
Google Colab의 Data Science Agent 입문자 가이드: PCA와 클러스터링 활용하기


Google Colab에서 제공하는 Data Science Agent는 데이터 분석 작업을 자동화하고 효율적으로 수행할 수 있게 도와주는 강력한 도구입니다. Data Science Agent를 사용하여 동의어-반의어 데이터셋에 주성분 분석(PCA)과 클러스터링을 적용해 보았습니다.
(로컬에 가지고 있는 데이터가 국밥맨샘이 주신 동의어 반의어 세트 밖에 없어서, 그것을 사용할 수 밖에 없었음을 양해해 주시기 바랍니다.)
Data Science Agent란 무엇인가?
Data Science Agent는 Google Colab에서 제공하는 AI 기반 도구로, 데이터 분석 계획을 제안하고 사용자와 상호작용하며 필요한 코드를 자동으로 생성하고 실행합니다.
이는 데이터 분석의 각 단계를 체계적으로 처리하면서 코드에 오류가 발생하면 자체적으로 수정하는 기능까지 갖추고 있습니다.
(필자가 데이터 사이언스에 대해 아주 기초적인 지식만을 가지고 있다는 점도 양해 부탁드립니다.)
사례 분석: 동의어-반의어 데이터셋의 PCA 및 클러스터링
이제 실제 Data Science Agent를 활용한 분석 사례를 단계별로 살펴보겠습니다.
1. 데이터 로딩 (Data Loading)
import pandas as pd
try:
df = pd.read_excel('국밥동의어반의어.xlsx')
display(df.head())
print(df.shape)
except FileNotFoundError:
print("Error: '국밥동의어반의어.xlsx' not found.")
df = None
except Exception as e:
print(f"An error occurred: {e}")핵심 인사이트: Data Science Agent는 파일이 존재하지 않거나 오류가 발생할 경우를 대비해 예외 처리 코드를 자동으로 생성합니다. 이처럼 견고한 코드 작성은 데이터 사이언스 실무에서 매우 중요합니다.

2. 데이터 탐색 (Data Exploration)
데이터 탐색 단계에서는 데이터 유형(dtypes), 결측치, 고유값 등을 확인합니다.
# 데이터 유형 확인
print(df.dtypes)
# 결측치 확인 및 개수 세기
print(df.isnull().sum())
# 범주형 열의 고유값과 빈도수 조사
for col in ['Synonym', 'Antonym']:
print(f"\n'{col}'의 고유값과 빈도수:")
print(df[col].value_counts(dropna=False))분석 결과:
'Meaning' 열에는 9개의 결측치가 있습니다.
'Synonym' 열에는 213개의 결측치가 있습니다.
'Antonym' 열에는 1981개의 결측치가 있습니다.
데이터 분석의 첫 단계는 항상 데이터를 철저히 이해하는 것입니다. Data Science Agent는 필요한 탐색 코드를 자동으로 생성하여 데이터의 구조와 특성을 파악할 수 있게 합니다.

3. 데이터 정제 (Data Wrangling)
import re
from sklearn.feature_extraction.text import TfidfVectorizer
# 결측치를 "unknown"으로 대체
df['Synonym'] = df['Synonym'].fillna("unknown")
df['Antonym'] = df['Antonym'].fillna("unknown")
# 텍스트 데이터 정제 함수
def clean_text(text):
# 소문자로 변환
text = text.lower()
# 단어 내 하이픈을 제외한 구두점 제거
text = re.sub(r"[^ws-]|_", "", text)
# 추가 공백 제거
text = " ".join(text.split())
return text
# 함수 적용
df['Synonym'] = df['Synonym'].apply(clean_text)
df['Antonym'] = df['Antonym'].apply(clean_text)
# TF-IDF 벡터 생성
vectorizer = TfidfVectorizer()
synonym_vectors = vectorizer.fit_transform(df['Synonym'])
antonym_vectors = vectorizer.transform(df['Antonym'])텍스트 데이터를 분석할 때는 정제 과정이 필수적입니다. 소문자 변환, 구두점 제거, 공백 정리 등의 과정을 통해 일관된 형태의 데이터를 준비합니다. TF-IDF 벡터화를 통해 텍스트 데이터를 수치 데이터로 변환하는 것은 머신러닝 모델링을 위한 중요한 단계입니다.
4. 특성 공학 (Feature Engineering)
import numpy as np
# PCA 입력용 데이터 프레임 준비
df_pca_input = df_processed.copy()
# 결측치 처리
print("처리 전 결측치:\n", df_pca_input.isnull().sum().sum())
df_pca_input.fillna(0, inplace=True)
print("처리 후 결측치:\n", df_pca_input.isnull().sum().sum())
# 무한값 처리
print("\n처리 전 무한값:\n", np.isinf(df_pca_input).values.sum())
df_pca_input.replace([np.inf, -np.inf], np.nan, inplace=True)
df_pca_input.fillna(df_pca_input.max(), inplace=True)
print("\n처리 후 무한값:\n", np.isinf(df_pca_input).values.sum())결측치와 무한값은 모델링 과정에서 오류를 발생시킬 수 있으므로 적절하게 처리해야 합니다. Data Science Agent는 이러한 문제를 체계적으로 확인하고 처리하는 코드를 생성합니다.
