LlamaIndex와 Streamlit으로 온프레미스 RAG 챗봇 구축하기: PDF·CSV·DOCX 문서 실시간 답변 및 데이터 보안 완벽 가이드
RAG 챗봇 구축 가이드: LlamaIndex와 Streamlit으로 혁신을!
안녕하세요, 오늘은 여러분의 비즈니스에 혁신을 가져올 수 있는 RAG(Retrieval-Augmented Generation) 챗봇을 구축하는 방법을 소개합니다. 이 챗봇은 LlamaIndex와 Streamlit을 활용해 PDF, CSV, Markdown, DOCX, JSON 등 다양한 문서에서 정보를 추출하고, 사용자 질문에 실시간으로 답변합니다. 게다가, 모든 작업이 온프레미스 환경에서 이루어져 데이터 보안까지 철저히 지킬 수 있죠.
이 글에서는 초보 개발자도 쉽게 따라 할 수 있도록 설치부터 최적화까지 모든 단계를 상세히 다룹니다.
흥미진진한 여정을 준비했으니 끝까지 함께해 주세요!
왜 RAG 챗봇인가?
일반적인 챗봇은 사전 학습된 데이터에만 의존해 답변을 내놓지만, RAG 챗봇은 한 단계 더 나아갑니다. 외부 문서에서 최신 정보를 검색해 더 정확하고 신뢰할 수 있는 답변을 제공하죠. 예를 들어, 회사 매뉴얼이나 고객 데이터베이스를 실시간으로 활용해 질문에 답할 수 있습니다. 비즈니스에서 민감한 데이터를 다룰 때, 온프레미스 환경에서 실행된다는 점은 마치 방탄 유리로 데이터를 보호하는 것과 같습니다
안전하고 안심할 수 있죠!
준비물: 무엇이 필요한가?
본격적인 여정을 시작하기 전에, 아래 준비물을 챙겨주세요:
운영체제: Windows, macOS, Linux 어디든 OK!
Python: 3.8 이상 (3.10 추천).
하드웨어: 최소 8GB RAM (16GB 권장), GPU가 있다면 금상첨화.
텍스트 에디터: VS Code나 PyCharm 같은 편리한 도구.
테스트 문서: PDF, CSV, Markdown, DOCX, JSON 파일 각각 1개씩.
예:
sample.pdf(회사 매뉴얼),data.csv(고객 데이터),notes.md(노트),report.docx(보고서),config.json(설정 파일).
단계별 가이드: A-Z까지 완벽하게
1. Python 및 가상환경 설정
먼저, 작업 환경을 깔끔하게 정리할 가상환경을 만듭니다. 의존성 충돌을 방지하는 이 단계는 마치 요리 전에 주방을 정리하는 것과 같아요.
Python 설치: python.org에서 다운로드.
가상환경 생성:
mkdir llama_index_rag cd llama_index_rag python -m venv venv활성화:
Windows:
venvScriptsactivatemacOS/Linux:
source venv/bin/activate
2. 필수 패키지 설치
이제 필요한 도구들을 설치합니다. LlamaIndex와 Streamlit을 포함한 라이브러리들이 우리의 챗봇을 완성할 핵심 재료예요.
pip install llama-index llama-index-llms-llama-cpp llama-index-embeddings-huggingface llama-index-vector-stores-faiss pymupdf streamlit python-docx pandas markdown3. 로컬 LLM 설정: Llama.cpp
온프레미스에서 LLM을 돌리기 위해 Llama.cpp를 활용합니다. 외부 서버 없이도 강력한 성능을 발휘할 수 있어요.
설치:
pip install llama-cpp-python모델 다운로드: Hugging Face에서
ggml-model-Q4_0.gguf를 받아옵니다.저장:
models/llama-2-7b-chat.gguf로 프로젝트 폴더에 저장.
4. 문서 준비
테스트용 문서를 docs 폴더에 준비합니다. 이 문서들은 챗봇이 학습할 교과서 같은 존재죠.
sample.pdf: 회사 매뉴얼.data.csv: 고객 데이터 (Name, Email, Purchase).notes.md: 프로젝트 노트.report.docx: 프로젝트 보고서.config.json: 설정 데이터.
5. RAG 챗봇 구축: 코드로 보는 마법
이제 본격적으로 챗봇을 만들어봅시다! 아래 코드는 Streamlit UI와 함께 다양한 문서를 처리하며, 대화 기록까지 표시합니다.
📁 프로젝트 구조
rag_chatbot_optimized/
├── app.py # 메인 Streamlit 애플리케이션
├── config/
│ ├── __init__.py # 설정 모듈 export, 메타데이터
│ └── settings.py # 설정 관리
├── core/
│ ├── __init__.py # 핵심 클래스 export, 초기화 로직
│ ├── document_manager.py # 문서 관리 및 변경 감지
│ ├── index_manager.py # 인덱스 생성/로드/업데이트
│ └── embedding_cache.py # 임베딩 캐시 관리
├── loaders/
│ ├── __init__.py # 로더 클래스 export, 형식 지원 정보
│ └── custom_loaders.py # 커스텀 문서 로더
├── utils/
│ ├── __init__.py # 유틸리티 함수 export, 로깅 설정
│ ├── file_utils.py # 파일 유틸리티
│ └── performance_monitor.py # 성능 모니터링
├── storage/ # 인덱스 저장소
├── docs/ # 문서 디렉토리
├── models/ # LLM 모델 파일
├── requirements.txt
└── README.md📁 RAG 챗봇 프로젝트 구조 시각화
🎨 색상 코딩 가이드
🔵 파란색: 디렉토리/폴더
🟣 보라색: 핵심 Python 모듈
🟠 주황색: 설정 및 문서 파일
🟢 초록색: 저장소 디렉토리
🔸 핑크색:
__init__.py파일
📁 모듈간 의존성
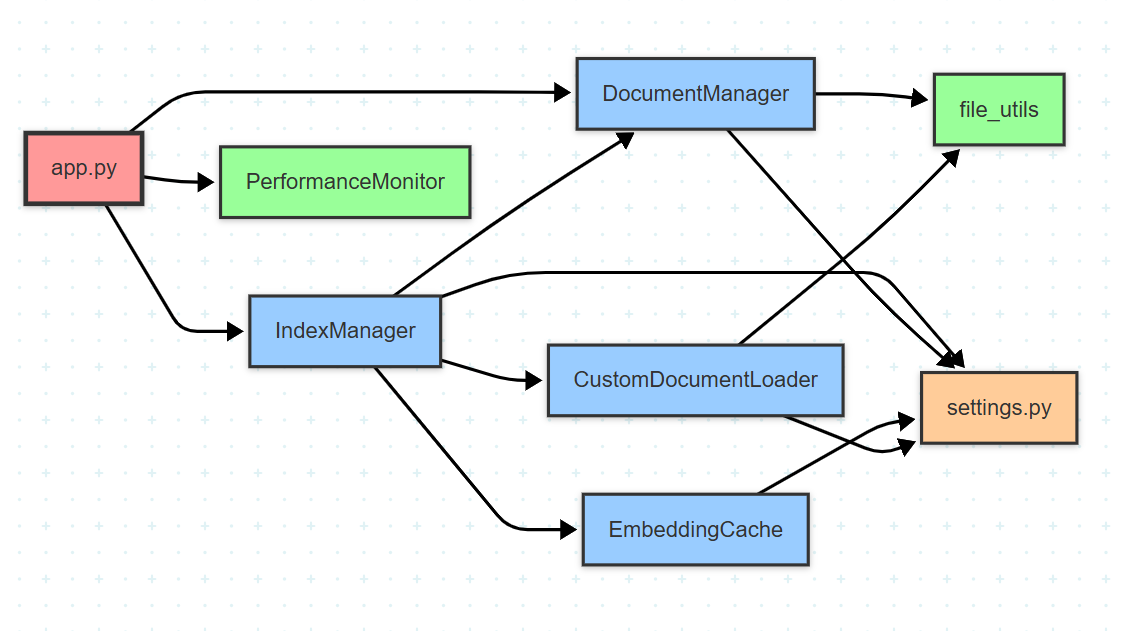
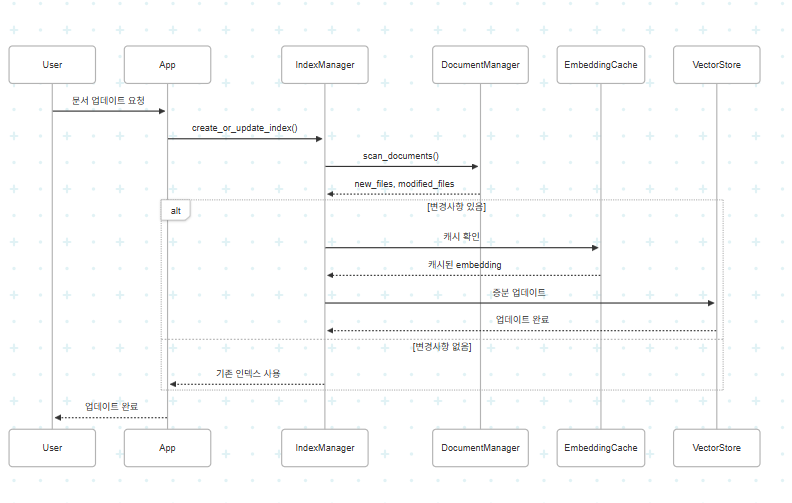
📊 데이터 흐름 다이어그램
🚀 코드
/config/__init__.py
"""
설정 관리 패키지
이 패키지는 애플리케이션의 전역 설정과 상수를 관리합니다.
