
언어의 미로를 탐험하며: 진실과 허위의 경계를 읽어내는 데이터 과학

언어의 미로를 탐험하며: 진실과 허위의 경계를 읽어내는 데이터 과학
언어는 인간 영혼의 거울이자 세상을 바라보는 창문이다. 그 미묘한 결이 때로는 진실을, 때로는 거짓을 드러낸다.

서문: 진실과 허구 사이의 미묘한 춤
우리가 살아가는 디지털 풍경은 끊임없이 변화하는 정보의 바다와 같습니다. 매 순간 수많은 이야기들이 파도처럼 밀려오고, 우리는 그 파도 속에서 진실의 조각들을 찾아 헤매게 됩니다. 가짜 뉴스와 진짜 뉴스를 구분하는 일은 단순한 사실 확인을 넘어, 언어와 표현 방식의 미묘한 차이를 읽어내는 깊은 이해의 과정입니다.
이 글에서는 데이터 과학의 렌즈를 통해 언어가 어떻게 진실과 허구를 드러내는지 탐색해보려 합니다. 마치 숲속의 흔적을 따라가는 탐험가처럼, 언어의 흔적을 따라 진실의 길을 찾아가는 여정을 함께 떠나보겠습니다.
여정의 시작: 데이터 과학적 접근
우리의 탐구는 Kaggle에 공개된 "Real & Fake News" 데이터셋을 바탕으로 합니다. 이 데이터셋은 진실된 뉴스와 거짓된 뉴스가 함께 담겨 있어, 두 유형 간의 언어적 차이를 분석할 수 있는 훌륭한 토대를 제공합니다.
데이터 과학의 철학은 단순한 기술의 적용이 아닌, 체계적인 질문과 탐구의 과정입니다. 마치 고대 철학자들이 자연의 질서를 이해하기 위해 관찰과 사유를 반복했듯이, 데이터 과학자는 데이터의 바다에서 패턴과 의미를 찾아내기 위해 방법론적 여정을 시작합니다.
데이터 탐색: 처음 만나는 진실과 허구의 풍경
모든 탐구의 여정은 대상을 관찰하는 것으로 시작됩니다. 우리의 여정도 데이터를 불러오고 그 구조를 이해하는 첫 걸음부터 시작합니다.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import nltk
from nltk.tokenize import word_tokenize, sent_tokenize
from nltk.corpus import stopwords
# 필요한 NLTK 데이터 다운로드
nltk.download('punkt')
nltk.download('stopwords')
# 데이터 불러오기
df_true = pd.read_csv('True.csv')
df_fake = pd.read_csv('Fake.csv')
# 라벨 추가
df_true['label'] = 'authentic'
df_fake['label'] = 'deceptive'
# 데이터셋 합치기
df = pd.concat([df_true, df_fake], ignore_index=True)
# 데이터 구조 살펴보기
print("데이터셋의 처음 5행:")
display(df.head())
# 열 정보와 데이터 타입 확인
print("\n열 이름과 데이터 타입:")
display(df.info())
# 각 열의 고유값 수 확인
print("\n각 열의 고유값 수:")
display(df.nunique())이 첫 단계는 마치 미지의 땅에 첫발을 내딛는 탐험가와 같습니다. 데이터의 구조, 누락된 값, 각 특성의 분포를 관찰하며 우리는 이 데이터가 들려주려는 이야기의 윤곽을 그려봅니다.
데이터 전처리: 언어의 정원을 가꾸는 과정
언어 데이터는 가공되지 않은 원석과 같습니다. 그 속에 담긴 패턴과 의미를 발견하기 위해서는 세심한 가공이 필요합니다. 데이터 전처리 과정은 마치 정원사가 무성한 정원을 정리하듯, 언어의 혼란스러운 숲에서 명확한 길을 만들어내는 작업입니다.
import re
import string
# 누락된 텍스트 값이 있는 행 제거
df.dropna(subset=['text'], inplace=True)
def clean_text(text):
"""
입력된 텍스트에서 URL, 특수 문자를 제거하고,
소문자로 변환한 후 여분의 공백을 제거합니다.
"""
# 입력이 문자열인지 확인
if not isinstance(text, str):
text = str(text)
# URL 제거
text = re.sub(r'httpS+|wwwS+|httpsS+', '', text, flags=re.MULTILINE)
# 특수 문자와 기호 제거, 알파벳, 숫자, 공백만 유지
text = re.sub(r'[^a-zA-Z0-9s]', '', text)
# 소문자로 변환
text = text.lower()
# 여분의 공백 제거
text = re.sub(r's+', ' ', text).strip()
return text
# 'text' 열에 clean_text 함수 적용
df['cleaned_text'] = df['text'].apply(clean_text)
# 정제된 텍스트 토큰화
df['tokenized_text'] = df['cleaned_text'].apply(word_tokenize)
# 불용어 제거
stop_words = set(stopwords.words('english'))
df['text_without_stopwords'] = df['tokenized_text'].apply(lambda tokens: [word for word in tokens if word not in stop_words])
# 새로 생성된 열을 포함한 데이터프레임의 처음 5행 표시
print("정제 및 토큰화된 텍스트가 포함된 데이터프레임의 처음 5행:")
display(df.head())이 과정을 통해 우리는 URL, 특수 문자, 불용어(the, a, is 등 자주 등장하지만 의미 분석에는 크게 기여하지 않는 단어들)를 제거하고, 모든 텍스트를 소문자로 변환합니다. 이는 마치 풍경화를 그리기 전에 캔버스를 준비하는 과정과 같습니다. 잘 준비된 캔버스 위에서만 진정한 예술이 탄생할 수 있듯이, 잘 정제된 데이터에서만 의미 있는 분석이 가능합니다.