5. 데이터 표준화 (Data Standardization)
from sklearn.preprocessing import StandardScaler
# StandardScaler 객체 생성
scaler = StandardScaler()
# 데이터에 스케일러 적용
df_pca_scaled = pd.DataFrame(scaler.fit_transform(df_pca_input), columns=df_pca_input.columns)PCA를 적용하기 전 데이터 표준화는 매우 중요합니다. 각 특성의 스케일이 다를 경우, 큰 값을 가진 특성이 분석 결과를 왜곡할 수 있기 때문입니다.
6. 주성분 분석 (PCA)
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# PCA 초기화
pca = PCA()
# PCA 모델 학습
pca.fit(df_pca_scaled)
# 설명된 분산 비율 분석
explained_variance_ratio = pca.explained_variance_ratio_
cumulative_variance_ratio = np.cumsum(explained_variance_ratio)
# 누적 설명된 분산 비율 시각화
plt.figure(figsize=(10, 6))
plt.plot(range(1, len(cumulative_variance_ratio) + 1), cumulative_variance_ratio)
plt.xlabel('주성분 개수')
plt.ylabel('누적 설명된 분산 비율')
plt.title('누적 설명된 분산 비율 vs. 주성분 개수')
plt.grid(True)
plt.show()
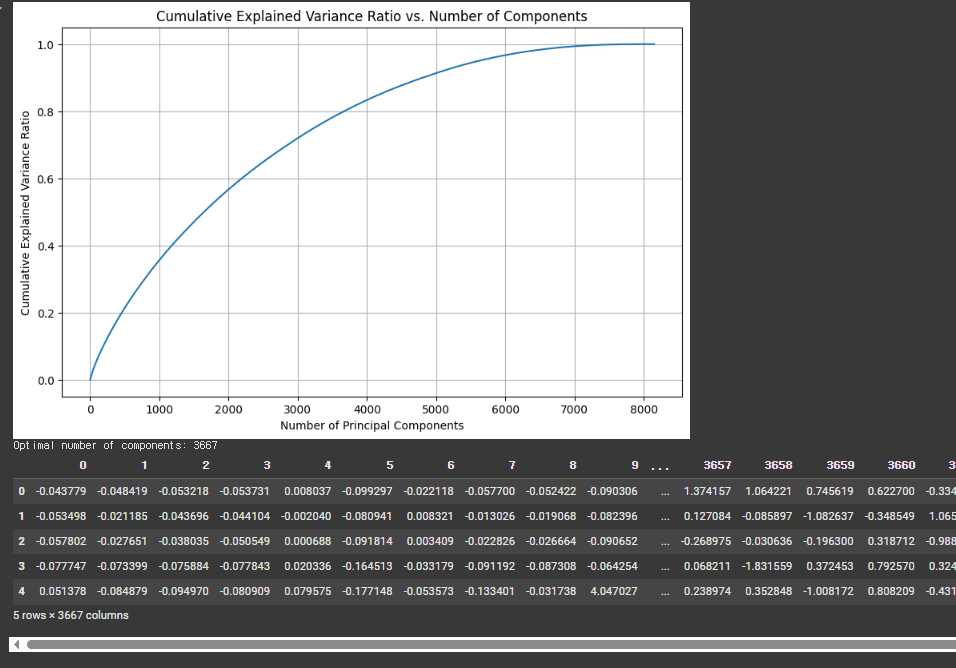
# 최적 주성분 개수 결정 (최소 80% 분산 설명)
n_components = np.argmax(cumulative_variance_ratio >= 0.8) + 1
print(f"최적 주성분 개수: {n_components}")
# 최적 주성분 개수로 PCA 재초기화
pca = PCA(n_components=n_components)
# 데이터 변환
df_pca = pd.DataFrame(pca.fit_transform(df_pca_scaled))PCA는 고차원 데이터를 저차원으로 축소하는 강력한 기법입니다. 최적의 주성분 개수를 결정하기 위해 누적 설명된 분산 비율을 분석하는 것이 일반적인 접근법입니다. 이 경우, 전체 분산의 80%를 설명하는 데 필요한 주성분 개수는 3667개로 나타났습니다.
7. K-평균 클러스터링 (K-means Clustering)
from sklearn.cluster import KMeans
# 3개 클러스터로 KMeans 초기화
kmeans = KMeans(n_clusters=3, random_state=0, n_init=10)
# KMeans 모델 학습
kmeans.fit(df_pca)
# 클러스터 레이블 추가
df_pca['cluster_label'] = kmeans.labels_클러스터링은 비슷한 특성을 가진 데이터 포인트를 그룹화하는 기법입니다. K-평균 알고리즘은 직관적이고 구현이 쉬워 널리 사용되지만, 클러스터 수(K)를 사전에 지정해야 하는 한계가 있습니다.
