CPU: Control Hazards Control

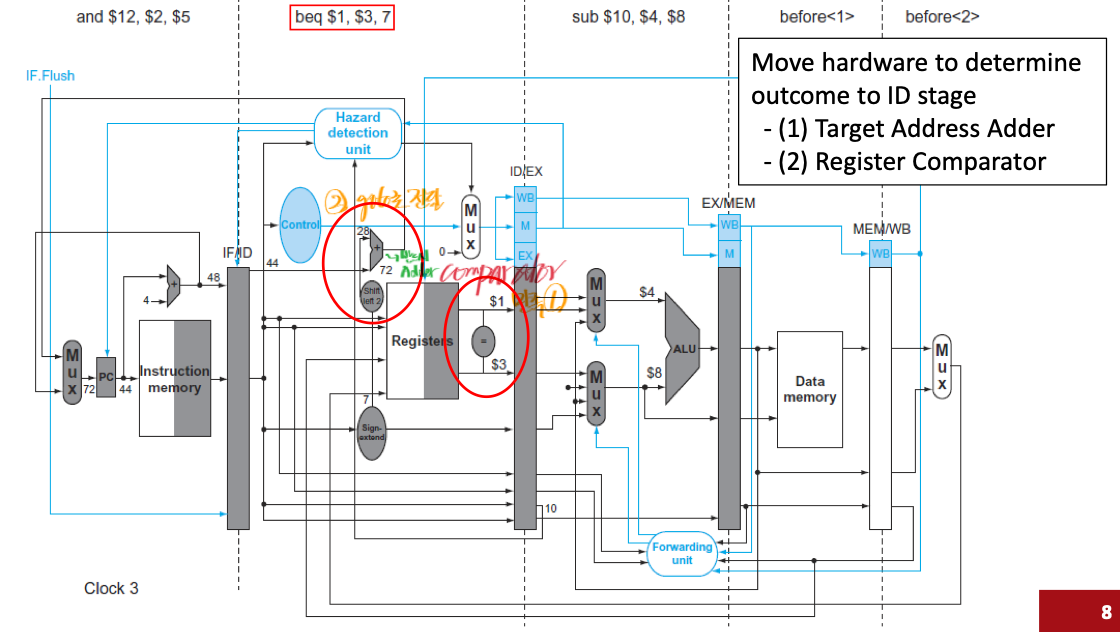
위 이미지는 MIPS 파이프라인에서 제어 해저드(Control Hazard)를 줄이기 위해 beq 명령어의 분기 결정 로직을 ID 단계로 앞당긴(early branch resolution) 파이프라인 구조를 보여줍니다.
(1) Target Address Adder: 분기 목표 주소를 계산하는 덧셈기
(2) Register Comparator: 레지스터 값을 비교하는 비교기
이 두 가지 하드웨어가 다이어그램에서 ID 단계에 추가되어 있고, 빨간색 동그라미로 강조되어 있습니다.
Adder와 Comparator가 없다면, 분기의 조건 판단은 EX 단계에서 판단할 수 있습니다. ALU 조건을 통해서 같은지를 판단해, Zero 임을 판단해야 하기 때문입니다. 하지만, 값의 판단을 EX 단계에서 할 뿐 값은 ID 에서 모두 전달됩니다. 따라서 위와 같이 Adder, Comparator 를 추가한다면 1 사이클 미리 분기 조건을 판단할 수 있습니다.
ID 단계에서 분기 제어 로직의 동작 (빨간색 동그라미 부분)
레지스터 파일 읽기 및
Register Comparator(레지스터 비교기):ID단계에서는IF/ID레지스터에서beq명령어($1,$3)를 해독합니다.beq명령어가 필요로 하는$1과$3레지스터의 값이Registers(레지스터 파일)에서 읽혀져 나옵니다.읽혀진
$1과$3의 값은 빨간색 동그라미로 표시된Comparator로 즉시 전달됩니다.Comparator는 이 두 값이 같은지 ($1 == $3)를 비교하여 분기 여부를 결정하는Branch Taken과 같은 신호를 생성합니다.
Target Address Adder(분기 목표 주소 덧셈기):ID단계에서는IF/ID레지스터에서 넘어온PC + 4값과beq명령어에 포함된Sign-extend된offset(7)을 받습니다.이 두 값은 빨간색 동그라미로 표시된
Adder로 즉시 전달됩니다. (오프셋은Shift left 2를 거쳐 4배 되어 더해집니다.)Adder는PC + 4 + (offset * 4)를 계산하여 분기 목표 주소를 생성합니다.
