
LLM 내부 원리 해부: Circuit Tracing 개념과 Google Colab 실습 가이드 – 프롬프트 엔지니어링까지 완전정복

개념 및 Google Colab 실험 가이드
우리가 매일 사용하는 챗GPT, Claude와 같은 대규모 언어 모델(LLM)들은 놀라운 성능을 보여주지만, 그 내부에서 어떤 과정을 거쳐 결과물을 내놓는지 우리는 알기 어려웠습니다. 마치 마법 상자처럼 느껴졌죠. 하지만 최근, 이 '블랙박스'를 열어 LLM의 작동 원리를 시각적으로 분석하는 혁신적인 연구가 진행되고 있습니다. 바로 'Circuit Tracing'이라는 기술입니다.
이번 블로그 시리즈에서는 Anthropic (클로드 개발사)에서 공개한 최신 연구인 "Circuit Tracing: Revealing Computational Graphs in Language Models" 논문을 중심으로, 이 기술이 무엇인지, 어떻게 AI의 생각을 엿볼 수 있는지, 그리고 프롬프트 엔지니어링 관점에서 우리에게 어떤 의미를 주는지 상세히 다루어 보려고 합니다. 특히, 초보자도 쉽게 따라 할 수 있도록 Google Colab을 이용한 실험 방법과 실제 사례를 함께 살펴보겠습니다.
1. Circuit Tracing이란 무엇인가? - AI의 '회로도'를 그리는 기술
AI 모델, 특히 LLM은 수많은 인공 신경망(뉴런)과 층(레이어)으로 구성되어 있습니다. 우리가 질문을 던지면, 이 질문은 모델의 초기 레이어에서 처리되기 시작하여 여러 층을 거치며 복잡한 변환 과정을 거치고, 최종적으로 답변이라는 결과물을 내놓습니다.
Circuit Tracing은 바로 이 복잡한 변환 과정, 즉 AI 모델 내부에서 정보가 어떻게 흐르고 상호작용하는지 '계산 그래프(Computational Graph)' 또는 '귀속 그래프(Attribution Graph)' 형태로 시각화하여 보여주는 기술입니다. 이를 통해 우리는 특정 입력(프롬프트)에 대해 AI가 어떤 '생각의 경로'를 거쳐 답변을 생성했는지 추적할 수 있습니다.
핵심 개념:
Residual Stream (잔여 스트림): AI 모델의 각 레이어 사이를 흐르는 정보의 '고속도로'라고 생각하면 됩니다. 데이터가 이 스트림을 통해 전달되고 변형됩니다.
Feature (특징): AI 모델이 텍스트나 데이터를 이해하는 데 사용하는 '의미 단위'입니다. 예를 들어, "강아지"라는 단어를 입력하면 '포유류', '반려동물', '털' 등 다양한 특징들이 활성화될 수 있습니다. Circuit Tracing에서는 기존의 '뉴런'보다 더 해석하기 쉬운(interpretable) 특징을 찾아내어 분석합니다.
Neuron (뉴런): AI 모델의 가장 기본적인 계산 단위입니다. 하지만 실제 모델에서는 하나의 뉴런이 여러 개의 의미(polysemantic)를 동시에 나타내거나, 여러 뉴런에 걸쳐 하나의 의미가 '분산(superposition)'되어 표현될 수 있어 해석이 어렵습니다.
Replacement Model (대체 모델): Circuit Tracing은 원본 LLM 전체를 직접 분석하는 것이 아니라, 원본 모델의 특정 복잡한 부분(주로 Multi-Layer Perceptron, MLP)을 'Cross-Layer Transcoder (CLT)'라는 더 해석하기 쉬운 구성 요소로 '대체'한 모델을 사용합니다. 이 대체 모델은 원본 모델의 작동을 최대한 비슷하게 모방하면서도, 내부 과정을 더 투명하게 보여줍니다.
Attribution Graph (귀속 그래프): 대체 모델을 통해 특정 프롬프트가 주어졌을 때, 어떤 특징들이 활성화되고 서로에게 어떤 영향을 주면서 최종 출력(예측 단어)에 도달하는지를 보여주는 시각화된 그래프입니다. 노드는 특징이나 토큰, 출력 등을 나타내고, 엣지는 노드 간의 영향력(가중치)을 나타냅니다.
2. Google Colab을 이용한 Circuit Tracing 실험 환경 구축 및 실행 (초보자 가이드)
Anthropic은 이 연구를 위한 도구와 코드를 GitHub에 공개했습니다. 이를 활용하여 Google Colab에서 직접 실험 환경을 구축하고 간단한 Circuit Tracing을 실행하는 방법을 알려드릴게요.
준비물: Google 계정 (Colab 사용을 위함)
단계별 가이드:
Google Colab 접속: 웹 브라우저에서 colab.research.google.com에 접속하여 새 노트를 만듭니다. (GPU 런타임 사용을 권장합니다. 런타임 > 런타임 유형 변경 > 하드웨어 가속기 > T4 GPU 선택)
필수 라이브러리 설치: Circuit Tracing 도구를 사용하려면 필요한 라이브러리들을 설치해야 합니다. Colab 노트북에 다음 코드를 입력하고 실행하세요.
