
기계 번역 마스터하기: "Attention Is All You Need" 논문을 통해 Transformer 모델 이해하기 (Mastering Machine Translation: Understanding the Transformer Model through "Attention Is All You Need")

https://arxiv.org/pdf/1706.03762

1부: 기술 리더 및 자료 소개 (Part 1: Tech Leader and Source Material Introduction)
자료 개요 (Source Material Overview):
영어:
Title: Attention Is All You Need
Date: 2 August 2023 (arXiv preprint)
Context: Introduced the Transformer model, a novel architecture for sequence transduction, revolutionizing NLP and particularly machine translation.
Synopsis: The paper introduces the Transformer, a new neural network architecture based solely on attention mechanisms, dispensing with recurrence and convolutions. It demonstrates the model's superior performance on machine translation tasks, achieving state-of-the-art results while being more parallelizable and requiring less training time.
한국어:
제목: Attention Is All You Need (주목이 전부다)
날짜: 2023년 8월 2일 (arXiv 사전 공개)
배경: 시퀀스 변환을 위한 새로운 아키텍처인 Transformer 모델을 도입하여 NLP, 특히 기계 번역에 혁명을 일으켰습니다.
개요: 이 논문은 순환성 및 합성곱을 사용하지 않고 오직 어텐션 메커니즘에만 기반을 둔 새로운 신경망 아키텍처인 Transformer를 소개합니다. 이 모델은 기계 번역 작업에서 뛰어난 성능을 보이며, 병렬화가 더 용이하고 훈련 시간이 덜 소요되면서도 최첨단 결과를 달성합니다.
학습 목표 (Learning Objectives):
영어:
Understand and utilize advanced vocabulary related to neural networks, attention mechanisms, and machine translation.
Analyze the structure and function of the Transformer model.
Grasp the concept of self-attention and its advantages over traditional RNNs and CNNs.
Explore the applications of the Transformer in various NLP tasks.
Develop an understanding of how to effectively use prompts for interacting with AI models.
한국어:
신경망, 어텐션 메커니즘, 기계 번역과 관련된 고급 어휘를 이해하고 활용합니다.
Transformer 모델의 구조와 기능을 분석합니다.
셀프 어텐션의 개념과 기존 RNN 및 CNN 대비 장점을 파악합니다.
다양한 NLP 작업에서 Transformer의 적용 사례를 살펴봅니다.
AI 모델과의 상호 작용을 위해 프롬프트를 효과적으로 사용하는 방법에 대한 이해를 발전시킵니다.
2부: 논문 심층 분석 (Part 2: Speech/Text Deep Dive)
전체 내용/발췌 (Full Transcript/Excerpt): 논문의 주요 부분(초록, 서론, 모델 아키텍처, 결과 등)을 발췌하여 포함합니다.
섹션별 분석 (Section-by-Section Analysis):
섹션 1: 초록 (Abstract)
주제적 맥락 (Thematic Context):
영어: Introduces the Transformer model and its key features and highlights its performance on machine translation tasks.
한국어: Transformer 모델과 그 주요 특징을 소개하고 기계 번역 작업에서의 성능을 강조합니다.
어휘 집중 (Vocabulary in Focus):
영어: "sequence transduction": Converting one sequence to another. Example: "Machine translation is a classic example of sequence transduction."
한국어: "시퀀스 변환": 한 시퀀스를 다른 시퀀스로 변환하는 것. 예: "기계 번역은 시퀀스 변환의 대표적인 예입니다."
영어: "recurrent": Characterized by repetition or occurring again. Example: "Recurrent neural networks process sequences by iterating through each element."
한국어: "순환적인": 반복을 특징으로 하거나 다시 발생하는. 예: "순환 신경망은 각 요소를 반복하여 시퀀스를 처리합니다."
영어: "convolutional": Related to mathematical operation on two functions to produce a third. Example: "Convolutional neural networks are widely used in image processing."
한국어: "합성곱의": 두 함수에 대한 수학적 연산과 관련되어 세 번째 함수를 생성하는. 예: "합성곱 신경망은 이미지 처리에 널리 사용됩니다."
영어: "encoder": A component that converts input data into a coded format. Example: "The encoder transforms the input sentence into a vector representation."
한국어: "인코더": 입력 데이터를 코딩된 형식으로 변환하는 구성 요소. 예: "인코더는 입력 문장을 벡터 표현으로 변환합니다."
영어: "decoder": A component that converts coded data back into its original format. Example: "The decoder generates the output sentence based on the encoded representation."