언어의 풍경 탐색: 시각화를 통한 이해
데이터 시각화는 추상적인 숫자의 바다에서 의미있는 패턴을 발견하는 강력한 도구입니다. 마치 높은 봉우리에서 아래 펼쳐진 풍경을 조망하듯, 시각화를 통해 우리는 데이터의 전체적인 흐름과 구조를 한눈에 파악할 수 있습니다.
라벨 분포: 진실과 허구의 균형
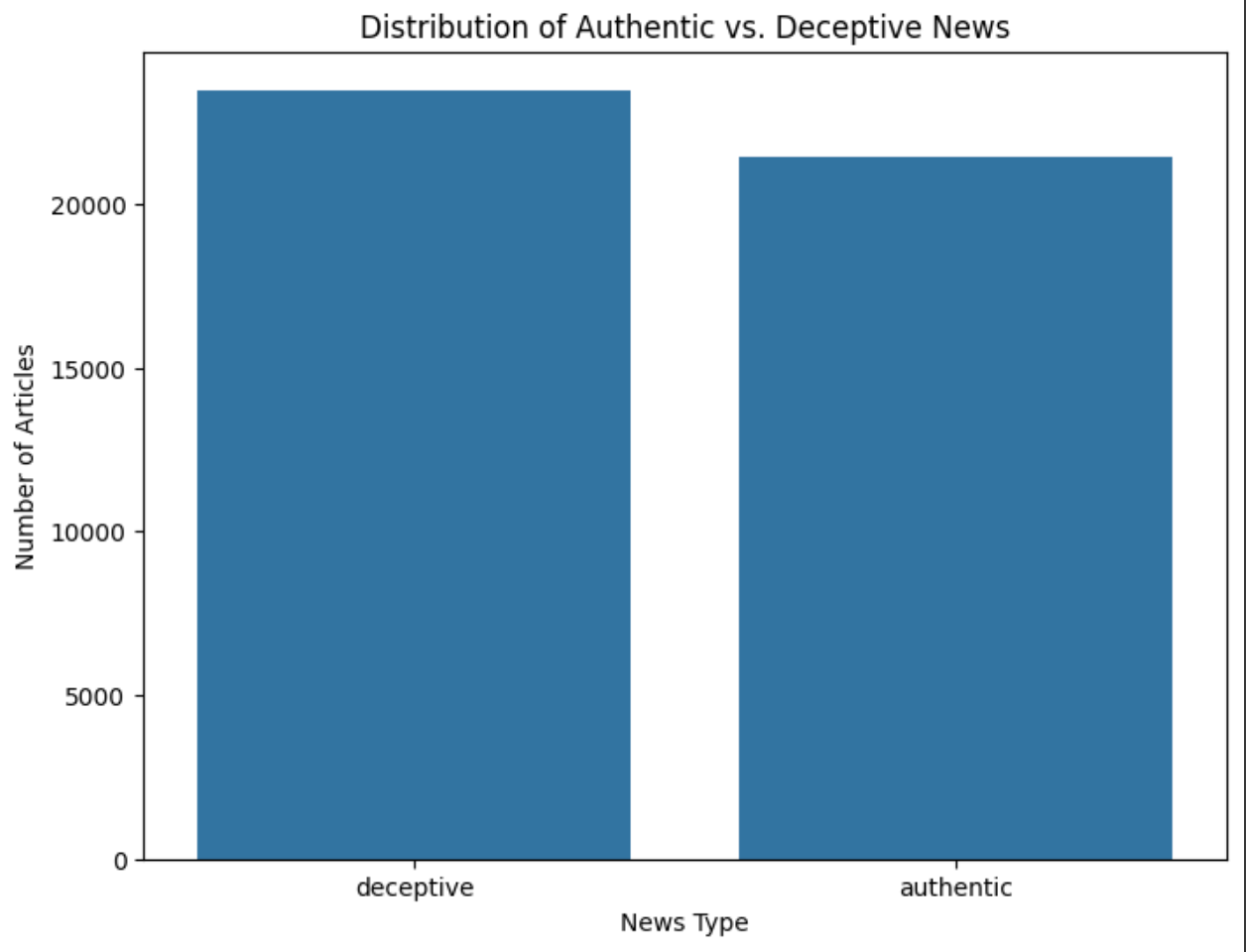
먼저, 데이터셋에서 진짜 뉴스('authentic')와 가짜 뉴스('deceptive')의 분포를 시각화해 보겠습니다.
# 각 라벨의 개수 계산
label_counts = df['label'].value_counts()
# 라벨 분포의 막대 그래프 생성
plt.figure(figsize=(8, 6))
sns.barplot(x=label_counts.index, y=label_counts.values)
plt.title('진실 vs 허위 뉴스의 분포')
plt.xlabel('뉴스 유형')
plt.ylabel('기사 수')
plt.show()이 시각화를 통해 우리는 데이터셋이 진짜 뉴스와 가짜 뉴스를 얼마나 균형 있게 포함하고 있는지 확인할 수 있습니다. 균형 잡힌 데이터셋은 패턴을 비교하고 차이점을 발견하는 데 있어 중요한 토대가 됩니다.
