신, 우리가 사용하는 MS Word와 한글(HWP)을 유지하면서도 '기계 가독성(Machine Readability)'을 극대화하는 현실적인 전략을 심층 분석합니다.
1. 인공지능의 독해법: RAG 시스템과 문서 구조의 공학적 이해
AI 친화적인 문서를 작성하기 위해서는 AI가 문서를 인식하는 메커니즘을 이해해야 합니다. LLM은 문서를 시각적 이미지가 아닌, 토큰(Token)으로 분해하고 벡터(Vector)로 변환하여 처리합니다.
1.1 RAG 파이프라인과 문서 전처리의 결정적 역할
RAG 시스템의 핵심은 인덱싱(Indexing) 단계에서의 파싱(Parsing)과 청킹(Chunking)입니다.
문서 파싱(Parsing): 시각 정보를 텍스트로 변환하는 과정입니다. 인간에게는 크고 굵은 글씨가 '제목'이지만, 구조 정보(태그)가 없다면 파서에게는 그저 폰트 속성이 다른 문자열일 뿐입니다.
만약 문서가 논리적 구조를 갖추고 있지 않다면, 파서는 이를 단순한 문자열의 나열로 인식하게 됩니다. 논리적 구조(제목, 헤더, 목록 태그 등)가 명확히 파싱 가능한 포맷(Markdown, HTML, 잘 구조화된 Docx)이 비정형적인 PDF나 이미지 기반 문서보다 훨씬 높은 품질의 결과값을 보여줄 수 있습니다.
청킹(Chunking)과 문맥 보존: 추출된 텍스트는 LLM의 입력 제한(Context Window)을 맞추기 위해 작은 조각(Chunk)으로 나뉘어 저장됩니다. 이때 문서의 '구조'가 결정적인 역할을 합니다.
단순히 500자나 1000자 단위로 자르는 '고정 크기 청킹(Fixed-size Chunking)'은 문맥을 파괴할 위험이 큽니다. 예를 들어, "다음 표는 2024년도 예산안이다"라는 문장이 표 데이터와 서로 다른 청크로 분리되면, AI는 표의 내용을 이해할 수 있어도 그것이 2024년 예산안이라는 사실은 알 수 없게 됩니다.
따라서 문서는 AI가 이해하기 쉽게 명확히 구분되어야 합니다. 섹션, 챕터, 문단이 논리적으로 구분되어 있다면, AI는 이를 기준으로 문서를 자를 수 있습니다.
"제목 1 > 제목 2 > 본문"으로 이어지는 위계 구조는 RAG 시스템이 문서 전체에서 어떤 위치를 차지하고 있는지 파악하게 해주는 메타데이터 역할을 수행합니다.
1.2 시각적 구조 vs 의미론적 구조
문서 작성자들이 가장 흔히 범하는 오해는 "보기 좋은 문서가 잘 정리된 문서"라는 믿음입니다. 그러나 인간을 위한 시각적 구조와 AI를 위한 보기 좋은 문서를 서로 다를 수 있습니다.
시각적 구조(Visual): 인간의 가독성을 위해 존재합니다. 빈 줄(Enter)을 여러 번 넣어 문단 간격을 띄우거나, 스페이스바(Space bar)를 연타하여 들여쓰기를 맞추고, 표를 이용해 텍스트 배치를 조절하는 행위가 이에 해당합니다.
이러한 시각적 장치들은 파싱 과정에서 무의미한 공백 문자(Whitespace)나 불필요한 태그로 변환되어, AI에게는 문맥을 끊어먹거나 혼란을 주는 '노이즈'로 작용합니다.
의미론적 구조(Semantic): 데이터의 위계와 관계를 정의합니다. 워드프로세서의 '제목 1', '제목 2'와 같은 스타일 기능을 사용하여 이 텍스트가 제목임을 명시하고, 글머리 기호(Bullet points) 기능을 사용하여 이것이 목록임을 태그로 남기는 방식입니다.
웹의 표준 언어인 HTML이 기계 가독성이 높은 이유는 <h1>, <p>, <ul>, <table>과 같은 태그를 통해 각 텍스트가 '무엇'인지를 명시하기 때문입니다. AI 가독성을 높이는 핵심 전략은, 우리가 사용하는 워드프로세서 문서를 마치 웹페이지(HTML)처럼 구조화하여 작성하는 것이다.