Python
# Circuit Tracing 도구 설치 !pip install git+https://github.com/Anthropic/circuit_tracer.git # 필요한 라이브러리 임포트 (이후 예시 코드에서 사용) import torch from circuit_tracer.frontend.local_server import serve from circuit_tracer.model import load_model from IPython.display import IFrame from google.colab import output as colab_output # Colab 환경에서만 필요
(설치에는 다소 시간이 걸릴 수 있습니다.)
모델 로드: 이제 Circuit Tracing을 적용할 AI 모델을 로드합니다. 이 예시에서는 논문에서 사용된 소형
gemma-2-2b모델을 사용하겠습니다.Python
# IN_COLAB 변수 설정 (Colab 환경인지 확인) IN_COLAB = 'google.colab' in str(get_ipython()) # IPython 환경에서만 작동하는 코드 # 모델 로드 (다운로드 및 로딩에 시간이 걸릴 수 있습니다) model_name = "gemma-2-2b" model, tok = load_model(model_name) print(f"모델 '{model_name}' 로드 완료.")Circuit Tracing 서버 실행 및 시각화: 이제 실제 Circuit Tracing을 수행하고 그 결과를 웹 인터페이스로 띄울 차례입니다. 앞서 보았던 "The capital of state containing Dallas is" 예시를 사용해 보겠습니다.

# 추적할 프롬프트 및 설정 정의 prompt = "The capital of state containing Dallas is" # 분석하고 싶은 문장 max_n_logits = 10 # 최대 10개의 예측 단어에 대한 로그 확률 기여도 추적 desired_logit_prob = 0.95 # 상위 예측 단어들의 누적 확률이 95%에 도달할 때까지 추적 max_feature_nodes = 8192 # 최대 특징 노드 수 (시각화 속도에 영향) batch_size = 256 # 연산 배치 크기 offload = 'disk' if IN_COLAB else 'cpu' # 메모리 절약을 위한 오프로드 설정 (Colab에서는 디스크 사용) verbose = True # 진행 상황 표시 # Circuit Tracing 실행 및 로컬 서버 시작 # 이 함수가 실제 계산 그래프를 생성하고 웹 인터페이스를 띄웁니다. # 계산에는 시간이 걸릴 수 있습니다 (모델 크기 및 설정에 따라 수 분 ~ 수십 분). port = 8046 server = serve( data_dir='./graph_files/', # 그래프 파일 저장 경로 port=port, model=model, tok=tok, prompt=prompt, max_n_logits=max_n_logits, desired_logit_prob=desired_logit_prob, max_feature_nodes=max_feature_nodes, batch_size=batch_size, offload=offload, verbose=verbose ) if IN_COLAB: # Google Colab 환경에서는 iframe으로 결과를 보여줍니다. print(f"Google Colab에서 그래프 로드 중... 잠시 기다려주세요.") colab_output.serve_kernel_port_as_iframe(port, path='/index.html', height='800px', cache_in_notebook=True) else: # 로컬 환경에서는 직접 접속할 수 있는 링크를 제공합니다. print(f"웹 브라우저에서 다음 주소로 접속하여 그래프를 확인하세요: http://localhost:{port}/index.html") display(IFrame(src=f'http://localhost:{port}/index.html', width='100%', height='800px'))코드 설명 (주요 매개변수):
prompt: 분석하고자 하는 핵심 문장입니다.max_n_logits: 모델이 다음으로 예측할 상위 몇 개의 토큰에 대한 정보를 분석할지 정합니다. 이 토큰들이 최종 '출력 노드'가 됩니다.desired_logit_prob: 상위max_n_logits중에서도, 예측 확률의 합이 이 값에 도달할 때까지만 중요한 것으로 간주합니다. 이를 통해 '가장 확실한' 예측 경로에 집중할 수 있습니다.max_feature_nodes: 생성될 그래프의 최대 특징 노드 수입니다. 이 값을 조절하여 시각화의 복잡성과 계산 시간을 조절할 수 있습니다.offload: 계산에 필요한 데이터를 GPU, CPU, 또는 디스크 중 어디에 저장할지 결정합니다. Colab 환경에서는 GPU 메모리가 제한적일 수 있으므로disk를 사용하는 것이 효율적입니다.