제어 해저드 해결 과정:
ID단계에서의 결정:Clock 3시점에beq $1, $3, 7명령어가ID단계에 있습니다. 이 단계에서 위에 설명된Comparator와Adder덕분에, 현재 클럭 사이클 내에 분기할지 말지, 그리고 분기한다면 어디로 갈지가 모두 결정됩니다.IF.Flush신호:만약
ID단계에서beq가 "분기한다!"고 결정되면,Hazard Detection Unit또는Control Unit은 즉시IF.Flush신호를 활성화합니다.이
IF.Flush신호는IF/ID파이프라인 레지스터를 클리어(flush)하여 NOP (No Operation) 명령어를 주입합니다. (그림에서IF.Flush가IF/ID레지스터의 MUX에 연결된 것을 볼 수 있습니다.)동시에, PC (
Program Counter)의 MUX를 제어하여 분기 목표 주소(ID 단계에서 계산된)를 새로운 PC 값으로 설정하여 다음 클럭부터 올바른 경로의 명령어를 인출하도록 합니다. (PC로 들어가는 MUX에도 파란색 제어 선이 연결되어 있습니다.)
패널티 감소:
이전에는
EX단계에서 분기 결정이 났기 때문에,IF단계와ID단계에 이미 들어와 있는 2개의 명령어를 폐기해야 했습니다 (2 클럭 패널티).이제
ID단계에서 분기 결정이 나므로, 오직IF단계에 있는 1개의 명령어 (sub $10, ...)만 폐기하면 됩니다. (1 클럭 패널티).
Dynamic Branch Prediction
정적 분기 예측(Static Branch Prediction)이 미리 정해진 규칙에 따라 분기를 예측하는 반면, 동적 분기 예측은 프로그램 실행 시점의 과거 분기 이력(history)을 기반으로 미래의 분기 행동을 예측합니다.
동적 분기 예측의 필요성
깊은 파이프라인(예: 10단계 이상)을 가진 현대 CPU에서 분기 예측 실패는 매우 큰 패널티를 초래합니다. 예측이 틀릴 경우, 파이프라인에 이미 들어온 수많은 잘못된 명령어들을 폐기(flush)하고, 올바른 경로의 명령어를 다시 인출하는 데 많은 클럭 사이클이 낭비되기 때문입니다. 동적 분기 예측은 이러한 예측 실패율을 줄여 파이프라인의 효율성을 극대화합니다.
기본 원리
동적 분기 예측의 핵심 아이디어는 "과거의 분기 행동은 미래의 분기 행동을 예측하는 데 좋은 지표가 된다"는 것입니다. 예를 들어, 루프(loop)의 끝에 있는 분기는 대부분의 경우 분기(taken)하지만, 루프의 마지막 반복에서는 분기하지 않습니다(not taken). 동적 예측기는 이러한 반복적인 패턴을 학습하여 예측합니다. Not taken 인 경우 분기 예측 비트가 0, taken 인 경우 분기 예측 비트가 1이 됩니다.
for (let index = 0; index < bound; index++) {
...
}예를 들어 위와 같은 for loop 인 경우에 index가 bound 보다 작은 경우 계속 branch taken 되다가 bound와 같아지는 경우 branch not taken 됩니다.
주요 구성 요소
분기 이력 테이블 (Branch History Table, BHT) 또는 분기 예측 버퍼 (Branch Prediction Buffer):
역할: 각 분기 명령어의 주소(또는 주소의 일부 비트)를 인덱스로 사용하여, 해당 분기가 이전에 어떻게 행동했는지(분기했는지/안 했는지)에 대한 이력 정보를 저장합니다.
저장 내용: 일반적으로 1비트 또는 2비트의 예측 상태 머신(Predictor State Machine)을 각 엔트리에 가집니다.