한국어: "디코더": 코딩된 데이터를 원래 형식으로 다시 변환하는 구성 요소. 예: "디코더는 인코딩된 표현을 기반으로 출력 문장을 생성합니다."
영어: "attention mechanism": A mechanism that allows a model to focus on specific parts of the input. Example: "The attention mechanism helps the model identify the most relevant words in the input sentence."
한국어: "어텐션 메커니즘": 모델이 입력의 특정 부분에 집중할 수 있도록 하는 메커니즘. 예: "어텐션 메커니즘은 모델이 입력 문장에서 가장 관련성이 높은 단어를 식별하는 데 도움이 됩니다."
영어: "parallelizable": Able to be processed in parallel. Example: "The Transformer architecture is highly parallelizable, leading to faster training."
한국어: "병렬화 가능": 병렬로 처리될 수 있는. 예: "Transformer 아키텍처는 병렬화가 매우 뛰어나 훈련 속도가 빠릅니다."
영어: "BLEU": Bilingual Evaluation Understudy, a metric for evaluating machine translation quality. Example: "The model achieved a state-of-the-art BLEU score on the translation task."
한국어: "BLEU": 이중 언어 평가 연구, 기계 번역 품질 평가를 위한 측정 기준. 예: "이 모델은 번역 작업에서 최첨단 BLEU 점수를 달성했습니다."
영어: "generalizes": Applies broadly to different tasks or data. Example: "The Transformer model generalizes well to other NLP tasks beyond machine translation."
한국어: "일반화하다": 다양한 작업이나 데이터에 광범위하게 적용됨. 예: "Transformer 모델은 기계 번역 이외의 다른 NLP 작업에도 잘 일반화됩니다."
영어: "constituency parsing": Analyzing the grammatical structure of a sentence. Example: "The model was also evaluated on English constituency parsing."
한국어: "구문 분석": 문장의 문법적 구조를 분석하는 것. 예: "이 모델은 영어 구문 분석에서도 평가되었습니다."
문법 집중 (Grammar Spotlight):
영어: Present Perfect: "The best performing models also connect..." Explanation: Used to describe actions completed in the past that have relevance to the present. Example: "They have developed a new method."
한국어: 현재 완료: "The best performing models also connect..." (최고 성능 모델들 또한 연결합니다...) 설명: 과거에 완료되었지만 현재와 관련이 있는 동작을 설명하는 데 사용됩니다. 예: "They have developed a new method." (그들은 새로운 방법을 개발했습니다.)
수사적 분석 (Rhetorical Analysis):
영어: Use of contrast: "based solely on attention mechanisms, dispensing with recurrence and convolutions entirely." Impact: Emphasizes the novelty of the Transformer.
한국어: 대조 사용: "based solely on attention mechanisms, dispensing with recurrence and convolutions entirely." (오직 어텐션 메커니즘에만 기반을 두고, 순환성과 합성곱은 완전히 배제합니다.) 영향: Transformer의 참신함을 강조합니다.
기술 개념 연결 (Technical Concept Connection):
영어: Introduces the core concept of the Transformer relying solely on attention.
한국어: Transformer가 오직 어텐션에만 의존한다는 핵심 개념을 소개합니다.
섹션 2: 서론 (Introduction)
주제적 맥락 (Thematic Context):
영어: Provides background on recurrent and convolutional models, highlighting their limitations and introducing the Transformer as a solution.
한국어: 순환 및 합성곱 모델에 대한 배경 지식을 제공하고 그 한계를 강조하며 Transformer를 해결책으로 소개합니다.
어휘 집중 (Vocabulary in Focus):
영어: "firmly established": Recognized and accepted as being of high quality or importance. Example: "Recurrent neural networks are firmly established in the field of natural language processing."
한국어: "확고히 정립된": 높은 품질 또는 중요성을 인정받고 받아들여지는. 예: "순환 신경망은 자연어 처리 분야에서 확고히 정립되어 있습니다."
영어: "state of the art": The highest level of development at a particular time. Example: "The new model represents the state of the art in machine translation."
한국어: "최첨단": 특정 시점에서 가장 높은 수준의 발전. 예: "새로운 모델은 기계 번역의 최첨단을 보여줍니다."
영어: "transduction": The process of converting one form of energy or signal into another. Example: "Sequence transduction is a key problem in natural language processing."
한국어: "변환": 한 형태의 에너지 또는 신호를 다른 형태로 변환하는 과정. 예: "시퀀스 변환은 자연어 처리의 핵심 문제입니다."