2. 한국의 문서 작성 관행 진단: 화려함 속에 감춰진 데이터의 단절
한국의 공공기관과 기업 문서는 세계적으로 유례를 찾기 힘들 정도로 독특한 발전 양상을 보여왔습니다. 이는 빠른 의사결정과 압축적 성장을 뒷받침해 온 효율적인 도구였으나, AI 도입 시점에서는 심각한 장벽으로 작용하고 있습니다.
2.1 HWP의 폐쇄성과 프레젠테이션 도구화
프레젠테이션 도구화된 워드프로세서:한국의 HWP 보고서는 워드프로세서라기보다 파워포인트 슬라이드에 가깝습니다.
A4 용지 한 장에 모든 정보를 밀어 넣기 위해, 문장 중간에 그림을 배치하거나, 투명 선을 가진 표를 활용해 복잡한 다단 구성을 만들고 있습니다. 이는 텍스트 추출 시 읽는 순서(Reading Order)를 교란시킵니다.
인간의 눈은 왼쪽에서 오른쪽으로, 위에서 아래로 레이아웃을 건너뛰며 읽을 수 있지만, 인공지능은 코드에 기록된 순서대로 텍스트를 읽습니다. 복잡한 레이아웃은 문장을 엉뚱한 순서로 조합하게 만들어 AI의 이해를 불가능하게 합니다.
텍스트 상자(Text Box)의 남용: 강조를 위해 본문 흐름과 별개로 배치된 글상자는 인공지능이 아예 인식하지 못하거나, 문서의 맨 마지막에 몰아서 추출하는 경우가 있을 수 있습니다.
예를 들어, 본문 중간에 "결론: 승인 필요"라는 텍스트 상자가 있다면, 파서는 문서 전체를 다 읽은 뒤에야 뜬금없이 "결론: 승인 필요"라는 문장을 뱉어낼 수 있습니다.
2.2 '개조식' 문체와 고맥락 문화의 충돌
"AI 도입 추진 필요."와 같이 주어를 생략하고 명사형으로 끝맺는 개조식 문체는 인간에게는 효율적이지만, AI에게는 치명적입니다. 한국어는 주어 생략이 빈번한 언어(Pro-drop language)인데, 문맥을 모르는 AI는 "동 건에 대하여"가 무엇을 지칭하는지 알 수 없어 인공지능이 맥락을 이해하는데 어려움을 줄 수 있습니다.
2.3 표(Table)에 대한 과도한 의존
한국 문서는 줄글로 풀어 써야 할 서사적 내용조차 표 안에 가두는 경향이 있습니다. '현황', '문제점', '대책'을 2x2 표에 넣고 정리하는 방식은 시각적으로 깔끔하지만, 데이터 구조적으로는 재앙에 가깝습니다.
3. 도구별 개선 전략 I: 마이크로소프트 워드(MS Word)
전 세계 표준인 MS Word는 이미 AI가 아주 좋아하는 구조(XML)로 만들어져 있습니다. 문제는 우리가 그 기능을 제대로 쓰지 않고, 그저 '종이에 출력될 모양'만 신경 쓴다는 점입니다. 워드 문서를 AI가 100% 이해할 수 있게 만드는 구체적이고 쉬운 방법을 소개합니다.
3.1 스타일(Styles) 기능 활용
많은 분들이 제목을 쓸 때, 글자를 드래그해서 [진하게] 누르고 글자 크기를 [20pt]로 키웁니다. 사람 눈에는 분명히 제목처럼 보이죠. 하지만 AI에게는 그저 '덩치만 큰 일반 텍스트'일 뿐입니다.
AI가 이것을 진짜 제목으로 인식하게 하려면, 상단 메뉴에 있는 '제목 1(Heading 1)', '제목 2' 스타일 버튼을 눌러야 합니다.
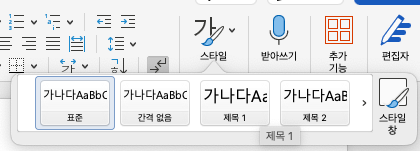
왜 이렇게 해야 할까요? 스타일 버튼을 누르는 순간, 워드 프로그램은 그 텍스트 뒤에 보이지 않는 '이름표(Tag)'를 붙입니다. <이것은 대제목입니다>라고 말이죠.