Example:
from config import settings
print(settings.CHUNK_SIZE)
# 또는
from config.settings import CHUNK_SIZE, STORAGE_DIR
"""
# 주요 설정 모듈에서 자주 사용되는 상수들을 패키지 레벨로 가져옴
from .settings import (
# 경로 설정
BASE_DIR,
DOCS_DIR,
STORAGE_DIR,
MODELS_DIR,
CACHE_DIR,
# 인덱싱 설정
CHUNK_SIZE,
CHUNK_OVERLAP,
SIMILARITY_TOP_K,
# 벡터 저장소 설정
EMBEDDING_DIM,
FAISS_NLIST,
FAISS_NPROBE,
# LLM 설정
LLM_MODEL_PATH,
LLM_TEMPERATURE,
LLM_MAX_NEW_TOKENS,
LLM_CONTEXT_WINDOW,
# 지원 파일 형식
SUPPORTED_EXTENSIONS,
)
# 패키지 메타데이터
__version__ = "1.0.0"
__author__ = "RAG Chatbot Team"
__description__ = "Configuration management for RAG Chatbot"
# 공개 API 정의
__all__ = [
"BASE_DIR",
"DOCS_DIR",
"STORAGE_DIR",
"MODELS_DIR",
"CACHE_DIR",
"CHUNK_SIZE",
"CHUNK_OVERLAP",
"SIMILARITY_TOP_K",
"EMBEDDING_DIM",
"FAISS_NLIST",
"FAISS_NPROBE",
"LLM_MODEL_PATH",
"LLM_TEMPERATURE",
"LLM_MAX_NEW_TOKENS",
"LLM_CONTEXT_WINDOW",
"SUPPORTED_EXTENSIONS",
]/config/settings.py
python"""
애플리케이션 설정 관리
전역 변수와 상수를 중앙화하여 관리
"""
import os
from pathlib import Path
# 기본 경로 설정
BASE_DIR = Path(__file__).parent.parent
DOCS_DIR = BASE_DIR / "docs"
STORAGE_DIR = BASE_DIR / "storage"
MODELS_DIR = BASE_DIR / "models"
CACHE_DIR = BASE_DIR / ".cache"
# 인덱싱 설정
CHUNK_SIZE = 256
CHUNK_OVERLAP = 50
SIMILARITY_TOP_K = 2
# 벡터 저장소 설정
EMBEDDING_DIM = 384 # all-MiniLM-L6-v2 차원
FAISS_NLIST = 100
FAISS_NPROBE = 10
# LLM 설정
LLM_MODEL_PATH = MODELS_DIR / "llama-2-7b-chat.gguf"
LLM_TEMPERATURE = 0.7
LLM_MAX_NEW_TOKENS = 512
LLM_CONTEXT_WINDOW = 2048
# 캐시 설정
DOCUMENT_CACHE_TTL = 3600 # 1시간
EMBEDDING_CACHE_SIZE = 1000
# 로깅 설정
LOG_LEVEL = "INFO"
LOG_FORMAT = "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
# 지원하는 파일 확장자
SUPPORTED_EXTENSIONS = {'.pdf', '.csv', '.md', '.docx', '.json'}/core/__init__.py
"""
핵심 RAG 시스템 패키지
이 패키지는 RAG 챗봇의 핵심 기능을 제공합니다:
- 문서 관리 및 변경 감지
- 인덱스 생성/로드/업데이트
- 임베딩 캐시 관리
Example:
from core import IndexManager, DocumentManager, EmbeddingCache
# 인덱스 매니저 초기화
index_manager = IndexManager()
index = index_manager.create_or_update_index()
# 문서 변경 감지
doc_manager = DocumentManager()
new_files, modified_files = doc_manager.scan_documents()
"""
# 핵심 클래스들을 패키지 레벨로 import
from .document_manager import DocumentManager
from .index_manager import IndexManager
from .embedding_cache import EmbeddingCache
# 패키지 초기화 시 로깅 설정
import logging
# 패키지 로거 설정
logger = logging.getLogger(__name__)
logger.info("Core RAG system package initialized")
# 패키지 메타데이터
__version__ = "1.0.0"
__author__ = "RAG Chatbot Team"
__description__ = "Core functionality for RAG chatbot system"
# 공개 API 정의 - 이 리스트의 클래스들만 'from core import *'로 가져올 수 있음
__all__ = [
"DocumentManager",
"IndexManager",
"EmbeddingCache",
]
# 패키지 레벨 상수
CORE_VERSION = "1.0.0"
SUPPORTED_OPERATIONS = [
"document_scan",
"index_creation",
"index_update",
"embedding_cache",
"performance_monitor"
]
# 패키지 레벨 설정
DEFAULT_INDEX_CONFIG = {
"chunk_size": 256,
"chunk_overlap": 50,
"similarity_top_k": 2
}
# 초기화 시 필요한 디렉토리 생성
def _ensure_directories():
"""필요한 디렉토리들이 존재하는지 확인하고 생성"""
from config import STORAGE_DIR, CACHE_DIR
import os
dirs_to_create = [STORAGE_DIR, CACHE_DIR]
for directory in dirs_to_create:
if not os.path.exists(directory):
os.makedirs(directory, exist_ok=True)
logger.info(f"Created directory: {directory}")
# 패키지 로드 시 디렉토리 확인
_ensure_directories()
# 패키지 레벨 유틸리티 함수
def get_core_info():
"""코어 패키지 정보 반환"""
return {
"version": __version__,
"description": __description__,
"supported_operations": SUPPORTED_OPERATIONS,
"default_config": DEFAULT_INDEX_CONFIG
}/core/document_manager.py
python"""
문서 변경 감지 및 관리 시스템
해시 기반 변경 감지로 불필요한 재처리 방지
"""
import hashlib
import json
import os
from datetime import datetime
from pathlib import Path
from typing import Dict, List, Set, Tuple
import logging
from config.settings import DOCS_DIR, CACHE_DIR
logger = logging.getLogger(__name__)
class DocumentManager:
"""문서 변경 감지 및 메타데이터 관리"""
def __init__(self, docs_dir: Path = DOCS_DIR):
self.docs_dir = Path(docs_dir)
self.cache_dir = Path(CACHE_DIR)
self.cache_dir.mkdir(exist_ok=True)
self.metadata_file = self.cache_dir / "document_metadata.json"
self.metadata = self._load_metadata()
def _load_metadata(self) -> Dict:
"""저장된 메타데이터 로드"""
if self.metadata_file.exists():
try:
with open(self.metadata_file, 'r', encoding='utf-8') as f:
return json.load(f)
except (json.JSONDecodeError, FileNotFoundError):
logger.warning("메타데이터 파일 손상, 새로 생성합니다.")