영어: "language modeling": The task of predicting the next word in a sequence. Example: "Language modeling is essential for tasks like speech recognition and machine translation."
한국어: "언어 모델링": 시퀀스에서 다음 단어를 예측하는 작업. 예: "언어 모델링은 음성 인식 및 기계 번역과 같은 작업에 필수적입니다."
영어: "precludes": Prevents from happening; makes impossible. Example: "The sequential nature of recurrent models precludes parallelization within training examples."
한국어: "불가능하게 하다": 발생하는 것을 방지하다; 불가능하게 만들다. 예: "순환 모델의 순차적 특성은 훈련 예제 내에서 병렬화를 불가능하게 합니다."
영어: "parallelization": The process of dividing a task into smaller parts that can be processed simultaneously. Example: "Parallelization is crucial for reducing training time."
한국어: "병렬화": 작업을 동시에 처리할 수 있는 더 작은 부분으로 나누는 과정. 예: "병렬화는 훈련 시간 단축에 중요합니다."
영어: "factorization tricks": Techniques used to decompose a complex operation into simpler ones. Example: "Factorization tricks have been used to improve the efficiency of recurrent models."
한국어: "인수분해 기법": 복잡한 연산을 더 간단한 연산으로 분해하는 데 사용되는 기술. 예: "인수분해 기법은 순환 모델의 효율성을 개선하는 데 사용되었습니다."
영어: "dependencies": Relationships between different parts of a sequence. Example: "Attention mechanisms allow modeling of dependencies without regard to their distance in the input."
한국어: "종속성": 시퀀스의 서로 다른 부분 간의 관계. 예: "어텐션 메커니즘을 사용하면 입력에서 거리에 관계없이 종속성을 모델링할 수 있습니다."
영어: "eschewing": Deliberately avoiding using; abstaining from. Example: "The Transformer architecture eschews recurrence and instead relies entirely on an attention mechanism."
한국어: "피하다": 의도적으로 사용을 피하다; 삼가다. 예: "Transformer 아키텍처는 순환성을 피하고 대신 어텐션 메커니즘에 전적으로 의존합니다."
영어: "P100 GPUs": A type of graphics processing unit designed for high-performance computing. Example: "The model was trained on eight P100 GPUs."
한국어: "P100 GPU": 고성능 컴퓨팅을 위해 설계된 그래픽 처리 장치 유형. 예: "이 모델은 8개의 P100 GPU에서 훈련되었습니다."
문법 집중 (Grammar Spotlight):
영어: Present Simple for general truths: "Recurrent models typically factor computation..." Explanation and additional examples.
한국어: 일반적인 사실에 대한 현재 시제: "Recurrent models typically factor computation..." (순환 모델은 일반적으로 계산을 인수분해합니다...) 설명 및 추가 예.
수사적 분석 (Rhetorical Analysis):
영어: Problem-Solution Structure: Presents the limitations of existing models and proposes the Transformer as a solution.
한국어: 문제-해결 구조: 기존 모델의 한계를 제시하고 Transformer를 해결책으로 제안합니다.
기술 개념 연결 (Technical Concept Connection):
영어: Explains how the Transformer addresses the limitations of recurrent models through parallelization and attention.
한국어: Transformer가 병렬화와 어텐션을 통해 순환 모델의 한계를 어떻게 해결하는지 설명합니다.
모델 아키텍처 (Model Architecture)
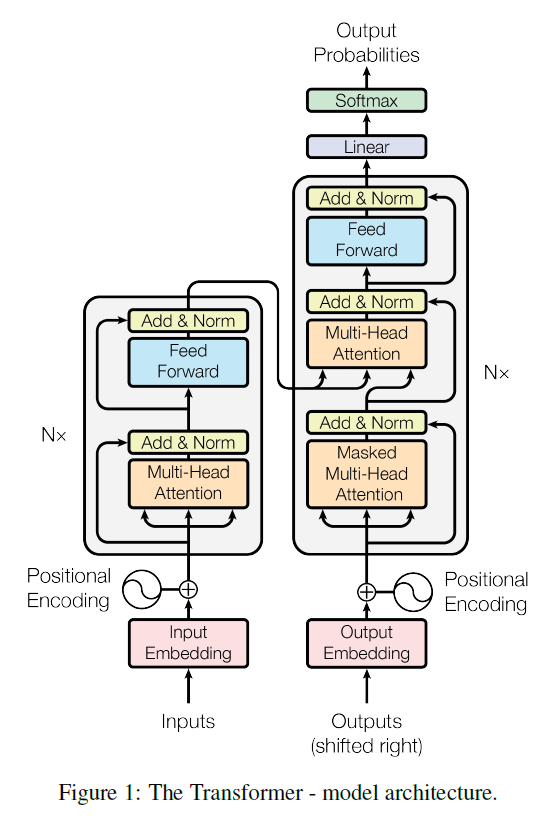
영어: The Transformer follows this overall architecture using stacked self-attention and point-wise, fully connected layers for both the encoder and decoder, shown in the left and right halves of Figure 1, respectively.