주제 분포: 진실과 허구가 선호하는 영역
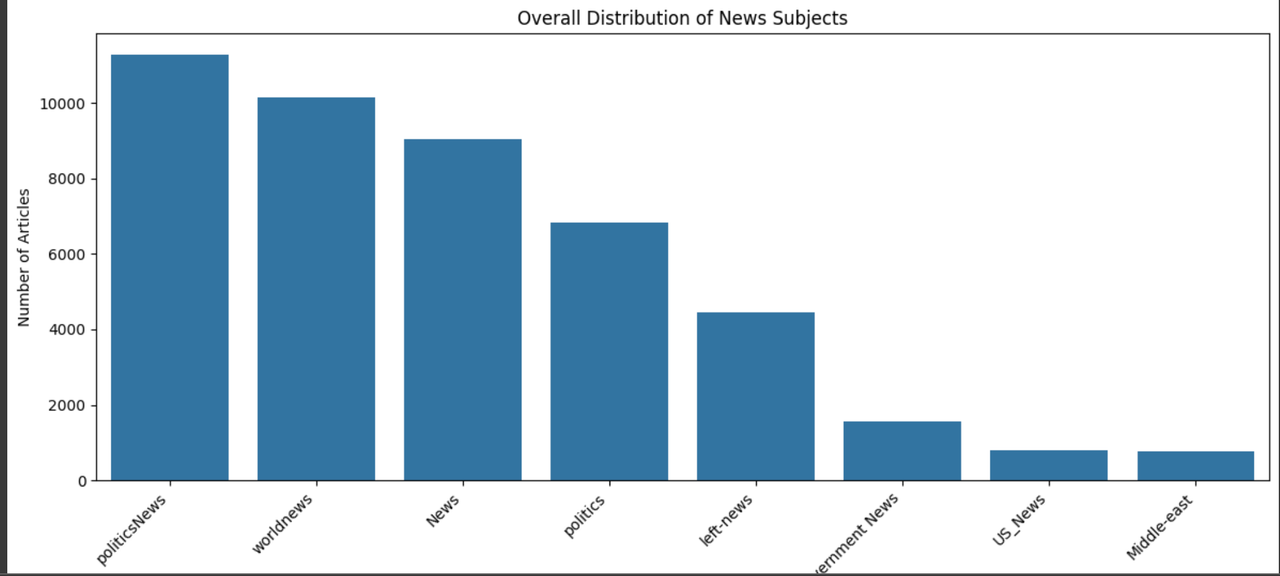
진짜 뉴스와 가짜 뉴스가 다루는 주제에도 차이가 있을까요? 이를 알아보기 위해 주제별 분포를 시각화해봅시다.
# 전체 데이터셋의 주제별 개수 계산
subject_counts = df['subject'].value_counts()
# 전체 주제 분포의 막대 그래프 생성
plt.figure(figsize=(12, 6))
sns.barplot(x=subject_counts.index, y=subject_counts.values)
plt.title('전체 뉴스 주제 분포')
plt.xlabel('주제')
plt.ylabel('기사 수')
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.show()
# 진짜 뉴스와 가짜 뉴스 각각의 주제별 개수 계산
authentic_subject_counts = df[df['label'] == 'authentic']['subject'].value_counts()
deceptive_subject_counts = df[df['label'] == 'deceptive']['subject'].value_counts()
# 진짜 뉴스와 가짜 뉴스의 주제 분포 막대 그래프 생성
fig, axes = plt.subplots(1, 2, figsize=(18, 6))
sns.barplot(x=authentic_subject_counts.index, y=authentic_subject_counts.values, ax=axes[0])
axes[0].set_title('진짜 뉴스의 주제 분포')
axes[0].set_xlabel('주제')
axes[0].set_ylabel('기사 수')
axes[0].tick_params(axis='x', rotation=45, ha='right')
sns.barplot(x=deceptive_subject_counts.index, y=deceptive_subject_counts.values, ax=axes[1])
axes[1].set_title('가짜 뉴스의 주제 분포')
axes[1].set_xlabel('주제')
axes[1].set_ylabel('기사 수')
axes[1].tick_params(axis='x', rotation=45, ha='right')
plt.tight_layout()
plt.show()이 시각화를 통해 진짜 뉴스는 주로 'politicsNews'와 'worldnews' 카테고리에 집중되어 있는 반면, 가짜 뉴스는 'News', 'politics', 'left-news' 등 더 다양한 주제를 다루고 있음을 발견할 수 있습니다. 이는 마치 현실의 뉴스가 정돈된 틀 안에서 움직이는 반면, 허구의 뉴스는 더 넓은 범위에서 자유롭게 변형되는 모습을 보여주는 듯합니다.
언어의 깊은 숲으로: 언어적 특징 추출
언어는 단순한 단어의 나열이 아닌, 복잡한 구조와 패턴을 가진 살아있는 유기체와 같습니다. 우리는 이제 텍스트의 표면을 넘어, 더 깊은 언어적 특징들을 추출하여 진짜 뉴스와 가짜 뉴스 사이의 미묘한 차이를 발견해보겠습니다.
def calculate_average_word_length(text):
"""텍스트의 평균 단어 길이를 계산합니다."""
if not text:
return 0
words = text.split()
if not words:
return 0
return sum(len(word) for word in words) / len(words)
def count_sentences(text):
"""텍스트의 문장 수를 계산합니다."""
if not text:
return 0
sentences = sent_tokenize(text)
return len(sentences)
def calculate_average_words_per_sentence(text):
"""텍스트의 문장당 평균 단어 수를 계산합니다."""
if not text:
return 0
sentences = sent_tokenize(text)
if not sentences:
return 0
word_count = len(text.split())
return word_count / len(sentences)
def calculate_stopwords_proportion(tokenized_text, text_without_stopwords):
"""텍스트에서 불용어의 비율을 계산합니다."""