AI의 반응: AI는 문서를 읽을 때 이 이름표를 기준으로 내용을 파악합니다.
"아, 여기서부터 여기까지가 '제목 1'에 해당하는 내용이구나. 그럼 이 덩어리(Chunk)를 통째로 기억해야지!"
라고 판단합니다. 스타일을 쓰지 않으면 AI는 어디서 끊어 읽어야 할지 몰라 내용을 뒤죽박죽으로 섞어버릴 수 있습니다.
3.2 탐색 창(Navigation Pane): AI가 보는 '뼈대' 확인하기
문서를 작성하면서 수시로 [보기] 탭에서 [탐색 창] 체크박스를 켜보세요. 화면 왼쪽에 목차가 나타납니다.
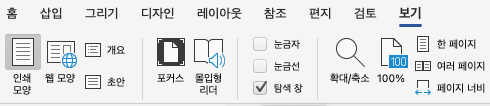
이것이 왜 중요할까요? 탐색 창에 나타나는 목차가 바로 AI가 인식하는 문서의 뼈대(Skeleton)입니다.
자가 진단법: 탐색 창을 켰는데 아무런 목차도 안 뜨고 텅 비어 있나요? 그렇다면 당신의 문서는 겉보기에 아무리 화려해도, AI에게는 구조가 없는 거대한 글자 덩어리일 뿐입니다. 제목 스타일을 제대로 적용했다면, 탐색 창에 문서의 목차가 계층별로 예쁘게 정리되어 보일 것입니다.
3.3 부유 객체 제거: 그림과 표를 '글자'처럼 취급하세요
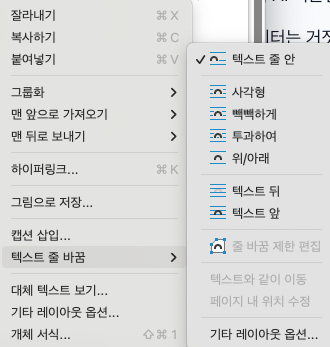
워드에서 그림이나 표를 넣을 때, 자유롭게 배치하려고 '텍스트 앞'이나 '텍스트 뒤'로 설정해서 마우스로 이리저리 옮기곤 합니다. 이것을 '부유 객체(둥둥 떠다니는 객체)'라고 하는데, AI에게는 치명적입니다.
AI의 시선: 사람은 페이지 전체를 그림처럼 보지만, AI는 코드로 된 줄을 한 줄 한 줄 읽어 내려갑니다. 둥둥 떠 있는 그림이나 표는 코드 상에서 문서의 맨 마지막에 처박혀 있거나, 엉뚱한 문장 사이에 끼어 있는 경우가 많습니다.
해결책: 이미지나 표를 우클릭해서 배치 옵션을 텍스트 줄 바꿈 - [텍스트 줄 안(In Line with Text)]으로 설정하세요. 이렇게 하면 그림도 하나의 거대한 '글자' 취급을 받아서, 문장 흐름 속에 순서대로(선형적으로) 박히게 됩니다. 그래야 AI가 글을 읽다가 "아, 여기에 그림이 있구나" 하고 순서대로 이해* 수 있습니다.
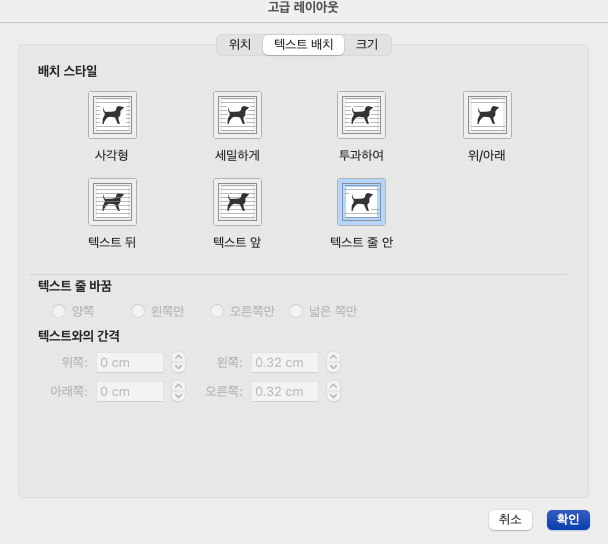
3.4 숨겨진 정보 채우기: 차트에 '말풍선' 달아주기
멋진 꺾은선 그래프 하나가 백 마디 말보다 낫다고 하죠? 하지만 AI에게 차트는 그저 '수천 개의 색깔 점(픽셀) 집합'일 수 있습니다.