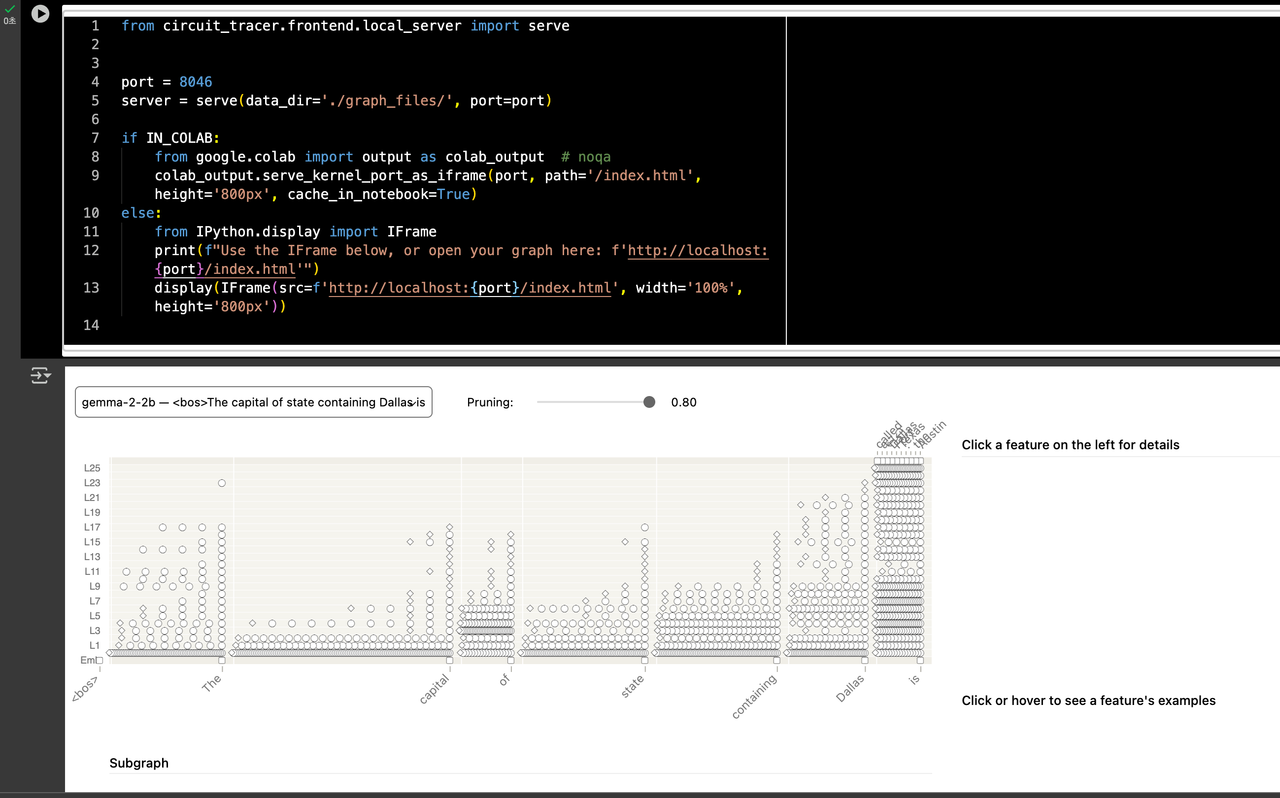
결과 확인: 위 코드를 실행하면, Colab 환경에서는 노트북 하단에 웹 페이지가 iframe 형태로 로드되고, 로컬 환경에서는 웹 브라우저로 접속할 수 있는 URL이 출력됩니다. 이제 시각화된 Circuit Graph를 통해 AI 모델의 내부 작동을 탐색할 수 있습니다!
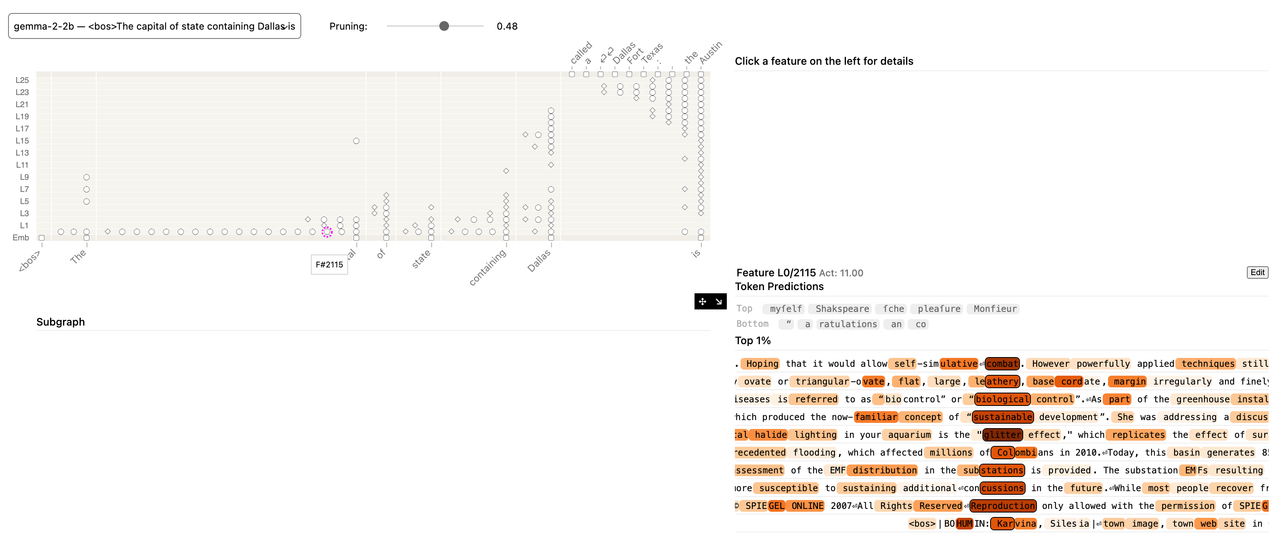
(pruning 0.48) 임의 노드 클릭
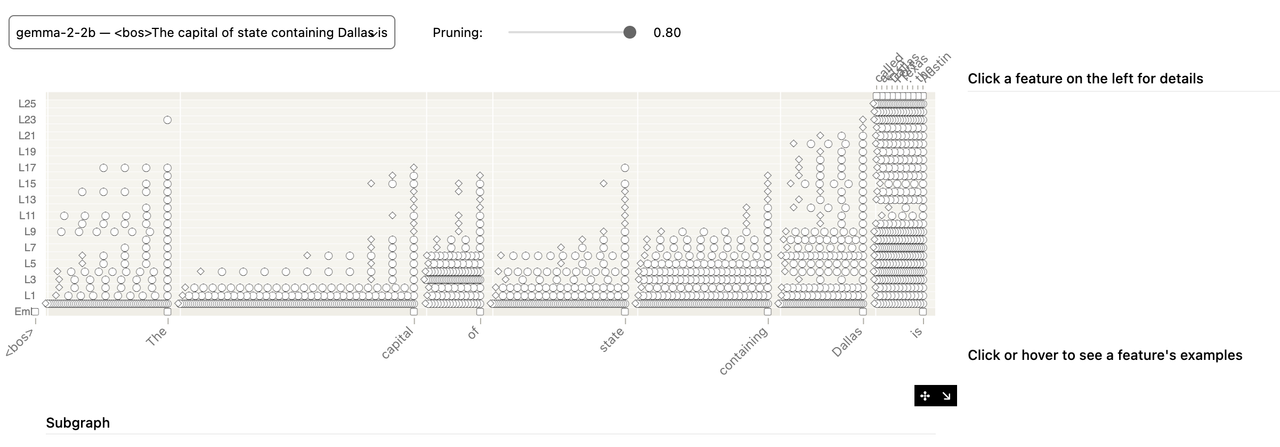
(pruning 0.80)

(pruning 0.80) - 임의 노드 클릭
Attribution Graph의 구조 이해하기: AI의 '뇌 지도' 구성 요소
Attribution Graph는 AI 모델의 복잡한 신경망을 단순화하여 보여주는 '뇌 지도'와 같습니다. 이 지도에는 크게 세 가지 유형의 구성 요소가 있습니다.
노드(Nodes): 그래프의 '점'들을 의미합니다. 각 점은 AI 모델 내부에서 활성화되는 특정 정보 단위를 나타냅니다.
입력 토큰 노드:
The,capital,Dallas등 우리가 입력한 프롬프트의 각 단어를 나타냅니다. 모델의 정보 처리 시작점입니다.특징(Feature) 노드: AI 모델 내부에서 특정 개념이나 패턴에 반응하는 '사고 단위'입니다. 예를 들어,