if not tokenized_text:
return 0
return (len(tokenized_text) - len(text_without_stopwords)) / len(tokenized_text)
def calculate_punctuation_proportion(text):
"""텍스트에서 구두점의 비율을 계산합니다."""
if not isinstance(text, str):
text = str(text)
if not text:
return 0
punctuation_count = sum(text.count(p) for p in string.punctuation)
return punctuation_count / len(text)
# 평균 단어 길이 계산
df['avg_word_length'] = df['cleaned_text'].apply(calculate_average_word_length)
# 문장 수 계산
df['sentence_count'] = df['cleaned_text'].apply(count_sentences)
# 문장당 평균 단어 수 계산
df['avg_words_per_sentence'] = df['cleaned_text'].apply(calculate_average_words_per_sentence)
# 불용어 비율 계산
df['stopwords_proportion'] = df.apply(lambda row: calculate_stopwords_proportion(row['tokenized_text'], row['text_without_stopwords']), axis=1)
# 구두점 비율 계산
df['punctuation_proportion'] = df['text'].apply(calculate_punctuation_proportion)
# 새로운 언어적 특징 열이 포함된 데이터프레임의 처음 5행 표시
print("새로운 언어적 특징이 포함된 데이터프레임의 처음 5행:")
display(df.head())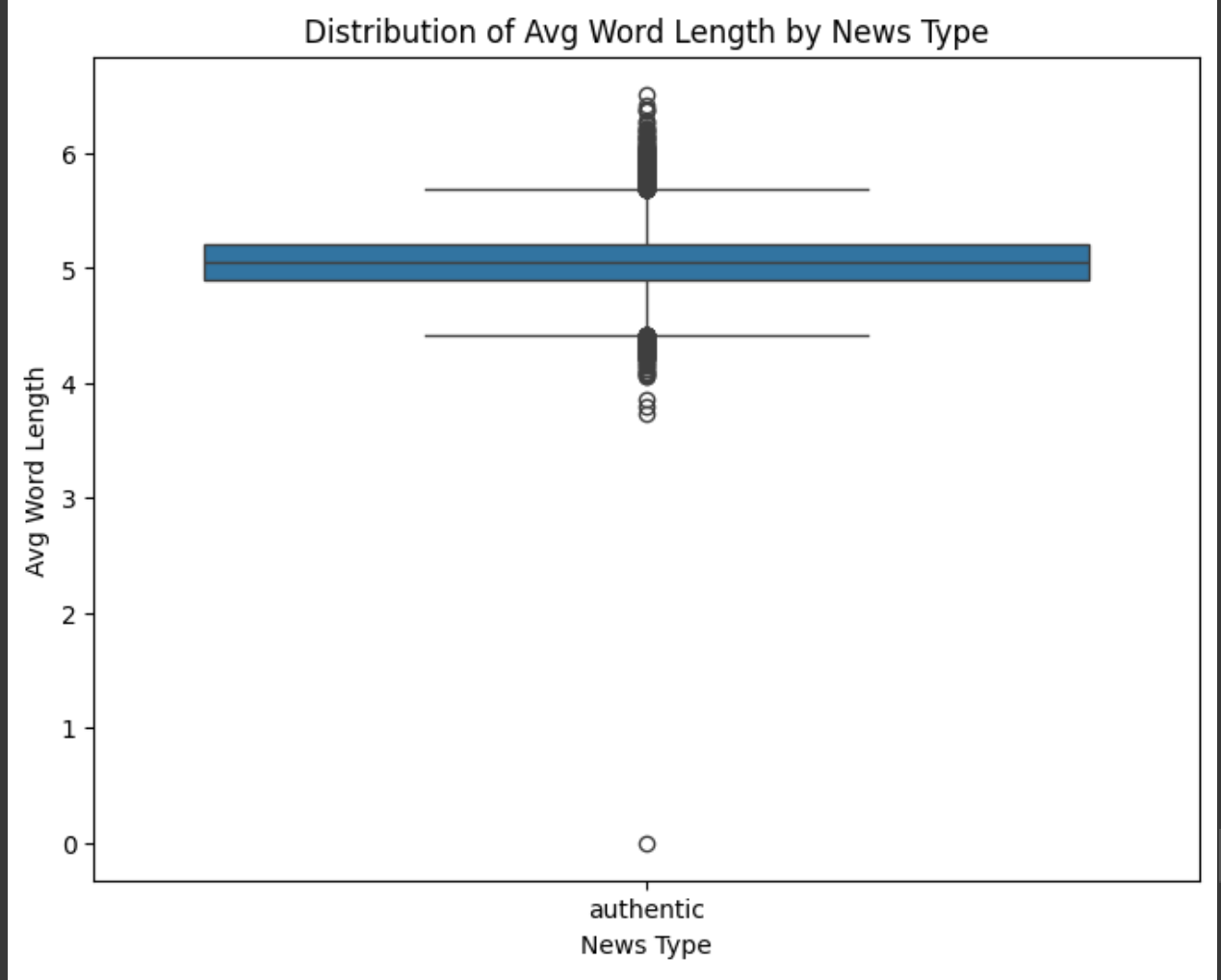
