
Gemini 임베딩 모델 완벽 가이드: Python으로 시맨틱 검색 프로토타입 만들기

Gemini 임베딩 모델 완벽 가이드: Python으로 시맨틱 검색 프로토타입 만들기
안녕하세요! 오늘은 Google의 강력한 언어 모델인 Gemini의 임베딩(Embedding) 기능을 활용하여, 문장의 의미를 이해하고 분석하는 Python 프로토타입을 만드는 전 과정을 소개해 드리려고 합니다.
이 튜토리얼을 끝까지 따라오시면, 단순히 단어의 유무를 넘어 문장의 '의미'를 기반으로 유사도를 측정하고, 관련 문서를 검색하는 '시맨틱 검색'의 기본 원리를 직접 구현하고 체험하실 수 있습니다. 언어 학습 앱에서 사용자의 답변이 정답과 얼마나 유사한지 평가하거나, 방대한 문서에서 사용자의 질문 의도에 가장 맞는 내용을 찾아주는 시스템을 만드는 첫걸음이 될 것입니다.
🎯 최종 목표
다국어 유사도 분석: "안녕하세요"와 "Hello"가 얼마나 유사한지 분석합니다.
시맨틱 검색: "영어로 과거 시제는 어떻게 만들어?"라고 질문하면 관련 문법 문서를 찾아냅니다.
시각화: 문장 간의 관계를 3D 공간에 시각적으로 표현하여 직관적으로 이해합니다.
✅ 준비물
Python (3.8 이상): 컴퓨터에 Python이 설치되어 있어야 합니다.
Google AI Studio API 키: 여기를 클릭하여 무료로 API 키를 발급받으세요.
🛠️ 1단계: 프로젝트 환경 설정
코드를 작성하기 전, 프로젝트만을 위한 독립된 개발 환경을 만들어주는 것이 좋습니다. 이를 '가상환경'이라고 부르며, 프로젝트 간의 라이브러리 충돌을 막아줍니다.
프로젝트 폴더 생성 및 이동 PowerShell(또는 CMD)을 열고 아래 명령어를 입력하여 작업할 폴더를 만들고 이동합니다.
mkdir gemini-embedding-project cd gemini-embedding-project가상환경 생성
venv라는 이름의 가상환경을 생성합니다.python -m venv venv가상환경 활성화 이제부터 이 가상환경 안에서 모든 작업을 진행합니다.
.venvScriptsActivate.ps1명령어 앞에
(venv)가 표시되면 성공적으로 활성화된 것입니다.
📚 2단계: 필수 라이브러리 설치
이제 프로젝트에 필요한 모든 파이썬 라이브러리를 한 번에 설치하겠습니다.
pip install google-generativeai numpy scikit-learn matplotlib seaborn plotly pandas python-dotenv
google-generativeai: Gemini API를 사용하기 위한 공식 라이브러리numpy,scikit-learn: 벡터 연산, 코사인 유사도 계산, PCA 등 데이터 분석에 사용matplotlib,seaborn,plotly: 결과 시각화를 위한 라이브러리pandas: 데이터를 다루기 위한 라이브러리python-dotenv: API 키를 안전하게 관리하기 위한 라이브러리
🔑 3단계: API 키 안전하게 관리하기 (.env)
API 키는 민감한 정보이므로 코드에 직접 노출하지 않는 것이 매우 중요합니다. .env 파일을 사용하여 키를 안전하게 관리합니다.
프로젝트 폴더(
gemini-embedding-project) 안에.env라는 이름의 파일을 새로 만듭니다.생성한
.env파일에 아래와 같이 API 키를 입력하고 저장합니다.YOUR_API_KEY부분은 본인의 키로 교체해주세요.GOOGLE_AI_API_KEY="YOUR_API_KEY"
💻 4단계: 전체 Python 코드 작성
이제 모든 준비가 끝났습니다. 프로젝트 폴더에 gemini_test.py 라는 이름으로 파이썬 파일을 만들고 아래의 전체 코드를 붙여넣으세요.
#!/usr/bin/env python3
"""
🚀 Gemini 임베딩 모델 테스트 프로토타입
언어 학습 앱을 위한 시맨틱 검색 및 유사도 분석
요구사항:
pip install google-generativeai numpy scikit-learn matplotlib seaborn plotly pandas python-dotenv
"""
import os
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
import plotly.graph_objects as go
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
import google.generativeai as genai # 공식 라이브러리
import pandas as pd
from typing import List, Dict, Tuple
from dotenv import load_dotenv # .env 파일을 위해 추가
class GeminiEmbeddingTester:
"""Gemini 임베딩 모델 테스트 클래스"""
def __init__(self, api_key: str):
"""
초기화
Args:
api_key: Google AI API 키. main 함수에서 환경변수를 읽어와 전달합니다.
"""
# API 키 설정
genai.configure(api_key=api_key)
self.embeddings_cache = {}
def get_embedding(self, text: str, task_type: str = "SEMANTIC_SIMILARITY") -> np.ndarray:
"""
텍스트의 임베딩 벡터 생성
'models/embedding-001' 모델은 항상 768차원 벡터를 반환합니다.