Dallas와 관련된 지리 정보,capital과 관련된 도시 정보 등을 담당하는 특징들이 활성화될 수 있습니다. 이 특징들은 AI 모델의 여러 레이어(L0, L1, L2...L25 등)에 걸쳐 존재합니다.오류(Error) 노드: 대체 모델(Replacement Model)이 원본 모델의 작동을 완벽하게 재현하지 못할 때 발생하는 '설명되지 않은 부분'을 나타냅니다. 마치 회로도에서 알 수 없는 에너지가 튀어나오는 부분이라고 생각할 수 있습니다.
출력(Output) 노드 (Logit Node): 모델이 최종적으로 예측하는 다음 단어(예: Austin)를 나타냅니다. 모델의 최종 결정 지점입니다.
엣지(Edges): 노드들 사이의 '선'들을 의미합니다. 각 선은 한 노드에서 다른 노드로 정보가 얼마나 강력하게 전달되는지(영향력)를 나타내는 가중치(weight)를 가집니다. 선의 두께나 색깔로 영향력의 크기를 시각적으로 표현하기도 합니다.
레이어(Layers): 세로축은 AI 모델의 '깊이'를 나타내는 레이어(L0, L1, ...)입니다. 낮은 레이어(L0)는 입력에 가깝고, 높은 레이어(L25)는 출력에 가깝습니다. 정보는 일반적으로 낮은 레이어에서 높은 레이어로 흐르며 점차 추상적이고 복합적인 의미로 변환됩니다.
2. 그래프 분석의 핵심: Pruning (가지치기)의 역할
AI 모델의 내부는 상상 이상으로 복잡합니다. 아무리 특징(Feature) 단위로 단순화해도, 모든 노드와 엣지를 한눈에 파악하기는 어렵습니다. 그래서 우리는 'Pruning(가지치기)'라는 기법을 사용하여 그래프를 단순화합니다.