8. 데이터 시각화 (Data Visualization)
import matplotlib.pyplot as plt
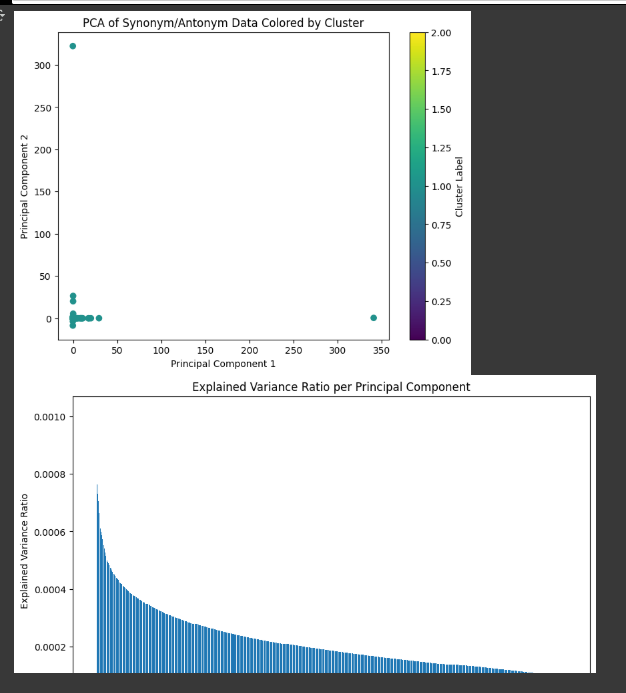
# 1. 클러스터로 색상화된 PCA 결과 산점도
plt.figure(figsize=(8, 6))
plt.scatter(df_pca[0], df_pca[1], c=df_pca['cluster_label'], cmap='viridis')
plt.xlabel('주성분 1')
plt.ylabel('주성분 2')
plt.title('클러스터별 동의어/반의어 데이터의 PCA')
plt.colorbar(label='클러스터 레이블')
plt.show()
# 2. 설명된 분산 비율의 막대 차트
plt.figure(figsize=(10, 6))
plt.bar(range(1, len(pca.explained_variance_ratio_) + 1), pca.explained_variance_ratio_)
plt.xlabel('주성분 번호')
plt.ylabel('설명된 분산 비율')
plt.title('주성분별 설명된 분산 비율')
plt.show()시각화는 데이터 분석 결과를 이해하고 전달하는 데 중요합니다.
산점도는 주성분 공간에서 데이터 포인트의 분포와 클러스터를 시각적으로 보여주며,
막대 차트는 각 주성분이 설명하는 분산의 비율을 나타냅니다.
Data Science Agent로부터 얻은 주요 인사이트
체계적인 데이터 분석 접근법: Data Science Agent는 데이터 로딩부터 시각화까지 데이터 분석의 전체 과정을 체계적으로 수행합니다. 이러한 단계별 접근법은 초보자들이 데이터 분석의 전체 흐름을 이해하는 데 도움이 됩니다.
견고한 코드 작성: 예외 처리, 결측치 및 무한값 처리 등 견고한 코드 작성 패턴을 배울 수 있습니다.
자동화된 데이터 전처리: 텍스트 정제, 벡터화, 표준화 등의 전처리 과정이 자동으로 수행되어 분석 준비 시간을 단축시킵니다.
차원 축소 및 클러스터링 기법: PCA와 K-평균 클러스터링과 같은 고급 분석 기법을 쉽게 적용할 수 있습니다.
효과적인 데이터 시각화: 분석 결과를 이해하기 쉬운 시각적 표현으로 제공합니다.
데이터 사이언스 입문자를 위한 활용 팁
단계별 코드 이해하기: Data Science Agent가 생성한 코드를 단계별로 이해하고 각 함수와 매개변수의 역할을 학습하세요.
프로세스 습득하기: 데이터 분석의 전체 흐름(로딩 → 탐색 → 정제 → 전처리 → 분석 → 시각화)을 익히고 자신의 프로젝트에 적용해 보세요.
코드 수정 및 확장하기: 생성된 코드를 기반으로 다양한 매개변수 값을 시도하거나 추가 분석 기법을 적용해 보세요.
결과 해석 능력 기르기: 시각화 결과를 해석하고 데이터에서 의미 있는 인사이트를 도출하는 능력을 키우세요.
개념 연결하기: PCA, 클러스터링 등의 기법이 어떻게 실제 문제 해결에 적용되는지 연결하여 이해하세요.
결론
Google Colab의 Data Science Agent는 데이터 사이언스 입문자에게 전문적인 데이터 분석 코드를 자동으로.생성해 주는 강력한 도구입니다. 이를 통해 데이터 분석의 전체 흐름을 배우고, 다양한 분석 기법을 익히며, 코드 작성 능력을 향상시킬 수 있습니다.
동의어-반의어 데이터셋 분석 사례를 통해 PCA와 클러스터링을 활용한 데이터 분석 과정을 이해하는 데 도움이 되었기를 바랍니다. 감사합니다.