1비트 예측기:
0: Not Taken (분기 안 함)으로 예측
1: Taken (분기 함)으로 예측
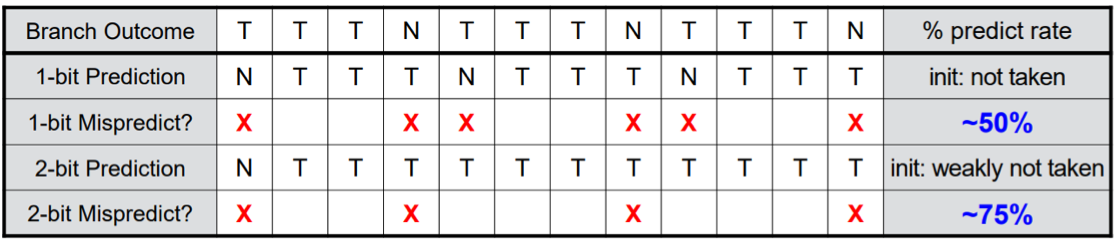
단점: 예측이 한 번만 틀려도 바로 예측이 뒤집히므로, 루프의 마지막 반복처럼 행동이 바뀌는 경우 두 번 연속 예측이 틀릴 수 있습니다. (예: TTTTFN -> NT 예측 -> 틀림(T) -> TT 예측)
for (let i = 0; i < 5; i++) { for (let j = 0; j < 3; j++) { ... } }다음과 같이 중첩된 for loop로 구성되어 있는 경우에는 어떨까요? i, j 에 대한 loop가 범위를 넘지 않아 실행되는 중이라면 분기 예측 비트는 1로 계속 taken 된다고 예측할 것입니다. 그렇다면 i = 2 이고 내부 j 에 대해 loop가 끝난 후 branch not taken 된 상황이라 가정해봅시다. j 에 대한 loop가 branch not taken 되었으니 분기 예측 비트가 틀렸다는 판단(miss)을 일으키고 분기 예측 비트는 0으로 설정이 됩니다. 하지만 우리는 i 에 대한 loop도 고려해야 합니다. i 는 loop 범위 내에 있기 때문에 taken 으로 처리되어야 합니다. 하지만, 분기 예측 비트가 0이기 때문에 다시 miss가 발생해 1로 변경되어야 합니다.
2비트 예측기 (Saturating Counter):
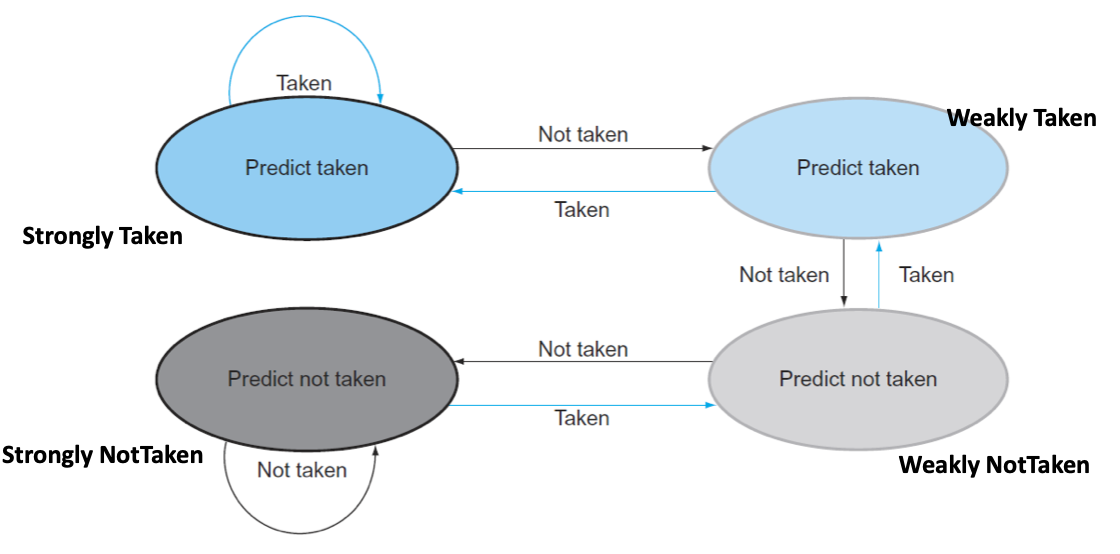
00: Strongly Not Taken
01: Weakly Not Taken
10: Weakly Taken
11: Strongly Taken
동작: 예측이 틀려도 바로 예측을 뒤집지 않고, '강하게 예측' 상태에서 '약하게 예측' 상태로 한 단계만 변경됩니다. 이렇게 하면 루프의 끝에서 한 번 예측이 틀리더라도, 다음 번에는 여전히 올바른 예측을 할 가능성이 높아 예측 정확도가 향상됩니다.
동작: 새로운 분기 명령어가 인출되면, BHT를 검색하여 해당 분기의 과거 이력을 확인하고, 이 이력에 기반하여 예측을 수행합니다.
키워드만 입력하면 나만의 학습 노트가 완성돼요.
책이나 강의 없이, AI로 위키 노트를 바로 만들어서 읽으세요.
콘텐츠를 만들 때도 사용해 보세요. AI가 리서치, 정리, 이미지까지 초안을 바로 만들어 드려요.