Pruning의 목적: 최종 출력(예측 단어)에 미치는 영향력이 낮은 노드와 엣지를 제거하여, 정보의 손실을 최소화하면서 가장 중요한 핵심 경로만 보여주는 것입니다.
슬라이더 값의 의미 (예: 0.80): 이미지에서 'Pruning: 0.80'은 "최종 로짓(예측 단어)에 미치는 전체 영향력의 80%를 차지하는 노드들만 그래프에 남기겠다"는 의미입니다.
값이 낮을수록: 더 많은 노드가 제거되어 그래프가 매우 단순해지지만, 중요한 정보의 일부를 놓칠 수 있습니다. (이전 글의 0.48 Pruning 그래프가 그 예시입니다. 특정 특징의 예측 단어가 질문과 무관했던 이유도 너무 많은 가지치기로 인해 문맥 파악에 특화된 특징이 가려졌을 가능성 때문입니다.)
값이 높을수록: 더 많은 노드가 포함되어 상세한 정보를 볼 수 있지만, 그래프가 복잡해져 해석하기 어려울 수 있습니다. (현재 0.80 Pruning 그래프처럼요.)
인사이트: Pruning은 AI 모델의 작동 원리를 이해하는 데 있어 '정보의 밀도 조절'과 같습니다. 어떤 임계값으로 가지치기를 하느냐에 따라 AI가 어떤 '핵심 정보'를 중요하게 여기는지를 달리 볼 수 있습니다. 0.48일 때는 너무 넓게 가지치기 되어 'Dallas'의 핵심 의미가 가려졌지만, 0.80으로 높였을 때는 'Dallas'가 최종 예측에 어떻게 연결되는지 더 명확하게 파악할 수 있었죠.
3. 'The capital of state containing Dallas is' 그래프 상세 분석
이제 실제 그래프 이미지를 보면서 주요 특징과 인사이트를 도출해 봅시다.
3.1. 전반적인 점들의 밀집도와 패턴 (Pruning: 0.80 기준)
밀집도 증가: 0.48 Pruning 때보다 훨씬 많은 점들이 보입니다. 이는 80%의 영향력을 유지하기 위해 더 많은 노드와 연결이 포함되었기 때문입니다.
초기 레이어 (
L0~L5):The,capital,of등 문장의 시작 부분 단어들 아래에 점들이 밀집되어 있습니다. 이 영역에서는 각 단어의 기본적인 의미, 문법적 역할 등을 파악하는 과정이 활발히 일어남을 시사합니다.<bos>(문장 시작) 토큰도 초기 레이어에서 활발하게 작동하는 것을 볼 수 있습니다.중간 레이어 (
L5~L15):state,containing단어와 관련된 점들이 나타나기 시작합니다. 문장의 구조와 의미를 연결하는 작업이 진행되는 단계로 보입니다.후반부 레이어 (
L15~L25):Dallas와is토큰의 중요성 부각: 가장 두드러지는 특징은Dallas와is토큰 아래에 가장 높은 레이어(L20~L25)에까지 매우 많은 점들이 밀집되어 있다는 것입니다. 특히Dallas는 거의 모든 레이어에 걸쳐 활발하게 정보를 처리하며, 최상위 레이어까지 그 영향이 이어지는 것으로 보입니다.오른쪽 상단의 예측 단어들:
Austin,Springfield,Sacramento등is다음으로 올 '수도' 이름들이 가장 높은 레이어에 집중적으로 활성화되어 있습니다. 이는 모델이Dallas라는 단어를 통해 '텍사스 주'를 연상하고, 'capital of state'라는 질문의 맥락에 맞춰 '수도'를 예측하기 위해 관련 정보를 최종적으로 종합하고 있음을 강력히 시사합니다.
인사이트: AI 모델은 "The capital of state containing Dallas is"라는 문장을 처리할 때, Dallas라는 핵심 정보를 초기부터 최종 예측까지 꾸준히 활성화하고, capital of state is라는 문맥을 통해 '수도'라는 최종 예측으로 수렴하는 명확한 정보 처리 파이프라인을 가지고 있음을 보여줍니다. 즉, 모델은 입력 단어들을 단순 암기하는 것이 아니라, 내부적으로 지식을 활성화하고 문맥과 연결하여 추론하는 과정을 거친다는 것을 시각적으로 증명합니다.
3.2. 특정 특징(Feature) 노드 상세 분석 (FW1551 예시)
세 번째 이미지에서 FW1551 (실제로는 Feature L0195651) 노드가 선택되어 우측 패널에 상세 정보가 표시되었습니다.