return {}
def _save_metadata(self):
"""메타데이터 저장"""
with open(self.metadata_file, 'w', encoding='utf-8') as f:
json.dump(self.metadata, f, ensure_ascii=False, indent=2)
def _get_file_hash(self, filepath: Path) -> str:
"""파일 해시값 계산 (MD5)"""
hash_md5 = hashlib.md5()
try:
with open(filepath, "rb") as f:
for chunk in iter(lambda: f.read(4096), b""):
hash_md5.update(chunk)
return hash_md5.hexdigest()
except Exception as e:
logger.error(f"파일 해시 계산 실패 {filepath}: {e}")
return ""
def scan_documents(self) -> Tuple[List[Path], List[Path], List[Path]]:
"""
문서 스캔 및 변경사항 감지
Returns:
(새 파일, 수정된 파일, 삭제된 파일)
"""
current_files = set()
new_files = []
modified_files = []
# 현재 디렉토리의 모든 지원 파일 스캔
for file_path in self.docs_dir.rglob("*"):
if file_path.is_file() and file_path.suffix in {'.pdf', '.csv', '.md', '.docx', '.json'}:
current_files.add(str(file_path))
# 파일 해시 확인
current_hash = self._get_file_hash(file_path)
file_key = str(file_path)
if file_key not in self.metadata:
# 새 파일
new_files.append(file_path)
self.metadata[file_key] = {
'hash': current_hash,
'last_modified': datetime.now().isoformat(),
'size': file_path.stat().st_size
}
elif self.metadata[file_key]['hash'] != current_hash:
# 수정된 파일
modified_files.append(file_path)
self.metadata[file_key].update({
'hash': current_hash,
'last_modified': datetime.now().isoformat(),
'size': file_path.stat().st_size
})
# 삭제된 파일 확인
stored_files = set(self.metadata.keys())
deleted_files = [Path(f) for f in stored_files - current_files]
# 삭제된 파일 메타데이터 제거
for deleted_file in deleted_files:
del self.metadata[str(deleted_file)]
# 메타데이터 저장
self._save_metadata()
logger.info(f"문서 스캔 완료 - 새 파일: {len(new_files)}, 수정됨: {len(modified_files)}, 삭제됨: {len(deleted_files)}")
return new_files, modified_files, deleted_files
def get_all_indexed_files(self) -> List[Path]:
"""인덱싱된 모든 파일 목록 반환"""
return [Path(f) for f in self.metadata.keys()]
def mark_as_indexed(self, file_path: Path):
"""파일을 인덱싱 완료로 표시"""
file_key = str(file_path)
if file_key in self.metadata:
self.metadata[file_key]['indexed_at'] = datetime.now().isoformat()
self._save_metadata()/core/embedding_cache.py
python"""
임베딩 결과 캐시 관리
중복 임베딩 계산 방지로 성능 최적화
"""
import pickle
import hashlib
from pathlib import Path
from typing import Any, Dict, List, Optional
import logging
from config.settings import CACHE_DIR, EMBEDDING_CACHE_SIZE
logger = logging.getLogger(__name__)
class EmbeddingCache:
"""임베딩 결과 캐시 관리 클래스"""
def __init__(self, cache_dir: Path = CACHE_DIR, max_size: int = EMBEDDING_CACHE_SIZE):
self.cache_dir = Path(cache_dir)
self.cache_dir.mkdir(exist_ok=True)
self.cache_file = self.cache_dir / "embedding_cache.pkl"
self.max_size = max_size
self.cache: Dict[str, Any] = self._load_cache()
def _load_cache(self) -> Dict[str, Any]:
"""캐시 파일 로드"""
if self.cache_file.exists():
try:
with open(self.cache_file, 'rb') as f:
cache = pickle.load(f)
logger.info(f"임베딩 캐시 로드 완료: {len(cache)}개 항목")
return cache
except Exception as e:
logger.error(f"캐시 로드 실패: {e}")
return {}
def _save_cache(self):
"""캐시 파일 저장"""
try:
with open(self.cache_file, 'wb') as f:
pickle.dump(self.cache, f)
logger.debug(f"캐시 저장 완료: {len(self.cache)}개 항목")
except Exception as e:
logger.error(f"캐시 저장 실패: {e}")
def _get_text_hash(self, text: str) -> str:
"""텍스트 해시값 생성"""
return hashlib.sha256(text.encode('utf-8')).hexdigest()[:16]
def get_embedding(self, text: str) -> Optional[List[float]]:
"""캐시에서 임베딩 조회"""
text_hash = self._get_text_hash(text)
return self.cache.get(text_hash)
def store_embedding(self, text: str, embedding: List[float]):
"""임베딩을 캐시에 저장"""
text_hash = self._get_text_hash(text)
# 캐시 크기 관리 (LRU 방식)
if len(self.cache) >= self.max_size:
# 가장 오래된 항목 제거
oldest_key = next(iter(self.cache))
del self.cache[oldest_key]
logger.debug("캐시 크기 초과, 오래된 항목 제거")
self.cache[text_hash] = embedding
# 주기적으로 캐시 저장 (10개마다)
if len(self.cache) % 10 == 0:
self._save_cache()
def clear_cache(self):
"""캐시 초기화"""
self.cache.clear()
if self.cache_file.exists():
self.cache_file.unlink()
logger.info("임베딩 캐시 초기화 완료")
def get_cache_stats(self) -> Dict[str, int]:
"""캐시 통계 정보"""
return {
'total_entries': len(self.cache),
'max_size': self.max_size,
'cache_file_exists': self.cache_file.exists()
}/core/index_manager.py
python"""
인덱스 생성, 로드, 증분 업데이트 관리
최적화된 인덱싱 전략으로 성능 향상
"""
import os
import time
from pathlib import Path
from typing import List, Optional
import logging
import faiss
from llama_index.core import VectorStoreIndex, Document, Settings, StorageContext, load_index_from_storage
from llama_index.vector_stores.faiss import FaissVectorStore
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from config.settings import (
STORAGE_DIR, CHUNK_SIZE, CHUNK_OVERLAP, EMBEDDING_DIM,
FAISS_NLIST, FAISS_NPROBE, SIMILARITY_TOP_K
)
from core.document_manager import DocumentManager
from core.embedding_cache import EmbeddingCache
from loaders.custom_loaders import CustomDocumentLoader
logger = logging.getLogger(__name__)
class IndexManager:
"""인덱스 생성 및 관리 클래스"""
def __init__(self, storage_dir: Path = STORAGE_DIR):
self.storage_dir = Path(storage_dir)
self.storage_dir.mkdir(exist_ok=True)
# 컴포넌트 초기화
self.doc_manager = DocumentManager()
self.embedding_cache = EmbeddingCache()
self.loader = CustomDocumentLoader()
# 설정 적용
Settings.chunk_size = CHUNK_SIZE
Settings.chunk_overlap = CHUNK_OVERLAP
# 인덱스 상태
self._index: Optional[VectorStoreIndex] = None
self._embed_model: Optional[HuggingFaceEmbedding] = None
def _get_embed_model(self) -> HuggingFaceEmbedding:
"""임베딩 모델 로드 (lazy loading)"""
if self._embed_model is None:
logger.info("임베딩 모델 로드 중...")