대체 텍스트(Alt Text) 활용: 이미지나 차트를 우클릭하고 표속성 안의 [대체 텍스트 편집]을 눌러보세요. 여기에 이 차트가 무슨 내용인지 글로 적어주는 것입니다.
나쁜 예: "매출 그래프" (너무 단순함)
좋은 예: "2024년 상반기 매출이 전년 대비 20% 상승하여 50억 원을 기록함을 보여주는 꺾은선 그래프."
효과: 요즘 AI는 이미지를 볼 수 있지만(멀티모달), 이렇게 텍스트로 '정답'을 몰래 적어주면(힌트 제공), 표나 그래프를 잘못 해석하는 실수(환각)가 거의 사라집니다.
4. 도구별 개선 전략 II: 한글(HWP) 문서
HWP는 독자적인 형식으로 인해 오랫동안 AI 활용의 불모지로 여겨졌습니다. 그러나 최근의 포맷 개방과 기술적 진보, 그리고 우회 전략을 통해 HWP 문서 역시 AI 친화적인 자산으로 탈바꿈할 수 있습니다.
4.1 HWPX 포맷으로의 전면 전환
공공기관과 기업은 기본 저장 포맷을 .hwp에서 개방형 포맷인 .hwpx로 변경해야 합니다. HWPX는 XML 구조를 따르기 때문에 텍스트 및 구조 추출이 훨씬 용이합니다.
4.2 개요 및 스타일 기능 활용
Word와 마찬가지로 한글에서도 '모양 > 스타일(단축키 F6)' 기능을 철저히 사용해야 합니다. 많은 사용자들이 글자 모양(Alt+L)과 문단 모양(Alt+T)으로만 문서를 꾸미지만, 이는 AI에게 아무런 구조 정보를 주지 않습니다.
개요 번호(Outline Numbering)의 사용: 단순히 키보드로 '1.', '가.'를 타이핑하는 것이 아니라, 문단 번호/개요 번호 기능을 사용해 자동 넘버링을 해야 합니다. 이렇게 하면 RAG 시스템이 문서를 마크다운 리스트 포맷으로 변환할 때 결정적인 역할을 할 수 있습니다.
4.3 표(Table) 속성 정의와 레이아웃 표 지양
레이아웃을 잡기 위한 투명 표 사용을 지양하고, 표를 사용할 때는 속성에서 '제목 줄(Header Row)'을 반드시 지정해야 합니다. 페이지가 넘어가도 헤더가 반복되도록 설정해야 AI가 긴 표를 처리할 때 데이터의 열(Column) 의미를 놓치지 않습니다.
5. 콘텐츠 작성 전략: AI가 이해하기 쉬운 언어
5.1 원자적(Atomic) 단위와 두괄식 구성
자기 완결적(Self-contained) 서술: "앞서 언급한 바와 같이" 또는 "다음 표에서"와 같은 상대적 지시어 사용을 최소화해야 합니다. '앞서' 언급한 내용이 검색 결과에 포함되지 않을 수 있기 때문입니다. 되도록 문맥을 반복해서 명시해주는 것이 좋습니다. 예를 들어 "앞서 언급한 서버 문제" 대신, "섹션 2에서 다룬 서버 과부하 문제"라고 명확히 재서술해야 합니다.
두괄식 구성(Inverted Pyramid): 핵심 내용은 문단이나 섹션의 첫 문장에 명확히 제시해야 합니다. 많은 인공지능에서 문단의 앞부분에 더 높은 가중치를 두는 경향이 있으며, LLM 역시 긴 컨텍스트의 앞부분과 뒷부분을 더 잘 기억하는 특성(Lost in the Middle Phenomenon)이 있기 때문입니다.
5.2 주어 복원 (Zero Anaphora Resolution)
한국어는 문맥상 알 수 있다면 주어를 과감히 생략하는 '고맥락(High-context)' 언어입니다. "검토 바람"이라고 썼을 때, 인간은 누가 무엇을 검토하라는 것인지 알지만, AI는 모를 수 있습니다.