Args:
text: 임베딩할 텍스트
task_type: 작업 유형 (SEMANTIC_SIMILARITY, RETRIEVAL_DOCUMENT 등)
Returns:
임베딩 벡터 (Numpy 배열)
"""
cache_key = f"{text}_{task_type}"
if cache_key in self.embeddings_cache:
return self.embeddings_cache[cache_key]
try:
# google-generativeai 라이브러리의 최신 API 호출 방식
result = genai.embed_content(
model="models/embedding-001",
content=text,
task_type=task_type
)
embedding = np.array(result['embedding'])
self.embeddings_cache[cache_key] = embedding
return embedding
except Exception as e:
print(f"❌ 임베딩 생성 실패: {e}")
return None
def test_basic_similarity(self):
"""기본 유사도 테스트"""
print("🧪 기본 유사도 테스트")
print("=" * 50)
texts = [
"Hello, how are you?", "Hi, how are you doing?", "안녕하세요, 어떻게 지내세요?",
"I love programming", "I enjoy coding", "What time is it?",
"Can you tell me the time?", "The weather is nice today", "It's a beautiful day"
]
embeddings = [self.get_embedding(t) for t in texts if self.get_embedding(t) is not None]
if not embeddings:
print("❌ 임베딩 생성 실패")
return None, None, None
similarity_matrix = cosine_similarity(embeddings)
print("\n📊 유사도 매트릭스:")
for i, text1 in enumerate(texts):
for j in range(i + 1, len(texts)):
print(f"'{text1}' ↔ '{text2}': {similarity_matrix[i, j]:.4f}")
plt.figure(figsize=(12, 10))
sns.heatmap(similarity_matrix, annot=True, cmap='viridis', fmt='.3f',
xticklabels=[f"T{i+1}" for i in range(len(texts))],
yticklabels=[f"T{i+1}" for i in range(len(texts))])
plt.title('텍스트 유사도 히트맵')
plt.tight_layout()
plt.show()
return similarity_matrix, texts, embeddings
def test_language_learning_scenarios(self):
"""언어 학습 시나리오 테스트"""
print("\n🎓 언어 학습 시나리오 테스트")
print("=" * 50)
language_groups = {
"인사": ["Hello, nice to meet you", "안녕하세요, 만나서 반가워요", "Bonjour, ravi de vous rencontrer"],
"감사": ["Thank you very much", "정말 고마워요", "Merci beaucoup"],
"날씨": ["The weather is beautiful today", "오늘 날씨가 정말 좋아요", "Il fait beau aujourd'hui"]
}
results = {}
for category, sentences in language_groups.items():
print(f"\n📚 {category} 카테고리:")
embeddings = [self.get_embedding(s) for s in sentences if self.get_embedding(s) is not None]
if len(embeddings) != len(sentences): continue
similarities = []
for i in range(len(sentences)):
for j in range(i + 1, len(sentences)):
sim = cosine_similarity([embeddings[i]], [embeddings[j]])[0][0]
similarities.append(sim)
print(f" '{sentences[i]}' ↔ '{sentences[j]}': {sim:.4f}")
results[category] = {'avg_similarity': np.mean(similarities)}
return results
def test_semantic_search(self):
"""시멘틱 검색 테스트"""
print("\n🔍 시멘틱 검색 테스트")
print("=" * 50)
documents = [
"Grammar rules for English past tense: Regular verbs add -ed",
"French pronunciation guide: The letter 'h' is usually silent",
"Spanish conjugation: Present tense verbs ending in -ar",
"English vocabulary: Colors - red, blue, green, yellow"
]