위치:
L18레이어(L019는 19번 레이어)에 위치한 이 노드는 모델의 상당히 후반부에 해당합니다.Token Predictions: 이 특징이 활성화되었을 때, AI가 다음으로 예측하는 단어들은felvek,folf,safe등으로, 질문과는 직접적인 관련이 없어 보였습니다.Top Activations텍스트: 이 특징이 실제로 반응하는 텍스트는 "항공편 취소율 시뮬레이션"에 대한 내용이었습니다. "1.5 percent", "50 trials", "probability of success 0.015" 등 수량, 확률과 관련된 정보가 많았습니다.
인사이트: 이 결과는 AI 모델 내부의 '특징'이 우리가 생각하는 것보다 훨씬 더 다목적적(General-purpose)으로 작동할 수 있음을 보여줍니다. 즉, FW1551 같은 특징은 '특정 지리적 개념'에만 반응하는 것이 아니라, 문장에서의 '수량', '확률', '시뮬레이션'과 같은 추상적인 개념이나 계산적 패턴에 반응하는 특징일 수 있습니다. 'Dallas' 관련 질문에서 활성화되었지만, 이는 containing과 Dallas 사이의 문맥적 연결(예: '댈러스가 포함된'이라는 개념)에 반응한 것일 수 있으며, 직접적인 '수도' 예측보다는 더 추상적인 중간 단계의 정보 처리 역할을 담당했을 가능성이 높습니다. 이는 AI가 단편적인 지식뿐만 아니라, 추상적인 패턴 인식 능력도 활용한다는 점을 시사합니다.
4. 프롬프트 엔지니어링 관점에서의 의미
Circuit Tracing은 프롬프트 엔지니어링에 다음과 같은 중요한 의미를 부여합니다.
투명성 확보 및 디버깅: AI가 특정 답변을 내놓는 '이유'를 시각적으로 보여줍니다. 만약 AI가 엉뚱한 답변을 했다면, 그래프를 통해 어떤 특징이 잘못 활성화되었거나 어떤 정보가 제대로 연결되지 않았는지 파악하여 모델을 디버깅하고 개선하는 데 활용할 수 있습니다.
핵심 키워드 및 컨텍스트의 중요성 재확인:
Dallas처럼 질문의 핵심 키워드가 AI의 최종 예측까지 지속적으로 중요하게 처리되는 것을 볼 수 있습니다. 이는 프롬프트를 작성할 때 핵심 정보와 풍부한 컨텍스트를 명확히 제공하는 것이 AI의 정확한 이해를 돕는다는 프롬프트 엔지니어링의 기본 원칙을 시각적으로 뒷받침합니다.AI의 '사고 방식' 이해: AI가 단순히 단어들을 나열하는 것이 아니라, 레이어를 거치며 정보를 계층적으로 처리하고, 추상적인 패턴을 인식하며, 관련 지식을 연결하는 복잡한 추론 과정을 거친다는 것을 보여줍니다. 이는 AI가 어떤 방식으로 '생각'하는지에 대한 우리의 이해를 심화시킵니다.
고급 프롬프트 전략 개발: AI의 내부 작동 방식을 이해함으로써, 특정 특징을 더 잘 활성화하거나 원치 않는 특징을 억제하는 방식의 더 정교하고 효과적인 프롬프트 작성 전략을 개발할 수 있는 기반을 마련합니다.
Circuit Tracing의 기술적 배경: 'Replacement Model'과 'Attribution Graph'의 심층 이해
Anthropic의 연구는 LLM의 복잡한 내부를 이해하기 위해 몇 가지 혁신적인 방법을 사용합니다.
해석 가능한 대체 모델(Interpretable Replacement Model) 구축
문제점: 기존 LLM의 '뉴런'은 여러 의미를 동시에 나타내거나(Polysemantic), 하나의 의미가 여러 뉴런에 분산되어(Superposition) 해석하기 어렵습니다.
해결책: Cross-Layer Transcoder (CLT) 도입:
CLT 아키텍처: 모델의 각 레이어에 걸쳐 정보를 읽고(인코더) 그 정보를 다른 레이어의 출력에 기여(디코더)할 수 있는 'Cross-Layer' 특징을 사용합니다. 이는 마치 AI가 여러 층에 걸쳐서도 '하나의 통일된 생각'을 처리하는 것을 모방합니다.
학습 목표: CLT는 원본 LLM의 MLP(Multi-Layer Perceptron) 블록 출력을 최대한 정확하게 재구성하도록 학습됩니다. 동시에 '희소성(Sparsity)' 페널티를 부여하여, 활성화되는 특징의 수를 최소화하고 각 특징이 더 명확한 의미를 가지도록 합니다.
Replacement Model: 학습된 CLT 특징들이 원본 LLM의 MLP 뉴런을 '대체'합니다. 이렇게 구축된 모델은 원본 모델과 거의 동일한 출력을 내면서도, 내부의 정보 흐름은 훨씬 더 해석하기 쉬운 '특징' 단위로 이루어집니다.
프롬프트별 귀속 그래프(Attribution Graph) 생성
목표: 특정 프롬프트에 대한 모델의 계산 과정을 '인과 그래프(Causal Graph)'로 시각화합니다.
노드 유형:
출력 노드: 모델이 예측한 상위 10개 토큰 중 95% 확률 질량을 차지하는 토큰들.