한국어: Transformer는 인코더와 디코더 모두에 스택형 셀프 어텐션과 점별 완전 연결 레이어를 사용하는 전반적인 아키텍처를 따르며, 이는 그림 1의 왼쪽과 오른쪽에 각각 표시됩니다.
인코더-디코더 스택 (Encoder-Decoder Stacks)
인코더 (Encoder):
영어: The encoder is composed of a stack of N = 6 identical layers. Each layer has two sub-layers. The first is a multi-head self-attention mechanism, and the second is a simple, position-wise fully connected feed-forward network. We employ a residual connection [11] around each of the two sub-layers, followed by layer normalization [1]. That is, the output of each sub-layer is LayerNorm(x + Sublayer(x)), where Sublayer(x) is the function implemented by the sub-layer itself. To facilitate these residual connections, all sub-layers in the model, as well as the embedding layers, produce outputs of dimension dmodel = 512.
한국어: 인코더는 N = 6개의 동일한 레이어로 구성된 스택으로 구성됩니다. 각 레이어에는 두 개의 하위 레이어가 있습니다. 첫 번째는 멀티 헤드 셀프 어텐션 메커니즘이고, 두 번째는 단순한 위치별 완전 연결 피드포워드 네트워크입니다. 두 하위 레이어 각각에 잔차 연결 [11]을 사용하고 그 뒤에 레이어 정규화 [1]를 수행합니다. 즉, 각 하위 레이어의 출력은 LayerNorm(x + Sublayer(x))이며, 여기서 Sublayer(x)는 하위 레이어 자체에서 구현된 함수입니다. 이러한 잔차 연결을 용이하게 하기 위해 모델의 모든 하위 레이어와 임베딩 레이어는 dmodel = 512 차원의 출력을 생성합니다.
어휘 집중(Vocabulary Focus):
영어: "identical" (adjective): Similar in every detail; exactly alike. Example: "The six layers in the encoder are identical."
한국어: "동일한" (형용사): 모든 세부 사항이 유사한; 완전히 똑같은. 예: "인코더의 6개 레이어는 동일합니다."
영어: "residual connection" (noun): A connection that adds the input of a layer to its output. Example: "Residual connections help to improve the training of deep networks."
한국어: "잔차 연결" (명사): 레이어의 입력과 출력을 더하는 연결. 예: "잔차 연결은 심층 네트워크의 훈련을 개선하는 데 도움이 됩니다."
영어: "layer normalization" (noun): A technique that normalizes the activations of a layer. Example: "Layer normalization helps to stabilize the training process."
한국어: "레이어 정규화" (명사): 레이어의 활성화를 정규화하는 기술. 예: "레이어 정규화는 훈련 과정을 안정화하는 데 도움이 됩니다."
영어: "facilitate" (verb): Make (an action or process) easy or easier. Example: "The use of residual connections facilitates the training of deeper networks."
한국어: "용이하게 하다" (동사): (작업이나 과정을) 쉽거나 더 쉽게 만들다. 예: "잔차 연결을 사용하면 더 깊은 네트워크의 훈련이 용이해집니다."
영어: "embedding layers" (noun): Layers that convert discrete input tokens into continuous vector representations. Example: "Embedding layers are commonly used in natural language processing models."
한국어: "임베딩 레이어" (명사): 이산 입력 토큰을 연속 벡터 표현으로 변환하는 레이어. 예: "임베딩 레이어는 자연어 처리 모델에서 일반적으로 사용됩니다."
디코더 (Decoder):
영어: The decoder is also composed of a stack of N = 6 identical layers. In addition to the two sub-layers in each encoder layer, the decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack. Similar to the encoder, we employ residual connections around each of the sub-layers, followed by layer normalization. We also modify the self-attention sub-layer in the decoder stack to prevent positions from attending to subsequent positions. This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position i can depend only on the known outputs at positions less than i.