doc_embeddings = [self.get_embedding(d, "RETRIEVAL_DOCUMENT") for d in documents]
queries = ["How to form past tense in English?", "Color words in English"]
print("\n🎯 검색 결과:")
for query in queries:
print(f"\n❓ 검색어: '{query}'")
query_emb = self.get_embedding(query, "RETRIEVAL_QUERY")
if query_emb is None: continue
similarities = cosine_similarity([query_emb], doc_embeddings)[0]
top_indices = np.argsort(similarities)[::-1][:2]
for i, idx in enumerate(top_indices):
print(f" {i+1}. [{similarities[idx]:.4f}] {documents[idx]}")
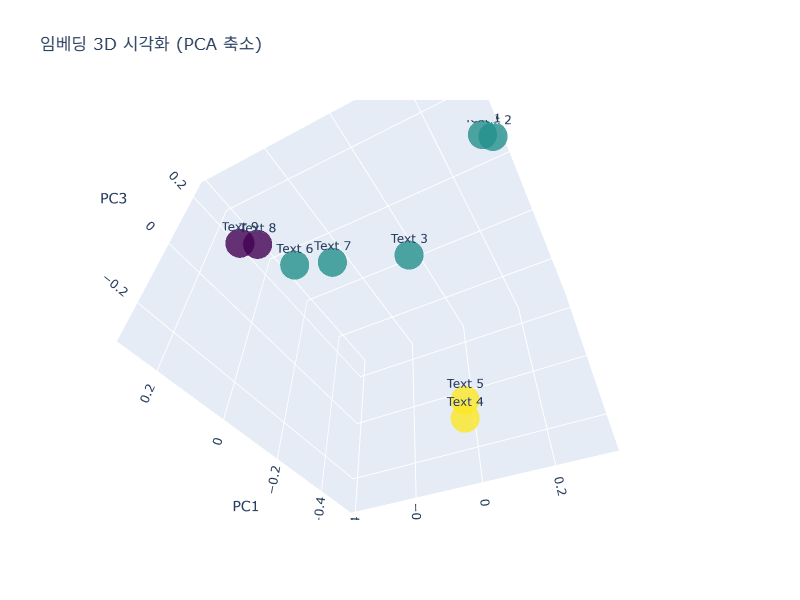
def visualize_embeddings_3d(self, texts: List[str]):
"""임베딩을 3D로 시각화"""
print("\n📊 3D 임베딩 시각화")
print("=" * 50)
embeddings = [self.get_embedding(t) for t in texts if self.get_embedding(t) is not None]
if len(embeddings) < 3:
print("❌ 3D 시각화를 위한 임베딩이 부족합니다 (최소 3개 필요)")
return
pca = PCA(n_components=3)
embeddings_3d = pca.fit_transform(np.array(embeddings))
fig = px.scatter_3d(embeddings_3d, x=0, y=1, z=2, text=texts,
title="임베딩 3D 시각화 (PCA 축소)")
fig.update_traces(textposition='top center')
fig.show()
def run_full_test_suite(self):
"""전체 테스트 실행"""
print("🚀 Gemini 임베딩 모델 종합 테스트")
print("=" * 60)
res = self.test_basic_similarity()
if res is None or res[0] is None:
print("기본 유사도 테스트 실패로 중단합니다.")
return
_, texts, _ = res
self.test_language_learning_scenarios()
self.test_semantic_search()
self.visualize_embeddings_3d(texts)
print("\n🎉 모든 테스트가 완료되었습니다!")
def main():
"""메인 실행 함수"""
load_dotenv()
print("🌟 Gemini 임베딩 모델 테스트 프로토타입")
print("=" * 60)
api_key = os.getenv('GOOGLE_AI_API_KEY')
if not api_key:
print("⚠️ API 키를 찾을 수 없습니다! .env 파일을 확인하세요.")
return
tester = GeminiEmbeddingTester(api_key)
tester.run_full_test_suite()
if __name__ == "__main__":
main()
▶️ 5단계: 스크립트 실행 및 결과 분석
이제 모든 준비가 끝났습니다. PowerShell에서 아래 명령어를 실행하여 우리가 만든 테스트 스크립트를 실행해 보세요.
python gemini_test.py
스크립트가 실행되면 터미널에 다양한 테스트 결과가 출력되고, 중간중간 히트맵과 3D 그래프 창이 나타날 것입니다.
기본 유사도 테스트:
Hello, how are you?와Hi, how are you doing?의 유사도 점수가 다른 문장 쌍보다 월등히 높게 나오는 것을 볼 수 있습니다. 언어가 다른안녕하세요, 어떻게 지내세요?와도 상당히 높은 유사도를 보여줍니다.언어 학습 시나리오: '인사', '감사', '날씨' 각 카테고리 내에서 다른 언어의 문장들이 얼마나 의미적으로 가까운지 점수로 확인할 수 있습니다.
시맨틱 검색:
How to form past tense in English?라는 질문에Grammar rules for English past tense...문서를 가장 높은 점수로 찾아내는 것을 볼 수 있습니다.시각화: 3D 그래프에서 의미가 비슷한 문장들끼리 서로 가까이 모여있는 것을 직관적으로 확인할 수 있습니다.
✨ 마무리 및 다음 단계
축하합니다! 여러분은 Gemini 임베딩 모델을 사용하여 문장의 의미를 분석하는 강력한 프로토타입을 직접 만들어 보았습니다.
여기서 한 걸음 더 나아가면, 오늘 만든 기능을 활용하여 다음과 같은 멋진 애플리케이션을 만들 수 있습니다.
RAG(Retrieval-Augmented Generation) 챗봇: 사용자의 질문 의도에 가장 적합한 정보를 데이터베이스에서 찾아내어, 그 정보를 바탕으로 Gemini가 더 정확하고 풍부한 답변을 생성하게 만듭니다.
언어 학습 앱의 자동 채점 시스템: 학생이 작문한 문장이 모범 답안과 의미적으로 얼마나 유사한지 평가하여 점수를 매깁니다.
콘텐츠 추천 시스템: 사용자가 현재 보고 있는 기사와 의미적으로 가장 유사한 다른 기사들을 추천해 줍니다.
이 튜토리얼이 여러분의 프로젝트에 새로운 영감을 주었기를 바랍니다. 궁금한 점이 있다면 언제든지 댓글로 질문해주세요!