중간 노드: 활성화된 CLT 특징들 (각 토큰 위치 및 레이어별).
기본 입력 노드: 프롬프트 토큰의 임베딩(Embedding).
추가 입력 노드 ('오류 노드'): CLT가 원본 MLP 출력을 설명하지 못한 부분. (이것이 바로 '다크 매터'입니다.)
엣지(영향력 계산): 노드 간의 엣지는 '직접적이고 선형적인 귀속(Direct, Linear Attributions)'을 나타냅니다. 이는 소스 특징의 활성화가 타겟 특징의 활성화에 미치는 영향을 의미하며, 주의(Attention) 패턴과 정규화는 고정된 상태에서 계산됩니다. 복잡한 수학적 계산(Jacobian 이용)을 통해 효율적으로 이루어집니다.
Pruning (가지치기): 생성된 그래프는 여전히 방대할 수 있으므로, 최종 출력에 가장 큰 영향을 미치는 노드와 엣지만 남겨 그래프를 단순화합니다.
Circuit Tracing의 한계점과 미래 연구 방향
이 강력한 도구에도 아직 한계점은 명확합니다.
1. 누락된 어텐션 회로(Missing Attention Circuits):
문제: 현재 Circuit Tracing은 '어텐션 패턴(Attention Patterns)'이 어떻게 형성되는지(
QK-circuit또는 Query-Key circuit)를 설명하지 않습니다. 오직 고정된 어텐션 출력이 특징 간 상호작용에 어떻게 영향을 미치는지(OV-circuit또는 Output-Value circuit)만 보여줍니다.결과: AI가 '왜 특정 단어에 주목했는지'와 같은 중요한 추론 과정(예: 다지선다 문제에서 정답을 고르는 과정)을 설명하지 못하고, 단지 '그 단어 때문에 답이 나왔다'고만 보여줄 수 있습니다.
미래: 어텐션 레이어에 대한 딕셔너리 학습(dictionary learning)이나 대체 헤드(replacement heads)를 통해 QK-circuit을 해석하는 방법이 필요합니다.
2. 재구성 오류 및 '다크 매터'(Reconstruction Errors & Dark Matter):
문제: CLT는 원본 모델의 활성화를 완벽하게 재구성하지 못합니다. 이 '설명되지 않은 부분'은 그래프에서 '오류 노드'로 나타나며, 모델의 작동 방식 중 여전히 '어두운 부분'으로 남아 있습니다.
결과: 특히 모델이 학습 데이터 분포에서 벗어난(Out-of-Distribution) 프롬프트를 받으면, 오류 노드가 압도적으로 많아져 그래프가 무용지물이 될 수 있습니다.
미래: 대체 모델의 크기 확대, 아키텍처 개선, 학습 방식 최적화, 그리고 오류 노드로부터도 역으로 귀속(attribution)하는 방법 등이 연구될 수 있습니다.
3. 비활성 특징 및 억제 회로(Inactive Features & Inhibitory Circuits)의 역할:
문제: 현재 그래프는 '활성화된' 특징만을 보여줍니다. 하지만 특정 특징이 '비활성화'되거나 다른 특징에 의해 '억제'되는 것이 모델의 결정에 중요할 수 있습니다 (예: 유해한 요청을 거부하는 회로).
결과: '왜 특정 행동을 하지 않았는가'를 설명하기 어렵습니다.
미래: '반사실적(Counterfactual)' 분석이나 '대조 쌍(Contrastive Pairs)' 전략을 통해 비활성 특징의 중요성을 탐색하고, 억제적 상호작용을 포착하는 방법이 필요합니다.
4. 그래프 복잡성:
문제: 가지치기를 해도 수백 개의 노드와 수천 개의 엣지는 여전히 복잡하며, 하나의 개념이 여러 특징에 분산되거나(Feature Splitting), 여러 특징이 하나의 개념을 흡수하는(Feature Absorption) 문제도 발생합니다.
결과: 그래프를 통해 얻은 메커니즘을 간결한 이야기로 요약하기 어렵습니다.
미래: 더 나은 추상화, 정교한 가지치기, 시각화 도구 개선, 그리고 '계층적 특징(Hierarchical Features)' 학습(Matryoshka variants) 등이 필요합니다.
3. 초보자를 위한 프롬프트 작성 요령: AI의 '생각'을 유도하는 법
Circuit Tracing 연구는 AI의 내부를 들여다봄으로써, 우리가 AI와 더 효과적으로 소통하기 위한 중요한 단서들을 제공합니다. 특히 프롬프트 엔지니어링 관점에서 다음과 같은 요령을 제안할 수 있습니다.
핵심 원리: AI의 '생각 회로'를 명확하게, 풍부하게, 그리고 단계적으로 활성화시키기
명확한 목표와 질문 명시:
Circuit Insight: AI는 'Dallas'라는 키워드처럼 핵심 정보를 포착하고, 이를 바탕으로 최종 예측을 만듭니다.