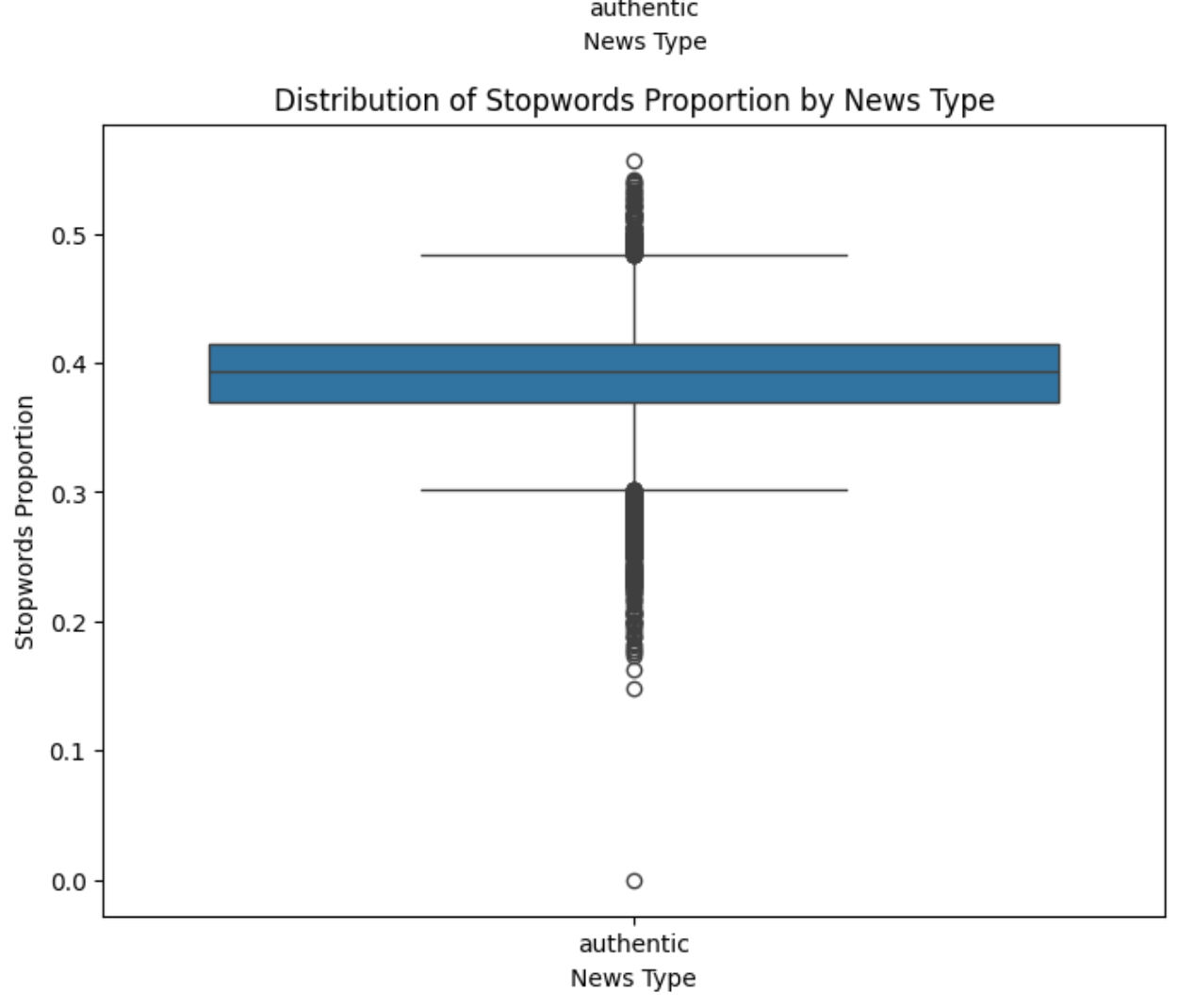
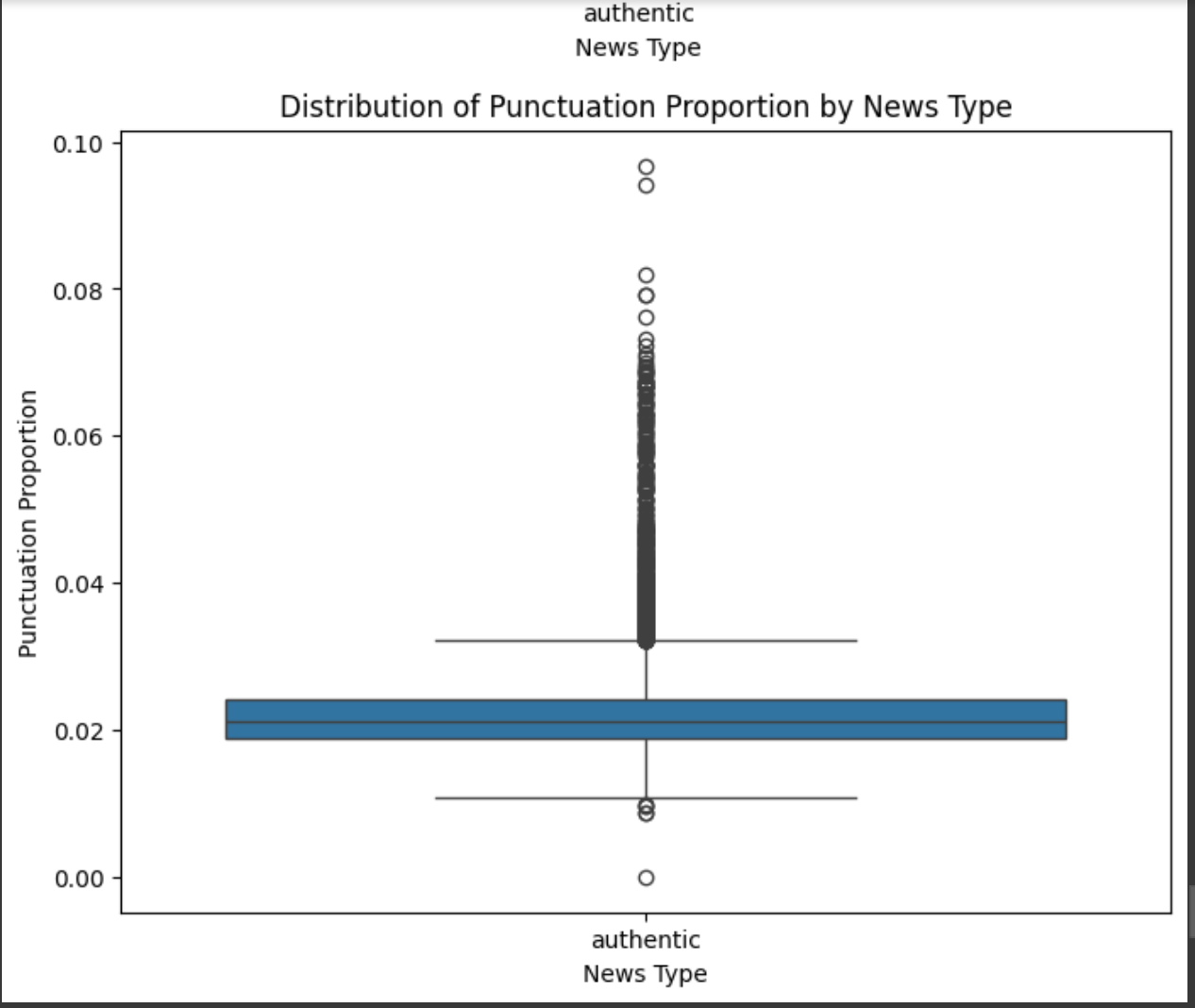
이 과정을 통해 우리는 다음과 같은 언어적 특징을 추출했습니다:
평균 단어 길이: 가짜 뉴스와 진짜 뉴스에서 사용되는 단어의 평균 길이
문장 수: 각 기사에 포함된 문장의 수
문장당 평균 단어 수: 문장 구조의 복잡성을 나타내는 지표
불용어 비율: 전체 텍스트에서 불용어가 차지하는 비율
구두점 비율: 전체 텍스트에서 구두점이 차지하는 비율
이러한 특징들은 마치 숲속의 다양한 식물들처럼, 언어의 생태계를 구성하는 요소들입니다. 그리고 이 요소들의 분포와 패턴을 통해 우리는 진실과 허구의 미묘한 차이를 발견할 수 있습니다.
패턴의 춤: 언어적 특징의 시각화
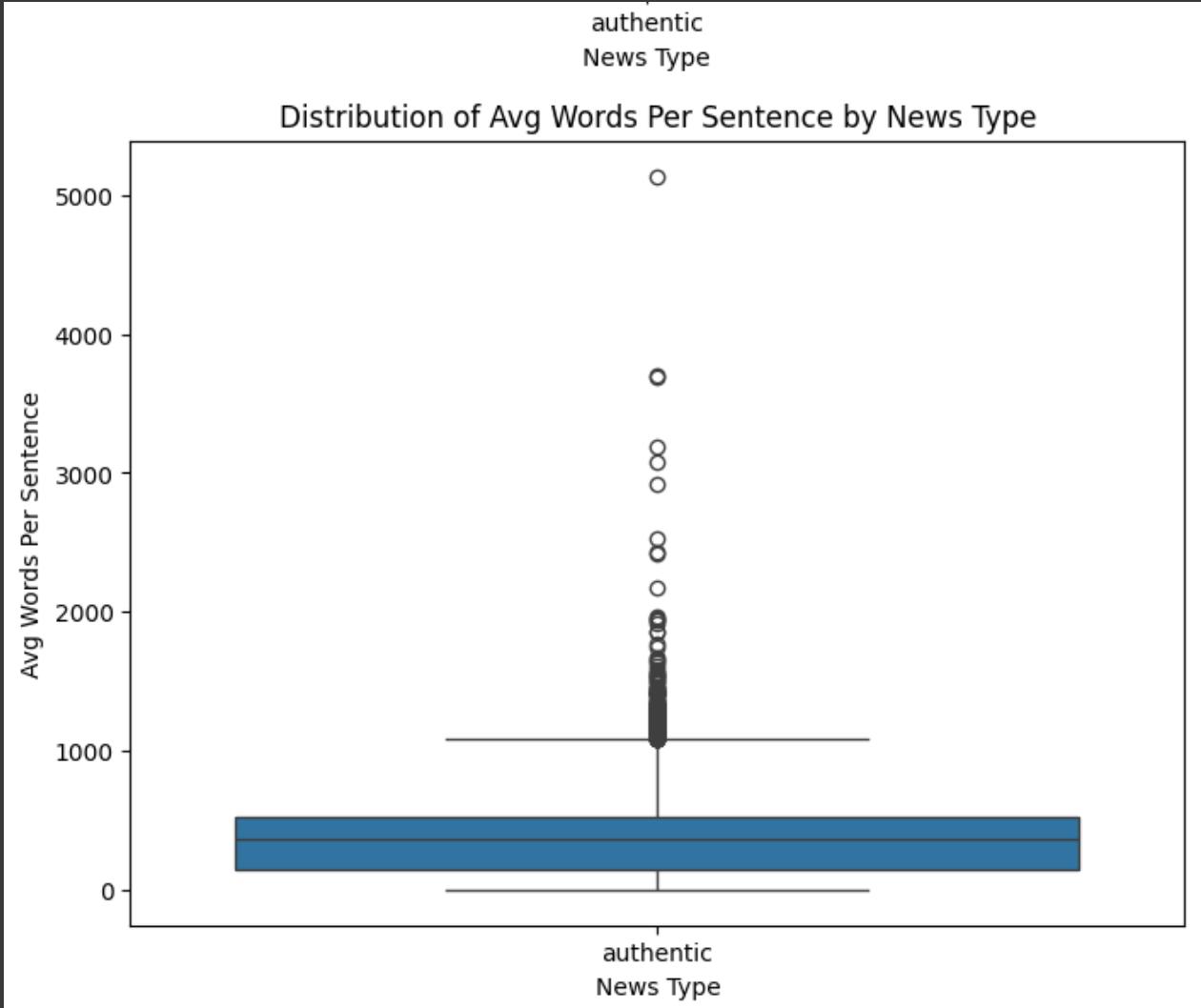
추출한 언어적 특징들을 시각화하여 진짜 뉴스와 가짜 뉴스 사이의 패턴 차이를 살펴보겠습니다.