한국어: 디코더도 N = 6개의 동일한 레이어로 구성된 스택으로 구성됩니다. 각 인코더 레이어의 두 하위 레이어 외에도 디코더는 인코더 스택의 출력에 대해 멀티 헤드 어텐션을 수행하는 세 번째 하위 레이어를 삽입합니다. 인코더와 유사하게 각 하위 레이어에 잔차 연결을 사용하고 그 뒤에 레이어 정규화를 수행합니다. 또한 디코더 스택의 셀프 어텐션 하위 레이어를 수정하여 위치가 후속 위치에 주의를 기울이는 것을 방지합니다. 이러한 마스킹은 출력 임베딩이 한 위치만큼 오프셋된다는 사실과 결합되어 위치 i에 대한 예측이 위치 i보다 작은 위치의 알려진 출력에만 의존할 수 있도록 합니다.
어휘 집중(Vocabulary Focus):
영어: "in addition to" (prepositional phrase): As well as; besides. Example: "In addition to the two sub-layers, the decoder has a third sub-layer."
한국어: "~ 외에도" (전치사구): ~뿐만 아니라; ~ 이외에. 예: "두 하위 레이어 외에도 디코더에는 세 번째 하위 레이어가 있습니다."
영어: "inserts" (verb): Places, fits, or pushes something into something else. Example: "The decoder inserts a third sub-layer for multi-head attention."
한국어: "삽입하다" (동사): 어떤 것을 다른 것 안에 배치하거나 끼우거나 밀어 넣다. 예: "디코더는 멀티 헤드 어텐션을 위해 세 번째 하위 레이어를 삽입합니다."
영어: "modify" (verb): Make partial or minor changes to something. Example: "We modify the self-attention sub-layer to prevent attending to subsequent positions."
한국어: "수정하다" (동사): 어떤 것을 부분적으로 또는 약간 변경하다. 예: "후속 위치에 주의를 기울이는 것을 방지하기 위해 셀프 어텐션 하위 레이어를 수정합니다."
영어: "subsequent" (adjective): Coming after something in time; following. Example: "The masking prevents positions from attending to subsequent positions."
한국어: "후속" (형용사): 시간상 어떤 것 다음에 오는; 뒤따르는. 예: "마스킹은 위치가 후속 위치에 주의를 기울이는 것을 방지합니다."
영어: "masking" (noun): The technique of preventing certain positions from being considered during computation. Example: "Masking ensures that predictions depend only on known outputs."
한국어: "마스킹" (명사): 계산 중에 특정 위치가 고려되지 않도록 하는 기술. 예: "마스킹은 예측이 알려진 출력에만 의존하도록 합니다."
어텐션 (Attention)
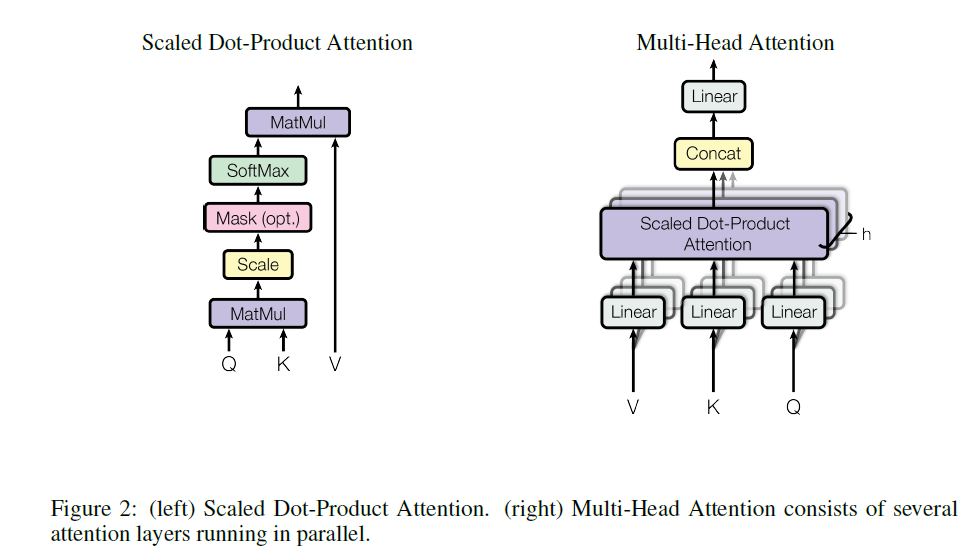
영어: An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
한국어: 어텐션 함수는 쿼리와 키-값 쌍 집합을 출력에 매핑하는 것으로 설명할 수 있으며, 여기서 쿼리, 키, 값, 출력은 모두 벡터입니다. 출력은 값의 가중 합계로 계산되며, 각 값에 할당된 가중치는 쿼리와 해당 키의 호환성 함수에 의해 계산됩니다.