Prompt Tip: 애매모호한 요청은 AI를 헤매게 합니다. "이것이 해결하려는 핵심 문제는 무엇인가요?", "궁극적인 목표는 무엇인가요?", "내가 원하는 출력 형식은 무엇인가요?"를 프롬프트에 구체적으로 명시하세요.
예시: ❌ "웹 페이지 만들어줘." ➡️ ✅ "사용자들이 일기를 쓰고 공유하는 간단한 웹 앱을 Node.js와 Express, MongoDB를 사용해서 만들어줘. 사용자 인증, 일기 작성, 공개/비공개 설정 기능이 포함되어야 해."
풍부한 컨텍스트(Context) 제공:
Circuit Insight: AI는 여러 레이어에 걸쳐 문맥을 파악하고 관련 특징들을 활성화시킵니다.
Prompt Tip: AI가 필요한 정보(데이터, 환경, 제약사항, 배경 지식)를 충분히 제공하세요. AI가 '어떤 상황'에서 '무엇'을 해야 하는지 명확히 알도록 돕습니다.
예시: ❌ "코드 고쳐줘." ➡️ ✅ "Python Flask 앱에서 로그인 기능이 작동하지 않아. 데이터베이스는 SQLite를 사용하고 있고,
login_user함수에서AttributeError가 발생해. 관련 코드 스니펫과 정확한 오류 메시지는 다음과 같아. 예상되는 동작은 로그인 성공 후 대시보드로 리다이렉트 되는 거야."
복잡한 작업은 단계별로 분해(Break Down Complex Tasks):
Circuit Insight: AI는 복잡한 추론을 여러 단계의 특징 활성화와 연결을 통해 수행합니다. 한 번에 너무 많은 것을 요청하면 '생각 회로'가 엉킬 수 있습니다.
Prompt Tip: 큰 기능을 작은 단위로 나누어 요청하고, 각 단계의 결과물을 확인하며 다음 단계를 진행합니다.
예시: ❌ "쇼핑몰 전체를 만들어줘." ➡️ ✅ "1단계: 사용자 회원가입 및 로그인 기능 구현. 2단계: 상품 목록 페이지 구현. 3단계: 장바구니 기능 구현..."
역할 부여(Leverage Roles/Personas):
Circuit Insight: AI는 특정 역할을 부여받았을 때 그 역할에 맞는 지식과 추론 방식을 활성화하는 경향이 있습니다.
Prompt Tip: AI에게 "당신은 [역할]이야"라고 명시하여, AI가 특정 관점과 전문성을 가지고 답변하도록 유도합니다.
예시: ✅ "당신은 시니어 React 개발자입니다. 다음 코드를 보고 성능 최적화 관점에서 리뷰해주세요."
예시 (Input/Output Examples) 포함:
Circuit Insight: AI는 패턴을 학습하는 데 탁월합니다. 구체적인 예시는 AI가 어떤 '특징'을 활성화해야 하는지 명확히 보여줍니다.
Prompt Tip: 원하는 입력과 출력의 예시를 제공하여, AI가 올바른 패턴을 파악하도록 돕습니다.
예시: "다음 텍스트를 JSON 형식으로 변환해주세요. 입력: '이름: 김철수, 나이: 30, 직업: 개발자'. 출력:
{'name': '김철수', 'age': 30, 'job': '개발자'}"
가지치기(Pruning)처럼 핵심에 집중하도록 유도:
Circuit Insight: AI도 중요한 정보에 집중해야 더 효율적으로 작동합니다.
Prompt Tip: 현재 단계에서 가장 중요한 정보만 제공하고, 불필요한 정보는 제외하여 AI가 핵심 과제에 집중하도록 합니다.
예시: "지금은 UI 구현에 집중해볼까요? 데이터베이스 스키마는 나중에 논의해도 좋습니다."
마무리하며: AI와 함께 성장하는 Vibe Coder의 여정
Anthropic의 Circuit Tracing 연구는 LLM의 내부를 이해하고, 이를 통해 AI의 신뢰성, 설명 가능성, 그리고 통제 가능성을 높이려는 중요한 발걸음입니다. 비록 아직 많은 한계점이 존재하지만, 이 연구는 우리가 AI를 '블랙박스'가 아닌, 탐험하고 이해할 수 있는 복잡한 계산 시스템으로 바라보게 합니다.
프롬프트 엔지니어링은 이러한 AI의 '뇌 구조'에 대한 이해를 바탕으로, 우리가 AI와 더욱 정교하게 소통하고 원하는 결과를 얻어내는 '언어'를 배우는 과정입니다. 오늘 제안 드린 요령들은 AI의 '생각 회로'를 활성화하고, AI가 우리의 의도를 더 정확히 파악하도록 돕는 기본적인 프롬프트 엔지니어링 전략들입니다.
여러분도 이 Circuit Tracing 도구를 직접 실험해보고, 자신만의 프롬프트로 AI의 '생각'을 엿보며 AI와 함께 성장하시기 바랍니다.