start_time = time.time()
self._embed_model = HuggingFaceEmbedding(
model_name="sentence-transformers/all-MiniLM-L6-v2"
)
logger.info(f"임베딩 모델 로드 완료: {time.time() - start_time:.2f}초")
return self._embed_model
def _create_vector_store(self) -> FaissVectorStore:
"""FAISS 벡터 저장소 생성"""
# IVF (Inverted File) 인덱스 생성으로 빠른 검색
quantizer = faiss.IndexFlatL2(EMBEDDING_DIM)
faiss_index = faiss.IndexIVFFlat(quantizer, EMBEDDING_DIM, FAISS_NLIST)
faiss_index.nprobe = FAISS_NPROBE
return FaissVectorStore(faiss_index=faiss_index)
def _load_existing_index(self) -> Optional[VectorStoreIndex]:
"""기존 인덱스 로드"""
try:
if not (self.storage_dir / "docstore.json").exists():
return None
logger.info("기존 인덱스 로드 중...")
start_time = time.time()
storage_context = StorageContext.from_defaults(persist_dir=str(self.storage_dir))
index = load_index_from_storage(
storage_context,
embed_model=self._get_embed_model()
)
logger.info(f"인덱스 로드 완료: {time.time() - start_time:.2f}초")
return index
except Exception as e:
logger.error(f"인덱스 로드 실패: {e}")
return None
def _create_new_index(self, documents: List[Document]) -> VectorStoreIndex:
"""새 인덱스 생성"""
logger.info(f"새 인덱스 생성 중... ({len(documents)}개 문서)")
start_time = time.time()
vector_store = self._create_vector_store()
embed_model = self._get_embed_model()
# 임베딩 캐시 활용한 인덱스 생성
index = VectorStoreIndex.from_documents(
documents,
vector_store=vector_store,
embed_model=embed_model,
show_progress=True
)
# 인덱스 저장
index.storage_context.persist(persist_dir=str(self.storage_dir))
logger.info(f"인덱스 생성 완료: {time.time() - start_time:.2f}초")
return index
def _update_index_incremental(self, index: VectorStoreIndex, new_documents: List[Document]) -> VectorStoreIndex:
"""증분 인덱스 업데이트"""
if not new_documents:
return index
logger.info(f"증분 인덱스 업데이트 중... ({len(new_documents)}개 문서)")
start_time = time.time()
# 새 문서를 기존 인덱스에 추가
for doc in new_documents:
index.insert(doc)
# 업데이트된 인덱스 저장
index.storage_context.persist(persist_dir=str(self.storage_dir))
logger.info(f"증분 업데이트 완료: {time.time() - start_time:.2f}초")
return index
def create_or_update_index(self, force_rebuild: bool = False) -> VectorStoreIndex:
"""
인덱스 생성 또는 업데이트
Args:
force_rebuild: 강제 재빌드 여부
Returns:
VectorStoreIndex: 생성/업데이트된 인덱스
"""
# 문서 변경사항 스캔
new_files, modified_files, deleted_files = self.doc_manager.scan_documents()
# 기존 인덱스 로드 시도
existing_index = None if force_rebuild else self._load_existing_index()
# 인덱스 생성/업데이트 전략 결정
if existing_index is None or deleted_files:
# 새 인덱스 생성 (삭제된 파일이 있거나 기존 인덱스 없음)
all_files = self.doc_manager.get_all_indexed_files()
if all_files:
documents = self.loader.load_documents(all_files)
self._index = self._create_new_index(documents)
else:
logger.warning("인덱싱할 문서가 없습니다.")
return None
elif new_files or modified_files:
# 증분 업데이트
files_to_update = new_files + modified_files
new_documents = self.loader.load_documents(files_to_update)
self._index = self._update_index_incremental(existing_index, new_documents)
# 인덱싱 완료 표시
for file_path in files_to_update:
self.doc_manager.mark_as_indexed(file_path)
else:
# 변경사항 없음
logger.info("문서 변경사항이 없어 기존 인덱스를 사용합니다.")
self._index = existing_index
return self._index
def get_query_engine(self, llm, similarity_top_k: int = SIMILARITY_TOP_K):
"""쿼리 엔진 생성"""
if self._index is None:
raise ValueError("인덱스가 생성되지 않았습니다. create_or_update_index()를 먼저 호출하세요.")
return self._index.as_query_engine(
llm=llm,
similarity_top_k=similarity_top_k
)
def get_index_stats(self) -> dict:
"""인덱스 통계 정보"""
if self._index is None:
return {"status": "인덱스 없음"}
# 벡터 저장소 통계
vector_store = self._index._vector_store
if hasattr(vector_store, '_faiss_index'):
faiss_index = vector_store._faiss_index
return {
"total_vectors": faiss_index.ntotal,
"dimension": faiss_index.d,
"is_trained": faiss_index.is_trained,
"indexed_files": len(self.doc_manager.get_all_indexed_files())
}
return {"status": "통계 정보 없음"}
def clear_index(self):
"""인덱스 및 캐시 초기화"""
logger.info("인덱스 및 캐시 초기화 중...")
# 인덱스 파일 삭제
if self.storage_dir.exists():
import shutil
shutil.rmtree(self.storage_dir)
self.storage_dir.mkdir(exist_ok=True)
# 캐시 초기화
self.embedding_cache.clear_cache()
# 인스턴스 변수 초기화
self._index = None
logger.info("초기화 완료")/loaders/__init__.py
"""
문서 로더 패키지
다양한 파일 형식을 지원하는 커스텀 문서 로더들을 제공합니다.