어휘 집중(Vocabulary Focus):
영어: "mapping" (noun): A mathematical relationship between sets. Example: "Attention can be seen as a mapping from a query to a set of key-value pairs."
한국어: "매핑" (명사): 집합 간의 수학적 관계. 예: "어텐션은 쿼리에서 키-값 쌍 집합으로의 매핑으로 볼 수 있습니다."
영어: "weighted sum" (noun): A sum where each term is multiplied by a weight. Example: "The output of the attention function is a weighted sum of the values."
한국어: "가중 합계" (명사): 각 항에 가중치가 곱해진 합계. 예: "어텐션 함수의 출력은 값의 가중 합계입니다."
영어: "compatibility function" (noun): A function that determines the compatibility between two inputs. Example: "The compatibility function of the query and key determines the attention weight."
한국어: "호환성 함수" (명사): 두 입력 간의 호환성을 결정하는 함수. 예: "쿼리와 키의 호환성 함수는 어텐션 가중치를 결정합니다."
영어: "corresponding" (adjective): Analogous or equivalent in character, form, or function. Example: "The weight is computed by the compatibility function of the query with the corresponding key."
한국어: "해당하는" (형용사): 특성, 형태 또는 기능이 유사하거나 동등한. 예: "가중치는 쿼리와 해당 키의 호환성 함수에 의해 계산됩니다."
멀티 헤드 어텐션 (Multi-Head Attention)
영어: Instead of performing a single attention function with dmodel-dimensional keys, values and queries, we found it beneficial to linearly project the queries, keys and values h times with different, learned linear projections to dk, dk and dv dimensions, respectively. On each of these projected versions of queries, keys and values we then perform the attention function in parallel, yielding dv-dimensional output values. These are concatenated and once again projected, resulting in the final values, as depicted in Figure 2. Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. With a single attention head, averaging inhibits this.
한국어: dmodel 차원의 키, 값, 쿼리로 단일 어텐션 함수를 수행하는 대신, 쿼리, 키, 값을 각각 dk, dk, dv 차원으로 h번 다르게 학습된 선형 투영을 하는 것이 유익하다는 것을 발견했습니다. 이러한 투영된 버전의 쿼리, 키, 값에 대해 병렬로 어텐션 함수를 수행하여 dv 차원의 출력 값을 생성합니다. 이를 결합하고 다시 투영하여 그림 2와 같이 최종 값을 생성합니다. 멀티 헤드 어텐션을 사용하면 모델이 서로 다른 위치에 있는 서로 다른 표현 하위 공간의 정보에 공동으로 주의를 기울일 수 있습니다. 단일 어텐션 헤드를 사용하면 평균화로 인해 이러한 기능이 제한됩니다.
어휘 집중(Vocabulary Focus):
영어: "beneficial" (adjective): Favorable or advantageous; resulting in good. Example: "We found it beneficial to use multiple attention heads."
한국어: "유익한" (형용사): 호의적이거나 유리한; 좋은 결과를 낳는. 예: "멀티 헤드 어텐션을 사용하는 것이 유익하다는 것을 발견했습니다."
영어: "linearly project" (verb): Transform a vector using a linear transformation. Example: "We linearly project the queries, keys, and values to different dimensions."
한국어: "선형 투영하다" (동사): 선형 변환을 사용하여 벡터를 변환하다. 예: "쿼리, 키, 값을 서로 다른 차원으로 선형 투영합니다."
영어: "in parallel" (adverb): At the same time; simultaneously. Example: "The attention function is performed in parallel on each projected version."
한국어: "병렬로" (부사): 동시에. 예: "어텐션 함수는 각 투영된 버전에 대해 병렬로 수행됩니다."
영어: "concatenated" (adjective): Joined together end to end. Example: "The outputs from each head are concatenated."
한국어: "연결된" (형용사): 끝과 끝이 이어진. 예: "각 헤드의 출력이 연결됩니다."
영어: "jointly attend" (verb): Pay attention to multiple things at the same time. Example: "Multi-head attention allows the model to jointly attend to information from different subspaces."
한국어: "공동으로 주의를 기울이다" (동사): 여러 가지에 동시에 주의를 기울이다. 예: "멀티 헤드 어텐션을 사용하면 모델이 서로 다른 하위 공간의 정보에 공동으로 주의를 기울일 수 있습니다."
영어: "representation subspaces" (noun): Different parts or aspects of the representation space. Example: "Different attention heads can attend to different representation subspaces."