# 언어적 특징 목록
linguistic_features = [
'avg_word_length',
'sentence_count',
'avg_words_per_sentence',
'stopwords_proportion',
'punctuation_proportion'
]
# 각 특징에 대한 박스 플롯 생성
for feature in linguistic_features:
plt.figure(figsize=(8, 6))
sns.boxplot(data=df, x='label', y=feature)
plt.title(f'{feature.replace("_", " ").title()} 분포 (뉴스 유형별)')
plt.xlabel('뉴스 유형')
plt.ylabel(feature.replace("_", " ").title())
plt.show()이 시각화를 통해 우리는 다음과 같은 통찰을 얻을 수 있습니다:
평균 단어 길이: 진짜 뉴스는 가짜 뉴스보다 약간 더 긴 단어를 사용하는 경향이 있습니다. 이는 진짜 뉴스가 더 정교한 어휘나 전문 용어를 사용할 가능성을 시사합니다.
문장 수: 가짜 뉴스는 진짜 뉴스보다 일반적으로 더 많은 문장을 포함하고 있습니다. 이는 가짜 뉴스가 더 길고 복잡한 내러티브를 구성하려는 경향을 보여줍니다.
문장당 평균 단어 수: 진짜 뉴스는 문장당 약간 더 많은 단어를 사용하는 경향이 있습니다(약 19.4단어 대 18.8단어). 이는 진짜 뉴스가 더 복잡한 문장 구조를 사용할 수 있음을 시사합니다.
불용어 비율: 가짜 뉴스와 진짜 뉴스 사이에는 불용어 사용에 있어 미묘한 차이가 있습니다. 이러한 차이는 글쓰기 스타일이나 형식성의 변화를 나타낼 수 있습니다.
구두점 비율: 진짜 뉴스는 가짜 뉴스보다 쉼표, 마침표, 물음표를 평균적으로 더 많이 사용하는 반면, 가짜 뉴스는 느낌표를 약간 더 많이 사용합니다.
언어의 지도: 가짜 뉴스를 식별하는 직관적 방법
우리의 탐구를 통해 얻은 통찰을 바탕으로, 이제 언어적 특징을 통해 가짜 뉴스를 식별하는 몇 가지 직관적인 방법을 제시해보겠습니다.
1. 텍스트 길이와 구조 살피기
진짜 뉴스와 가짜 뉴스는 텍스트 길이와 구조에서 미묘한 차이를 보입니다. 특정 주제에 대한 일반적인 뉴스 보도에 비해 지나치게 길거나 짧은 기사에 대해서는 더 주의를 기울일 필요가 있습니다.
# 텍스트 길이 계산
df['text_length'] = df['text'].apply(lambda x: len(x.split()))
# 뉴스 유형별 텍스트 길이 분포를 보여주는 히스토그램
plt.figure(figsize=(12, 6))
sns.histplot(data=df, x='text_length', hue='label', kde=True, common_norm=False)
plt.title('뉴스 유형별 텍스트 길이 분포')
plt.xlabel('텍스트 길이 (단어 수)')
plt.ylabel('빈도')
plt.xlim(0, 2000) # 주요 분포를 더 잘 시각화하기 위해 x축 제한
plt.show()이 시각화는 가짜 뉴스가 진짜 뉴스보다 일반적으로 더 넓은 텍스트 길이 분포를 가지고 있음을 보여줍니다. 또한 가짜 뉴스 중에는 진짜 뉴스에 비해 상당히 긴 텍스트를 가진 기사들이 더 많이 포함되어 있습니다.
2. 문장 구조 고려하기
진짜 뉴스는 약간 더 복잡한 문장 구조를 사용하는 경향이 있습니다. 한 기사가 일관되게 매우 짧고 단순한 문장만을 사용한다면, 이는 경계해야 할 신호일 수 있습니다.
# 뉴스 유형별 문장당 평균 단어 수를 보여주는 바이올린 플롯
plt.figure(figsize=(10, 6))
sns.violinplot(data=df, x='label', y='avg_words_per_sentence')
plt.title('뉴스 유형별 문장당 평균 단어 수 분포')
plt.xlabel('뉴스 유형')
plt.ylabel('문장당 평균 단어 수')
plt.show()이 시각화는 진짜 뉴스가 문장당 약간 더 많은 단어를 사용하는 경향을 보여줍니다. 이는 진짜 뉴스의 문장 구조가 더 복잡하거나 상세할 수 있음을 시사합니다.