지원하는 파일 형식:
- PDF: 텍스트 추출 및 메타데이터 처리
- CSV: 선택적 컬럼 처리
- Markdown: HTML 변환 후 처리
- DOCX: 문단 및 스타일 정보 추출
- JSON: 구조화된 데이터 처리
Example:
from loaders import CustomDocumentLoader
loader = CustomDocumentLoader()
documents = loader.load_documents([Path("example.pdf")])
# 지원 형식 확인
print(SUPPORTED_FILE_EXTENSIONS)
"""
# 주요 로더 클래스 import
from .custom_loaders import CustomDocumentLoader
# 패키지 레벨 상수
SUPPORTED_FILE_EXTENSIONS = {
'.pdf': 'PDF documents',
'.csv': 'Comma-separated values',
'.md': 'Markdown files',
'.docx': 'Microsoft Word documents',
'.json': 'JSON structured data'
}
# 로더별 설정
LOADER_CONFIGS = {
'pdf': {
'extract_images': False,
'extract_tables': True,
'parsing_strategy': 'auto'
},
'csv': {
'preferred_columns': ['Name', 'Purchase'],
'encoding': 'utf-8',
'delimiter': ','
},
'markdown': {
'extensions': ['tables', 'fenced_code'],
'convert_to_html': True
},
'docx': {
'extract_images': False,
'preserve_formatting': False,
'include_headers_footers': False
},
'json': {
'pretty_print': True,
'max_depth': None,
'flatten_arrays': False
}
}
# 패키지 메타데이터
__version__ = "1.0.0"
__author__ = "RAG Chatbot Team"
__description__ = "Document loaders for various file formats"
# 공개 API
__all__ = [
"CustomDocumentLoader",
"SUPPORTED_FILE_EXTENSIONS",
"LOADER_CONFIGS",
"get_loader_for_extension",
"validate_file_support"
]
# 유틸리티 함수
def get_loader_for_extension(file_extension: str) -> str:
"""파일 확장자에 해당하는 로더 타입 반환
Args:
file_extension: 파일 확장자 (예: '.pdf')
Returns:
str: 로더 타입 또는 None
"""
extension_to_loader = {
'.pdf': 'pdf',
'.csv': 'csv',
'.md': 'markdown',
'.docx': 'docx',
'.json': 'json'
}
return extension_to_loader.get(file_extension.lower())
def validate_file_support(file_path) -> bool:
"""파일이 지원되는 형식인지 확인
Args:
file_path: 파일 경로 (str 또는 Path 객체)
Returns:
bool: 지원 여부
"""
from pathlib import Path
path = Path(file_path)
return path.suffix.lower() in SUPPORTED_FILE_EXTENSIONS
def get_file_type_description(file_extension: str) -> str:
"""파일 확장자에 대한 설명 반환
Args:
file_extension: 파일 확장자
Returns:
str: 파일 타입 설명
"""
return SUPPORTED_FILE_EXTENSIONS.get(file_extension.lower(), "Unknown file type")
# 패키지 초기화 로그
import logging
logger = logging.getLogger(__name__)
logger.info(f"Loaders package initialized - Supporting {len(SUPPORTED_FILE_EXTENSIONS)} file types")/loaders/custom_loaders.py
python"""
커스텀 문서 로더
다양한 파일 형식을 지원하는 최적화된 로더
"""
import json
import pandas as pd
import markdown
from pathlib import Path
from typing import List
import logging
import docx
from llama_index.core import Document, SimpleDirectoryReader
logger = logging.getLogger(__name__)
class CustomDocumentLoader:
"""다양한 문서 형식을 지원하는 커스텀 로더"""
def __init__(self):
self.supported_extensions = {'.pdf', '.csv', '.md', '.docx', '.json'}
def load_documents(self, file_paths: List[Path]) -> List[Document]:
"""
다중 파일 로드
Args:
file_paths: 로드할 파일 경로 리스트
Returns:
Document 객체 리스트
"""
documents = []
for file_path in file_paths:
try:
if file_path.suffix not in self.supported_extensions:
logger.warning(f"지원하지 않는 파일 형식: {file_path}")
continue
# 파일별 로드 메소드 호출
if file_path.suffix == '.pdf':
docs = self._load_pdf(file_path)
elif file_path.suffix == '.csv':
docs = self._load_csv(file_path)
elif file_path.suffix == '.md':
docs = self._load_markdown(file_path)
elif file_path.suffix == '.docx':
docs = self._load_docx(file_path)
elif file_path.suffix == '.json':
docs = self._load_json(file_path)
else:
continue
documents.extend(docs)
logger.debug(f"로드 완료: {file_path} ({len(docs)}개 청크)")
except Exception as e:
logger.error(f"파일 로드 실패 {file_path}: {e}")
continue
logger.info(f"총 {len(documents)}개 문서 청크 로드 완료")
return documents
def _load_pdf(self, file_path: Path) -> List[Document]:
"""PDF 파일 로드"""
try:
reader = SimpleDirectoryReader(input_files=[str(file_path)])
documents = reader.load_data()
# 메타데이터 추가
for doc in documents:
doc.metadata.update({
'source': file_path.name,
'file_type': 'pdf',
'file_path': str(file_path)
})
return documents
except Exception as e:
logger.error(f"PDF 로드 실패 {file_path}: {e}")
return []
def _load_csv(self, file_path: Path) -> List[Document]:
"""CSV 파일 로드 (특정 컬럼 선택 가능)"""
try:
df = pd.read_csv(file_path)
# CSV가 비어있는지 확인
if df.empty:
logger.warning(f"빈 CSV 파일: {file_path}")
return []
# 선택할 컬럼 결정 (Name, Purchase 우선, 없으면 모든 컬럼)
preferred_columns = ["Name", "Purchase"]
selected_columns = [col for col in preferred_columns if col in df.columns]
if not selected_columns:
selected_columns = df.columns.tolist()
logger.info(f"기본 컬럼 사용: {selected_columns}")
# 데이터를 텍스트로 변환
csv_text = df[selected_columns].to_string(index=False)
document = Document(
text=csv_text,
metadata={
'source': file_path.name,
'file_type': 'csv',
'file_path': str(file_path),
'columns': selected_columns,
'row_count': len(df)
}
)
return [document]
except Exception as e:
logger.error(f"CSV 로드 실패 {file_path}: {e}")
return []
def _load_markdown(self, file_path: Path) -> List[Document]:
"""Markdown 파일 로드"""
try:
with open(file_path, 'r', encoding='utf-8') as f:
md_content = f.read()
# Markdown을 HTML로 변환
html_content = markdown.markdown(md_content)
document = Document(
text=html_content,
metadata={
'source': file_path.name,
'file_type': 'markdown',
'file_path': str(file_path),
'original_format': 'markdown'
}
)
return [document]
except Exception as e:
logger.error(f"Markdown 로드 실패 {file_path}: {e}")
return []
def _load_docx(self, file_path: Path) -> List[Document]:
"""DOCX 파일 로드"""
try:
doc = docx.Document(file_path)
# 모든 문단 텍스트 추출
paragraphs = [para.text for para in doc.paragraphs if para.text.strip()]
docx_text = "n".join(paragraphs)
if not docx_text.strip():
logger.warning(f"빈 DOCX 파일: {file_path}")
return []
document = Document(
text=docx_text,
metadata={
'source': file_path.name,
'file_type': 'docx',
'file_path': str(file_path),
'paragraph_count': len(paragraphs)
}
)
return [document]
except Exception as e:
logger.error(f"DOCX 로드 실패 {file_path}: {e}")
return []
def _load_json(self, file_path: Path) -> List[Document]:
"""JSON 파일 로드"""
try:
with open(file_path, 'r', encoding='utf-8') as f:
json_data = json.load(f)
# JSON을 보기 좋은 텍스트로 변환
json_text = json.dumps(json_data, ensure_ascii=False, indent=2)
document = Document(
text=json_text,
metadata={
'source': file_path.name,
'file_type': 'json',
'file_path': str(file_path),
'json_size': len(json_text)
}
)
return [document]
except Exception as e:
logger.error(f"JSON 로드 실패 {file_path}: {e}")
return []/utils/__init__.py
"""
유틸리티 패키지
RAG 시스템의 보조 기능들을 제공합니다:
- 파일 처리 유틸리티
- 성능 모니터링
- 로깅 설정
- 공통 헬퍼 함수
Example:
from utils import performance_monitor, file_utils
# 성능 모니터링
with performance_monitor.measure_time("작업명"):