명시적 주어 사용 (Subject Restoration): 문장이 길어지더라도 주어를 명시해야 합니다. "승인하였음"이라고 쓰는 대신 "홍길동 팀장이 2024년 1분기 마케팅 예산안을 승인하였음"으로 구체적으로 작성해야 합니다. 그래야 AI가 주체(Entity)와 행위(Action)를 정확히 연결하고, 개체명 인식(NER)의 정확도를 높일 수 있습니다.
지시 대명사의 구체화: "그 문제", "동 사항" 대신 "해당 서버 접속 장애 문제", "상기 예산 증액 사항" 등 구체적인 명사를 반복 사용하는 것이 RAG의 검색 정확도를 높이는 지름길입니다. 이는 문서의 '어휘적 밀도(Lexical Density)'를 높여 검색 성능을 향상시킬 수 있습니다.
5.3 표 데이터의 서술화 (Table Verbalization)
복잡한 표는 AI에게 여전히 난해한 영역입니다. 표에 담긴 핵심 인사이트는 반드시 표 상단이나 하단에 줄글로 풀어서 요약(Verbalization)해 주어야 합니다.
캡션 활용: "표 3. 2024년 분기별 매출 현황"과 같이 구체적인 캡션을 달아야 합니다. 캡션은 표와 텍스트를 연결하여 인공지능의 이해를 돕습니다.
마크다운 친화적 표 설계: 표를 만들 때는 병합(Merge)을 최소화하고, '1행 1데이터' 원칙을 지키는 단순한 그리드 구조(Simple Grid)를 지향해야 합니다. 복잡한 다차원 데이터를 표현해야 한다면, 차라리 표를 여러 개로 쪼개는 것이 낫습니다.
6. 실무자를 위한 체크리스트 & 표 작성 가이드
문서 저장 전, 다음 사항을 반드시 확인하십시오.
| 구분 | 점검 항목 | AI 관점의 기술적 이점 |
|---|---|---|
| 구조 (Structure) | 스타일(제목 1, 2, 3)을 사용하여 논리적 계층 구조를 만들었는가? | 문서의 뼈대(Skeleton) 파악 및 시맨틱 청킹(Semantic Chunking) 정확도 향상 |
| 탐색 창(Word)이나 개요 보기(HWP)에서 목차가 정상적으로 계층화되어 보이는가? | 문서 구조의 무결성(Integrity) 검증 | |
| 텍스트 상자나 부유 객체를 제거하고 본문 내 삽입(In-line)을 했는가? | 텍스트 추출 시 읽는 순서(Reading Order)의 일관성 보장 | |
| 언어 (Language) | 문단마다 핵심 내용이 첫 문장에 포함되어 있는가? (두괄식) | 임베딩 벡터 생성 시 문두 가중치 활용 및 검색 연관성(Relevance) 최적화 |
| 주어와 목적어를 생략하지 않고 명시적으로 작성했는가? (Zero Anaphora 방지) | 문맥 유실 방지 및 개체명 인식(NER)을 통한 정보 추출 정확도 향상 | |
| '그', '저', '상기' 등 모호한 지시어 대신 구체적 명사를 사용했는가? | 청크 단위의 정보 독립성 확보 (Context Independence) | |
| 데이터 (Data) | 표의 셀 병합을 최소화하고 1행 1데이터 구조로 단순화했는가? | 표 파싱 오류 최소화 및 Markdown 변환 시 데이터 왜곡 방지 |
| 표나 차트에 대한 핵심 분석 내용을 본문에 텍스트로 요약(Verbalization)했는가? | 표/이미지 처리 능력이 부족한 모델을 위한 정보 중복성(Redundancy) 확보 | |
| 이미지에 대체 텍스트(Alt text)나 상세 캡션을 입력했는가? | 멀티모달 검색 지원 및 이미지 정보의 텍스트화 | |
| 포맷 (Format) | HWP 파일의 경우 HWPX로 저장하거나 PDF 변환 시 태그(Tag)를 포함했는가? | 기계 가독형 포맷 지원 및 XML 파싱 가능성 확보 |
6.1 정책 입안자 및 관리자를 위한 제언: 거버넌스의 수립
개별 작성자의 노력만으로는 한계가 있다. 조직 차원의 시스템과 문화가 뒷받침되어야 합니다.
'디지털 문서 표준' 제정 및 평가 반영: 조직 내 문서 작성 규정에 '기계 가독성' 항목을 신설해야 하는 것이 필요합니다.