3. 단어 선택에 주목하기
불용어 분석은 미묘한 차이를 보여주지만, 특정 단어 선택(흔한 단어를 넘어)에 더 깊이 주목하는 것이 중요합니다. 가짜 뉴스는 종종 더 감정적으로 충전된 언어, 과장법, 또는 근거 없는 주장을 사용할 수 있습니다.
from collections import Counter
from wordcloud import WordCloud
def get_top_n_words(corpus, n=None):
"""
불용어를 제거한 후 말뭉치에서 가장 빈번한 n개의 단어를 가져옵니다.
"""
words = []
for text in corpus:
# text가 토큰 리스트인지 확인 (preprocess_text에 의해 생성된 대로)
if isinstance(text, list):
words.extend([word for word in text if word not in stop_words and word.isalpha()])
elif isinstance(text, str):
# 처리되지 않은 텍스트에 대한 대체 방법 (processed_text를 사용해야 하지만)
tokens = word_tokenize(text.lower())
words.extend([word for word in tokens if word not in stop_words and word.isalpha()])
return Counter(words).most_common(n)
# 진짜 뉴스의 상위 단어
authentic_text = df[df['label'] == 'authentic']['text_without_stopwords']
top_authentic_words = get_top_n_words(authentic_text, 50)
# 가짜 뉴스의 상위 단어
deceptive_text = df[df['label'] == 'deceptive']['text_without_stopwords']
top_deceptive_words = get_top_n_words(deceptive_text, 50)
# 워드 클라우드 생성
def generate_word_cloud(word_counts, title):
"""
단어 수를 기반으로 워드 클라우드를 생성하고 표시합니다.
"""
wordcloud = WordCloud(width=800, height=400, background_color='white').generate_from_frequencies(dict(word_counts))
plt.figure(figsize=(10, 7))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title(title)
plt.show()
print("진짜 뉴스의 상위 50개 단어:")
print(top_authentic_words)
generate_word_cloud(top_authentic_words, '진짜 뉴스의 상위 단어')
print("\n가짜 뉴스의 상위 50개 단어:")
print(top_deceptive_words)
generate_word_cloud(top_deceptive_words, '가짜 뉴스의 상위 단어')이 워드 클라우드는 진짜 뉴스와 가짜 뉴스에서 가장 자주 사용되는 단어를 시각화합니다. 이를 통해 각 뉴스 유형에서 사용되는 어휘와 강조점의 차이를 발견할 수 있습니다. 예를 들어, 진짜 뉴스는 정치와 세계 이벤트와 관련된 공식적인 언어와 특정 이름을 더 많이 포함할 수 있는 반면, 가짜 뉴스는 더 감정적으로 충전된 언어를 사용하거나 다른 실체에 초점을 맞출 수 있습니다.
4. 구두점 사용에 주의하기
과도한 느낌표 사용이나 특이한 구두점은 때때로 선정주의의 신호일 수 있으며, 이는 가짜 콘텐츠에서 더 흔합니다.
# 뉴스 유형별 구두점 비율 분포를 보여주는 박스 플롯
plt.figure(figsize=(8, 6))
sns.boxplot(data=df, x='label', y='punctuation_proportion')
plt.title('뉴스 유형별 구두점 비율 분포')
plt.xlabel('뉴스 유형')
plt.ylabel('구두점 비율')
plt.show()이 시각화는 진짜 뉴스와 가짜 뉴스 사이의 구두점 사용 차이를 보여줍니다. 가짜 뉴스는 종종 더 선정적인 느낌을 주기 위해 구두점을 과도하게 사용할 수 있습니다.
결론: 언어의 숲에서 진실을 찾아서
우리의 분석은 진짜 뉴스와 가짜 뉴스가 종종 다른 언어적 패턴을 보여준다는 것을 보여줍니다. 텍스트 길이, 문장 구조, 단어 사용, 구두점 사용과 같은 특징을 검토함으로써, 우리는 콘텐츠의 본질에 대한 가치 있는 통찰을 얻을 수 있습니다.
그러나 이러한 언어적 단서들은 단지 정보의 내용과 출처를 확인하는 더 넓은 비판적 평가의 한 부분일 뿐임을 기억하는 것이 중요합니다. 이들은 복잡한 퍼즐의 한 조각이며, 진실을 찾아가는 여정에서 우리를 안내하는 이정표와 같습니다.
마치 고대의 항해자들이 별의 패턴을 읽어 방향을 찾았듯이, 우리도 언어의 패턴을 통해 디지털 정보의 바다에서 진실의 방향을 찾아갈 수 있습니다. 이 탐구는 단지 시작일 뿐입니다. 더 고급 자연어 처리 기술과 기계 학습 모델을 통해, 우리는 이러한 언어적 특징을 기반으로 뉴스 기사를 분류하는 더 정교한 도구를 개발할 수 있을 것입니다.
우리가 정보 풍경을 항해할 때, 이러한 통찰과 도구들이 더 밝고 명확한 길을 비춰주길 바랍니다. 진실과 허구 사이의 경계를 읽어내는 능력은, 끊임없이 변화하는 디지털 시대에서 우리에게 가장 소중한 나침반이 될 것입니다.
이 여정이 여러분에게 가짜 뉴스와 진짜 뉴스를 구별하는 더 날카로운 눈과 귀를 제공하길 바랍니다. 그리고 무엇보다, 이 연구가 우리가 공유하는 정보 생태계의 건강과 진실성을 보호하는 데 작은 기여가 되길 바랍니다.