# 시간을 측정할 작업
pass
# 파일 유틸리티
files = file_utils.find_files_by_extension("/path", [".pdf", ".docx"])
"""
# 주요 모듈들 import
from .performance_monitor import PerformanceMonitor, performance_monitor
from . import file_utils
# 패키지 레벨 상수
SUPPORTED_LOG_LEVELS = ["DEBUG", "INFO", "WARNING", "ERROR", "CRITICAL"]
DEFAULT_PERFORMANCE_CONFIG = {
"enable_monitoring": True,
"log_performance": True,
"track_memory": True,
"track_cpu": True
}
# 패키지 메타데이터
__version__ = "1.0.0"
__author__ = "RAG Chatbot Team"
__description__ = "Utility functions and performance monitoring"
# 공개 API
__all__ = [
"PerformanceMonitor",
"performance_monitor",
"file_utils",
"setup_logging",
"get_system_info",
"format_bytes",
"format_duration"
]
# 로깅 설정 함수
def setup_logging(log_level: str = "INFO", log_format: str = None):
"""애플리케이션 로깅 설정
Args:
log_level: 로그 레벨 (DEBUG, INFO, WARNING, ERROR, CRITICAL)
log_format: 커스텀 로그 포맷
"""
import logging
if log_format is None:
log_format = "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
logging.basicConfig(
level=getattr(logging, log_level.upper()),
format=log_format,
datefmt="%Y-%m-%d %H:%M:%S"
)
# 외부 라이브러리 로그 레벨 조정
logging.getLogger("transformers").setLevel(logging.WARNING)
logging.getLogger("sentence_transformers").setLevel(logging.WARNING)
logging.getLogger("llama_index").setLevel(logging.INFO)
# 시스템 정보 조회 함수
def get_system_info():
"""현재 시스템 정보 반환"""
import psutil
import platform
return {
"platform": platform.platform(),
"python_version": platform.python_version(),
"cpu_count": psutil.cpu_count(),
"memory_total_gb": round(psutil.virtual_memory().total / (1024**3), 2),
"disk_total_gb": round(psutil.disk_usage("/").total / (1024**3), 2)
}
# 유틸리티 함수들
def format_bytes(bytes_value: int) -> str:
"""바이트를 읽기 쉬운 형식으로 변환
Args:
bytes_value: 바이트 값
Returns:
str: 포맷된 문자열 (예: "1.5 GB")
"""
for unit in ['B', 'KB', 'MB', 'GB', 'TB']:
if bytes_value < 1024.0:
return f"{bytes_value:.1f} {unit}"
bytes_value /= 1024.0
return f"{bytes_value:.1f} PB"
def format_duration(seconds: float) -> str:
"""초를 읽기 쉬운 형식으로 변환
Args:
seconds: 시간(초)
Returns:
str: 포맷된 문자열 (예: "2분 30초")
"""
if seconds < 60:
return f"{seconds:.1f}초"
elif seconds < 3600:
minutes = int(seconds // 60)
remaining_seconds = seconds % 60
return f"{minutes}분 {remaining_seconds:.1f}초"
else:
hours = int(seconds // 3600)
remaining_minutes = int((seconds % 3600) // 60)
return f"{hours}시간 {remaining_minutes}분"
def ensure_directory(directory_path):
"""디렉토리가 존재하지 않으면 생성
Args:
directory_path: 생성할 디렉토리 경로
"""
import os
from pathlib import Path
path = Path(directory_path)
if not path.exists():
path.mkdir(parents=True, exist_ok=True)
print(f"Directory created: {path}")
# 패키지 초기화
import logging
logger = logging.getLogger(__name__)
# 기본 로깅 설정 적용
setup_logging()
logger.info("Utils package initialized")
# 패키지 레벨 인스턴스 생성 (Singleton 패턴)
# 애플리케이션 전체에서 하나의 성능 모니터 인스턴스 사용
_global_performance_monitor = None
def get_performance_monitor():
"""글로벌 성능 모니터 인스턴스 반환"""
global _global_performance_monitor
if _global_performance_monitor is None:
_global_performance_monitor = PerformanceMonitor()
return _global_performance_monitor
# 편의를 위해 글로벌 인스턴스를 performance_monitor로 alias
performance_monitor = get_performance_monitor()/utils/file_utils.py
"""
파일 처리 유틸리티
파일 시스템 작업을 위한 헬퍼 함수들을 제공합니다.
"""
import os
import shutil
from pathlib import Path
from typing import List, Set, Optional, Tuple
import logging
logger = logging.getLogger(__name__)
def find_files_by_extension(directory: Path, extensions: Set[str]) -> List[Path]:
"""지정된 확장자의 파일들을 재귀적으로 찾기
Args:
directory: 검색할 디렉토리
extensions: 찾을 파일 확장자 집합 (예: {'.pdf', '.docx'})
Returns:
List[Path]: 찾은 파일들의 경로 리스트
"""
directory = Path(directory)
found_files = []
if not directory.exists():
logger.warning(f"Directory does not exist: {directory}")
return found_files
# 확장자를 소문자로 정규화
extensions = {ext.lower() for ext in extensions}
for file_path in directory.rglob("*"):
if file_path.is_file() and file_path.suffix.lower() in extensions:
found_files.append(file_path)
logger.info(f"Found {len(found_files)} files with extensions {extensions} in {directory}")
return found_files
def get_file_size(file_path: Path) -> int:
"""파일 크기 반환 (바이트)
Args:
file_path: 파일 경로
Returns:
int: 파일 크기 (바이트)
"""
try:
return file_path.stat().st_size
except (OSError, FileNotFoundError):
logger.error(f"Cannot get size of file: {file_path}")
return 0
def get_directory_size(directory: Path) -> int:
"""디렉토리 전체 크기 계산 (바이트)
Args:
directory: 디렉토리 경로
Returns:
int: 디렉토리 크기 (바이트)
"""
total_size = 0
try:
for file_path in directory.rglob("*"):
if file_path.is_file():
total_size += get_file_size(file_path)
except Exception as e:
logger.error(f"Error calculating directory size: {e}")
return total_size
def safe_file_copy(source: Path, destination: Path, overwrite: bool = False) -> bool:
"""안전한 파일 복사
Args:
source: 원본 파일 경로
destination: 대상 파일 경로
overwrite: 덮어쓰기 허용 여부
Returns:
bool: 복사 성공 여부
"""
try:
source = Path(source)
destination = Path(destination)
if not source.exists():
logger.error(f"Source file does not exist: {source}")
return False
if destination.exists() and not overwrite:
logger.warning(f"Destination already exists and overwrite=False: {destination}")
return False
# 대상 디렉토리 생성
destination.parent.mkdir(parents=True, exist_ok=True)
# 파일 복사
shutil.copy2(source, destination)
logger.info(f"File copied: {source} -> {destination}")
return True
except Exception as e:
logger.error(f"Error copying file: {e}")
return False
def safe_file_move(source: Path, destination: Path, overwrite: bool = False) -> bool:
"""안전한 파일 이동
Args:
source: 원본 파일 경로
destination: 대상 파일 경로
overwrite: 덮어쓰기 허용 여부
Returns:
bool: 이동 성공 여부
"""
try:
source = Path(source)
destination = Path(destination)
if not source.exists():
logger.error(f"Source file does not exist: {source}")
return False
if destination.exists() and not overwrite:
logger.warning(f"Destination already exists and overwrite=False: {destination}")
return False
# 대상 디렉토리 생성
destination.parent.mkdir(parents=True, exist_ok=True)
# 파일 이동
shutil.move(str(source), str(destination))
logger.info(f"File moved: {source} -> {destination}")
return True
except Exception as e:
logger.error(f"Error moving file: {e}")
return False
def safe_directory_delete(directory: Path, force: bool = False) -> bool:
"""안전한 디렉토리 삭제
Args:
directory: 삭제할 디렉토리 경로
force: 강제 삭제 여부 (비어있지 않아도 삭제)
Returns:
bool: 삭제 성공 여부
"""
try:
directory = Path(directory)
if not directory.exists():
logger.warning(f"Directory does not exist: {directory}")
return True
if not directory.is_dir():
logger.error(f"Path is not a directory: {directory}")