한국어: "표현 하위 공간" (명사): 표현 공간의 서로 다른 부분 또는 측면. 예: "서로 다른 어텐션 헤드는 서로 다른 표현 하위 공간에 주의를 기울일 수 있습니다."
영어: "inhibits" (verb): Hinders, restrains, or prevents (an action or process). Example: "With a single attention head, averaging inhibits the ability to attend to different subspaces."
한국어: "제한하다" (동사): (행동이나 과정을) 방해하거나, 억제하거나, 막다. 예: "단일 어텐션 헤드를 사용하면 평균화로 인해 서로 다른 하위 공간에 주의를 기울이는 기능이 제한됩니다."
위치별 피드포워드 네트워크 (Position-wise Feed-Forward Networks)
영어: In addition to attention sub-layers, each of the layers in our encoder and decoder contains a fully connected feed-forward network, which is applied to each position separately and identically. This consists of two linear transformations with a ReLU activation in between. FFN(x) = max(0, xW1 + b1)W2 + b2. While the linear transformations are the same across different positions, they use different parameters from layer to layer. Another way of describing this is as two convolutions with kernel size 1. The dimensionality of input and output is dmodel = 512, and the inner-layer has dimensionality dff = 2048.
한국어: 어텐션 하위 레이어 외에도 인코더와 디코더의 각 레이어에는 각 위치에 별도로 동일하게 적용되는 완전 연결 피드포워드 네트워크가 포함되어 있습니다. 이는 두 개의 선형 변환과 그 사이에 ReLU 활성화 함수로 구성됩니다. FFN(x) = max(0, xW1 + b1)W2 + b2. 선형 변환은 서로 다른 위치에서 동일하지만 레이어마다 다른 매개변수를 사용합니다. 이를 설명하는 또 다른 방법은 커널 크기가 1인 두 개의 합성곱으로 설명하는 것입니다. 입력 및 출력 차원은 dmodel = 512이고 내부 레이어의 차원은 dff = 2048입니다.
어휘 집중(Vocabulary Focus):
영어: "fully connected" (adjective): A type of neural network where each neuron is connected to every neuron in the previous and next layers. Example: "The feed-forward network is fully connected."
한국어: "완전 연결된" (형용사): 각 뉴런이 이전 및 다음 레이어의 모든 뉴런에 연결된 신경망 유형. 예: "피드포워드 네트워크는 완전 연결되어 있습니다."
영어: "ReLU" (noun): Rectified Linear Unit, a type of activation function. Example: "ReLU is a commonly used activation function in neural networks."
한국어: "ReLU" (명사): 정류 선형 유닛, 활성화 함수 유형. 예: "ReLU는 신경망에서 일반적으로 사용되는 활성화 함수입니다."
영어: "kernel size" (noun): The size of the filter used in a convolution operation. Example: "A kernel size of 1 means that each output is only affected by one input."
한국어: "커널 크기" (명사): 합성곱 연산에 사용되는 필터의 크기. 예: "커널 크기가 1이면 각 출력이 하나의 입력에만 영향을 받는다는 것을 의미합니다."
임베딩 및 소프트맥스 (Embeddings and Softmax)

영어: Similarly to other sequence transduction models, we use learned embeddings to convert the input tokens and output tokens to vectors of dimension dmodel. We also use the usual learned linear transformation and softmax function to convert the decoder output to predicted next-token probabilities. In our model, we share the same weight matrix between the two embedding layers and the pre-softmax linear transformation, similar to [30]. In the embedding layers, we multiply those weights by √dmodel.
한국어: 다른 시퀀스 변환 모델과 유사하게, 학습된 임베딩을 사용하여 입력 토큰과 출력 토큰을 dmodel 차원의 벡터로 변환합니다. 또한 일반적인 학습된 선형 변환과 소프트맥스 함수를 사용하여 디코더 출력을 예측된 다음 토큰 확률로 변환합니다. 우리 모델에서는 [30]과 유사하게 두 임베딩 레이어와 사전 소프트맥스 선형 변환 간에 동일한 가중치 행렬을 공유합니다. 임베딩 레이어에서는 해당 가중치에 √dmodel을 곱합니다.
어휘 집중(Vocabulary Focus):
영어: "learned embeddings" (noun): Vector representations of words or tokens that are learned during training. Example: "Learned embeddings capture semantic relationships between words."
한국어: "학습된 임베딩" (명사): 학습 중에 학습되는 단어 또는 토큰의 벡터 표현. 예: "학습된 임베딩은 단어 간의 의미 관계를 포착합니다."