"보기 좋은 문서"보다 "검색 잘 되는 문서"에 가산점을 주는 평가 문화가 필요할 것으로 보입니다. 특히 공공기관 경영평가 항목에 '공공 데이터 개방성(기계 가독성 준수 여부)'을 포함시키는 것은 강력한 드라이브가 될 수 있습니다.
전용 템플릿 배포 및 강제화: 사용자의 자발적 노력에 기대기보다, 스타일과 개요, 메타데이터 필드가 미리 세팅된 'AI 표준 템플릿(AI-Ready Template)'을 제작하여 배포해야 합니다.
사용자는 스타일을 고민할 필요 없이 내용만 채우면 되도록 유도(Nudge)해야 합니다.
레거시 데이터의 마이그레이션 전략: 과거에 생산된 HWP/PDF 문서를 RAG에 올리기 전에 전처리(Pre-processing)하는 파이프라인을 구축해야 합니다.
단순히 OCR만 돌리는 것이 아니라, 문서의 레이아웃을 분석(Layout Analysis)하여 문단 순서를 재조립하고, 표를 Markdown으로 변환하는 전문 AI 모델의 도입이 필요합니다.
결론: 데이터로서의 문서, 그 새로운 가치를 향하여
"문서는 죽은 정보가 아니라, 살아있는 데이터여야 한다."
인공지능 시대의 문서는 작성과 동시에 끝나는 결과물이 아닙니다. 그것은 조직의 지식 베이스로 흘러들어가 끊임없이 재가공되고, 검색되고, 새로운 인사이트를 만들어내는 중요한 원천 데이터입니다.
한국의 공공기관과 기업이 사용하는 HWP와 Word 포맷은 그동안 '출력'과 '보존'에 최적화되어 있었으나, 이제는 '활용'과 '지능화'로 그 무게 중심을 변화하여야 합니다.
개발자 중심의 Markdown이나 JSON 도입이 어렵다고 해서 포기할 필요는 없습니다. 우리가 매일 쓰는 워드프로세서의 '스타일' 버튼을 한 번 클릭하는 것, 표를 조금 더 단순하게 만드는 것, 주어를 생략하지 않고 명확하게 쓰는 작은 습관들이 모여 거대한 변화를 만들 수 있습니다. 이러한 작은 실천들이 모여 AI가 우리 조직의 지식을 완벽하게 이해하고, 우리가 미처 발견하지 못한 가치를 찾아내는 강력한 협업 파트너로 거듭나게 할 것입니다.
참고 문헌 (References)
본 글은 다음의 자료들을 바탕으로 작성되었습니다.
GitBook. (n.d.). GEO guide: How to optimize your docs for AI search and LLM ingestion. GitBook Documentation. https://gitbook.com
Amazon Web Services. (n.d.). Documentation best practices for RAG applications. AWS Prescriptive Guidance. https://docs.aws.amazon.com
Microsoft. (n.d.). RAG and generative AI - Azure AI Search. Microsoft Learn. https://learn.microsoft.com
Filimoa. (n.d.). open-parse: Improved file parsing for LLM's. GitHub. https://github.com
김창현. (2024). President Lee urges technical fixes for HWP barriers to AI use in Korea. ChosunBiz. https://biz.chosun.com
Microsoft. (n.d.). The Styles advantage in Word. Microsoft Support. https://support.microsoft.com
University of Arkansas. (n.d.). Using the Styles Pane and Navigation Pane in Microsoft Word for Accessibility. TIPS. https://tips.uark.edu
한글과컴퓨터. (n.d.). 한컴어시스턴트 - AI기반 문서 작성 도구. Hancom Assistant. https://hancomassistant.com
Intel. (n.d.). Tabular Data, RAG, & LLMs: Improve Results Through Data Table Prompting. Medium. https://medium.com
arXiv. (n.d.). Exploring the Impact of Table-to-Text Methods on Augmenting LLM-based Question Answering with Domain Hybrid Data. arXiv. https://arxiv.org
Nanonets. (n.d.). Table Extraction using LLMs: Unlocking Structured Data from Documents. Nanonets. https://nanonets.com
공공데이터포털. (2025). 인사혁신처_인공지능(AI) 활용가이드. 공공데이터포털. https://data.go.kr