return False
# 디렉토리가 비어있지 않은 경우
if any(directory.iterdir()) and not force:
logger.warning(f"Directory is not empty and force=False: {directory}")
return False
# 디렉토리 삭제
shutil.rmtree(directory)
logger.info(f"Directory deleted: {directory}")
return True
except Exception as e:
logger.error(f"Error deleting directory: {e}")
return False
def create_backup(file_path: Path, backup_suffix: str = ".backup") -> Optional[Path]:
"""파일 백업 생성
Args:
file_path: 백업할 파일 경로
backup_suffix: 백업 파일 접미사
Returns:
Optional[Path]: 백업 파일 경로 (실패 시 None)
"""
try:
file_path = Path(file_path)
if not file_path.exists():
logger.error(f"File does not exist: {file_path}")
return None
# 백업 파일 경로 생성
backup_path = file_path.with_suffix(file_path.suffix + backup_suffix)
# 백업 파일이 이미 존재하면 숫자 추가
counter = 1
while backup_path.exists():
backup_path = file_path.with_suffix(f"{file_path.suffix}{backup_suffix}.{counter}")
counter += 1
# 백업 생성
shutil.copy2(file_path, backup_path)
logger.info(f"Backup created: {backup_path}")
return backup_path
except Exception as e:
logger.error(f"Error creating backup: {e}")
return None
def cleanup_old_files(directory: Path, max_age_days: int, pattern: str = "*") -> int:
"""오래된 파일들 정리
Args:
directory: 정리할 디렉토리
max_age_days: 최대 보관 일수
pattern: 파일 패턴 (glob 패턴)
Returns:
int: 삭제된 파일 수
"""
import time
try:
directory = Path(directory)
current_time = time.time()
max_age_seconds = max_age_days * 24 * 3600
deleted_count = 0
for file_path in directory.glob(pattern):
if file_path.is_file():
file_age = current_time - file_path.stat().st_mtime
if file_age > max_age_seconds:
try:
file_path.unlink()
deleted_count += 1
logger.debug(f"Deleted old file: {file_path}")
except Exception as e:
logger.error(f"Error deleting file {file_path}: {e}")
logger.info(f"Cleanup completed: {deleted_count} files deleted from {directory}")
return deleted_count
except Exception as e:
logger.error(f"Error during cleanup: {e}")
return 0
def get_available_disk_space(path: Path) -> Tuple[int, int, int]:
"""디스크 여유 공간 정보 반환
Args:
path: 확인할 경로
Returns:
Tuple[int, int, int]: (총 공간, 사용 공간, 여유 공간) 바이트 단위
"""
try:
stat = shutil.disk_usage(path)
return stat.total, stat.used, stat.free
except Exception as e:
logger.error(f"Error getting disk usage: {e}")
return 0, 0, 0
def is_file_locked(file_path: Path) -> bool:
"""파일이 다른 프로세스에 의해 사용 중인지 확인
Args:
file_path: 확인할 파일 경로
Returns:
bool: 파일이 잠겨있으면 True
"""
try:
with open(file_path, 'r+'):
pass
return False
except IOError:
return True
except Exception:
return True
def normalize_path(path: str) -> Path:
"""경로 정규화 (상대경로를 절대경로로, 경로 구분자 통일)
Args:
path: 정규화할 경로
Returns:
Path: 정규화된 경로 객체
"""
return Path(path).resolve()
def get_file_extension_safely(file_path: Path) -> str:
"""파일 확장자를 안전하게 추출 (소문자로 변환)
Args:
file_path: 파일 경로
Returns:
str: 파일 확장자 (점 포함, 소문자)
"""
return file_path.suffix.lower() if file_path.suffix else ""
def count_files_by_extension(directory: Path) -> dict:
"""디렉토리의 파일을 확장자별로 개수 세기
Args:
directory: 확인할 디렉토리
Returns:
dict: {확장자: 개수} 딕셔너리
"""
directory = Path(directory)
extension_counts = {}
try:
for file_path in directory.rglob("*"):
if file_path.is_file():
ext = get_file_extension_safely(file_path)
extension_counts[ext] = extension_counts.get(ext, 0) + 1
except Exception as e:
logger.error(f"Error counting files: {e}")
return extension_counts/utils/performance_monitor.py
python"""
성능 모니터링 유틸리티
시스템 성능 추적 및 병목 지점 식별
"""
import time
import psutil
import logging
from functools import wraps
from typing import Dict, Any
from contextlib import contextmanager
logger = logging.getLogger(__name__)
class PerformanceMonitor:
"""성능 모니터링 클래스"""
def __init__(self):
self.metrics = {}
self.start_time = time.time()
@contextmanager
def measure_time(self, operation_name: str):
"""시간 측정 컨텍스트 매니저"""
start_time = time.time()
try:
yield
finally:
elapsed_time = time.time() - start_time
self.metrics[operation_name] = elapsed_time
logger.info(f"{operation_name}: {elapsed_time:.2f}초")
def monitor_performance(self, func_name: str = None):
"""함수 성능 모니터링 데코레이터"""
def decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
operation_name = func_name or f"{func.__module__}.{func.__name__}"
# 메모리 사용량 (시작)
process = psutil.Process()
memory_before = process.memory_info().rss / 1024 / 1024 # MB
# 시간 측정
start_time = time.time()
try:
result = func(*args, **kwargs)
return result
finally:
elapsed_time = time.time() - start_time
memory_after = process.memory_info().rss / 1024 / 1024 # MB
memory_diff = memory_after - memory_before
# 메트릭 저장
self.metrics[operation_name] = {
'execution_time': elapsed_time,
'memory_before': memory_before,
'memory_after': memory_after,
'memory_diff': memory_diff
}
logger.info(
f"{operation_name} - 실행시간: {elapsed_time:.2f}초, "
f"메모리 변화: {memory_diff:+.1f}MB"
)
return wrapper
return decorator
def get_system_info(self) -> Dict[str, Any]:
"""시스템 정보 조회"""
return {
'cpu_percent': psutil.cpu_percent(interval=1),
'memory_percent': psutil.virtual_memory().percent,
'disk_usage': psutil.disk_usage('/').percent,
'available_memory_gb': psutil.virtual_memory().available / 1024 / 1024 / 1024
}
def get_performance_summary(self) -> Dict[str, Any]:
"""성능 요약 정보"""
total_time = time.time() - self.start_time
return {
'total_runtime': total_time,
'operations': self.metrics,
'system_info': self.get_system_info()
}
def reset_metrics(self):
"""메트릭 초기화"""
self.metrics.clear()
self.start_time = time.time()
# 글로벌 모니터 인스턴스
performance_monitor = PerformanceMonitor()/app.py (메인 애플리케이션)
python"""
최적화된 RAG 챗봇 메인 애플리케이션
증분 인덱싱과 캐싱으로 성능 최적화
"""
import streamlit as st
import logging
from pathlib import Path
from llama_index.llms.llama_cpp import LlamaCPP
from config.settings import *
from core.index_manager import IndexManager
from utils.performance_monitor import performance_monitor
# 로깅 설정
logging.basicConfig(level=getattr(logging, LOG_LEVEL), format=LOG_FORMAT)
logger = logging.getLogger(__name__)
# Streamlit 페이지 설정
st.set_page_config(
page_title="최적화된 RAG 챗봇",
page_icon="🤖",
layout="wide"
)
st.title("🤖 RAG 챗봇: 최적화된 인덱싱")
st.markdown("PDF, CSV, Markdown, DOCX, JSON 문서를 기반으로 빠르게 답변합니다.")
# 사이드바 - 설정 및 상태
with st.sidebar:
st.header("⚙️ 설정")
# 인덱스 관리 버튼
if st.button("🔄 인덱스 업데이트", help="새로운 또는 수정된 문서만 인덱싱"):
with st.spinner("인덱스 업데이트 중..."):
st.session_state.force_index_update = True
st.success("인덱스 업데이트가 예약되었습니다.")
if st.button("🔥 인덱스 강제 재빌드", help="모든 문서를 다시 인덱싱"):
with st.spinner("인덱스 재빌드 중..."):
st.session_state.force_index_rebuild = True
st.success("인덱스 재빌드가 예약되었습니다.")
if st.button("🗑️ 캐시 초기화", help="인덱스와 임베딩 캐시 삭제"):
st.session_state.clear_cache = True
st.success("캐시 초기화가 예약되었습니다.")
# LLM 로드 (캐시됨)
@st.cache_resource(show_spinner="🧠 LLM 모델 로드 중...")
def load_llm():
"""LLM 모델 로드"""
return LlamaCPP(
model_path=str(LLM_MODEL_PATH),
temperature=LLM_TEMPERATURE,
max_new_tokens=LLM_MAX_NEW_TOKENS,
context_window=LLM_CONTEXT_WINDOW,
verbose=False
)
# 인덱스 매니저 초기화
@st.cache_resource(show_spinner="📚 인덱스 매니저 초기화 중...")
def load_index_manager():
"""인덱스 매니저 로드"""
return IndexManager()
# 세션 상태 초기화
if "messages" not in st.session_state:
st.session_state.messages = []
# 강제 작업 처리
if st.session_state.get("clear_cache", False):
with st.spinner("캐시 초기화 중..."):
index_manager = load_index_manager()
index_manager.clear_cache()
st.cache_resource.clear()
st.session_state.messages = []
st.session_state.clear_cache = False
st.success("캐시가 초기화되었습니다.")
st.rerun()
# 컴포넌트 로드
llm = load_llm()
index_manager = load_index_manager()
# 인덱스 생성/업데이트
force_rebuild = st.session_state.get("force_index_rebuild", False)
if force_rebuild:
st.session_state.force_index_rebuild = False
with performance_monitor.measure_time("인덱스 생성/업데이트"):
try:
index = index_manager.create_or_update_index(force_rebuild=force_rebuild)
if index is None:
st.error("⚠️ 인덱싱할 문서가 없습니다. `docs/` 폴더에 지원되는 파일을 추가해주세요.")
st.stop()
query_engine = index_manager.get_query_engine(llm)
except Exception as e:
st.error(f"❌ 인덱스 초기화 실패: {e}")
logger.error(f"인덱스 초기화 실패: {e}")
st.stop()
# 상태 정보 표시
with st.sidebar:
st.header("📊 시스템 상태")
# 인덱스 통계
index_stats = index_manager.get_index_stats()
if "total_vectors" in index_stats:
st.metric("인덱싱된 벡터", index_stats["total_vectors"])
st.metric("인덱싱된 파일", index_stats["indexed_files"])
# 성능 정보
perf_summary = performance_monitor.get_performance_summary()
system_info = perf_summary["system_info"]
st.metric("CPU 사용률", f"{system_info['cpu_percent']:.1f}%")
st.metric("메모리 사용률", f"{system_info['memory_percent']:.1f}%")
st.metric("사용 가능 메모리", f"{system_info['available_memory_gb']:.1f}GB")
# 메인 채팅 인터페이스
st.header("💬 채팅")
# 채팅 기록 표시
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.write(message["content"])
if message["role"] == "assistant" and "sources" in message:
with st.expander("📄 출처 문서"):
st.write(", ".join(message["sources"]))
# 새 메시지 입력
if prompt := st.chat_input("질문을 입력해주세요..."):
# 사용자 메시지 표시
with st.chat_message("user"):
st.write(prompt)
st.session_state.messages.append({"role": "user", "content": prompt})
# 챗봇 응답 생성
with st.chat_message("assistant"):
with st.spinner("답변 생성 중..."):
try:
# 성능 모니터링과 함께 쿼리 실행
with performance_monitor.measure_time("질의 응답"):
response = query_engine.query(prompt)
# 답변 표시
st.write(response.response)
# 출처 정보 추출
sources = []
if hasattr(response, 'source_nodes'):
sources = [node.node.metadata.get("source", "Unknown") for node in response.source_nodes]
# 출처 표시
if sources:
with st.expander("📄 출처 문서"):
st.write(", ".join(set(sources))) # 중복 제거
# 세션에 저장
st.session_state.messages.append({
"role": "assistant",
"content": response.response,
"sources": sources
})
except Exception as e:
error_message = f"죄송합니다. 답변 생성 중 오류가 발생했습니다: {str(e)}"
st.error(error_message)
logger.error(f"쿼리 처리 오류: {e}")
st.session_state.messages.append({
"role": "assistant",
"content": error_message,
"sources": []
})
# 하단 정보
st.markdown("---")
with st.expander("ℹ️ 사용법 및 정보"):
st.markdown("""
### 📝 지원 파일 형식
- PDF: 자동 텍스트 추출
- CSV: Name, Purchase 컬럼 우선 처리
- Markdown: HTML 변환 후 처리
- DOCX: 문단 텍스트 추출
- JSON: 구조화된 데이터 처리
### 🚀 최적화 기능
- 증분 인덱싱: 새로운/수정된 파일만 처리
- 임베딩 캐시: 중복 계산 방지
- FAISS IVF: 빠른 유사도 검색
- 성능 모니터링: 실시간 시스템 상태 추적
### 💡 사용 팁
- `docs/` 폴더에 문서 추가 후 "인덱스 업데이트" 클릭
- 대량 문서 추가 시 "강제 재빌드" 권장
- 정기적인 캐시 초기화로 최적 성능 유지
""")/requirements.txt
textstreamlit>=1.28.0
llama-index>=0.9.0
llama-index-llms-llama-cpp>=0.1.0
llama-index-embeddings-huggingface>=0.1.0
llama-index-vector-stores-faiss>=0.1.0
faiss-cpu>=1.7.4
transformers>=4.35.0
sentence-transformers>=2.2.2
pandas>=1.5.0
python-docx>=0.8.11
markdown>=3.5.0
psutil>=5.9.0🎯 주요 최적화 포인트
1. 문서 변경 감지 시스템
해시 기반 변경 감지로 불필요한 재처리 방지
파일별 메타데이터 추적 (수정 시간, 크기, 인덱싱 상태)
2. 증분 인덱싱
새로운/수정된 파일만 처리
기존 인덱스에 새 문서 추가 (전체 재빌드 불필요)
3. 고급 캐싱 전략
임베딩 결과 캐시로 중복 계산 방지
LRU 방식 캐시 관리
Streamlit 네이티브 캐싱 활용
4. 성능 모니터링
실시간 시스템 리소스 추적
각 작업별 실행 시간 측정
메모리 사용량 모니터링
문제 해결: 흔한 에러와 해결책
가끔씩 걸림돌이 생길 수 있죠. 아래 팁으로 쉽게 해결하세요:
"No module named 'llama_index'":
pip install llama-index를 다시 실행."Model file not found": 모델 경로(
models/llama-2-7b-chat.gguf)를 확인.메모리 부족:
chunk_size를 줄이거나, 가벼운 LLM으로 교체.느린 쿼리:
similarity_top_k를 조정하거나 FAISS 설정을 최적화.
마치며: 여러분의 비즈니스를 혁신할 준비가 되셨나요?
이제 여러분은 LlamaIndex와 Streamlit으로 강력한 RAG 챗봇을 구축할 준비가 되었습니다! 단순한 답변을 넘어, 실제 문서에서 정보를 추출해 신뢰할 수 있는 결과를 제공하는 이 챗봇은 비즈니스에 날개를 달아줄 거예요. 온프레미스 환경에서의 데이터 보안은 덤이고요!
지금 바로 시작해 보세요! 질문이 있거나 도움이 필요하면 언제든 댓글로 남겨주세요. 여러분의 성공을 응원합니다!
참고자료
키워드만 입력하면 나만의 학습 노트가 완성돼요.
책이나 강의 없이, AI로 위키 노트를 바로 만들어서 읽으세요.
콘텐츠를 만들 때도 사용해 보세요. AI가 리서치, 정리, 이미지까지 초안을 바로 만들어 드려요.