영어: "weight matrix" (noun): A matrix of weights used in a linear transformation. Example: "The same weight matrix is shared between the embedding layers and the pre-softmax linear transformation."
한국어: "가중치 행렬" (명사): 선형 변환에 사용되는 가중치 행렬. 예: "동일한 가중치 행렬이 임베딩 레이어와 사전 소프트맥스 선형 변환 간에 공유됩니다."
위치 인코딩 (Positional Encoding)
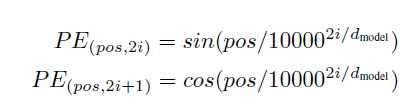
영어: Since our model contains no recurrence and no convolution, in order for the model to make use of the order of the sequence, we must inject some information about the relative or absolute position of the tokens in the sequence. To this end, we add "positional encodings" to the input embeddings at the bottoms of the encoder and decoder stacks. The positional encodings have the same dimension dmodel as the embeddings, so that the two can be summed. There are many choices of positional encodings, learned and fixed [9].
한국어: 우리 모델에는 순환이나 합성곱이 없으므로 모델이 시퀀스의 순서를 활용하려면 시퀀스 내 토큰의 상대적 또는 절대적 위치에 대한 일부 정보를 주입해야 합니다. 이를 위해 인코더 및 디코더 스택 하단에 있는 입력 임베딩에 "위치 인코딩"을 추가합니다. 위치 인코딩은 임베딩과 동일한 차원 dmodel을 가지므로 두 개를 합산할 수 있습니다. 학습 및 고정 [9]을 포함하여 다양한 위치 인코딩 선택이 있습니다.
어휘 집중(Vocabulary Focus):
영어: "inject" (verb): Introduce something new or different. Example: "We inject positional information into the input embeddings."
한국어: "주입하다" (동사): 새롭거나 다른 것을 도입하다. 예: "입력 임베딩에 위치 정보를 주입합니다."
영어: "relative or absolute position" (noun): The position of a token with respect to other tokens or a fixed reference point. Example: "Positional encodings provide information about the relative or absolute position of tokens."
한국어: "상대적 또는 절대적 위치" (명사): 다른 토큰 또는 고정된 기준점에 대한 토큰의 위치. 예: "위치 인코딩은 토큰의 상대적 또는 절대적 위치에 대한 정보를 제공합니다."
영어: "summed" (verb): Added together. Example: "The positional encodings are summed with the input embeddings."
한국어: "합산된" (동사): 함께 더해진. 예: "위치 인코딩은 입력 임베딩과 합산됩니다."
셀프 어텐션을 사용하는 이유 (Why Self-Attention)
영어: In this section we compare various aspects of self-attention layers to the recurrent and convolutional layers commonly used for mapping one variable-length sequence of symbol representations (x1, ..., xn) to another sequence of equal length (z1, ..., zn), with xi, zi ∈ Rd, such as a hidden layer in a typical sequence transduction encoder or decoder. Motivating our use of self-attention we consider three desiderata.
한국어: 이 섹션에서는 가변 길이 기호 표현 시퀀스 (x1, ..., xn)을 전형적인 시퀀스 변환 인코더 또는 디코더의 은닉층과 같이 동일한 길이 (z1, ..., zn)의 다른 시퀀스로 매핑하는 데 일반적으로 사용되는 순환 및 합성곱 레이어와 셀프 어텐션 레이어의 다양한 측면을 비교합니다. 여기서 xi, zi ∈ Rd입니다. 셀프 어텐션을 사용하는 동기로 세 가지 필요 조건을 고려합니다.
어휘 집중(Vocabulary Focus):
영어: "variable-length sequence" (noun): A sequence whose length is not fixed. Example: "Natural language sentences are typically variable-length sequences."
한국어: "가변 길이 시퀀스" (명사): 길이가 고정되지 않은 시퀀스. 예: "자연어 문장은 일반적으로 가변 길이 시퀀스입니다."
영어: "desiderata" (noun): Things that are desired or needed. Plural of desideratum. Example: "We consider three desiderata when choosing an architecture."
한국어: "필요 조건" (명사): 바람직하거나 필요한 것들. desideratum의 복수형. 예: "아키텍처를 선택할 때 세 가지 필요 조건을 고려합니다."
훈련 (Training)
데이터, 하드웨어, 옵티마이저, 정규화 (Data, Hardware, Optimizer, Regularization)
영어: This section describes the training regime for our models. We trained on the standard WMT 2014 English-German dataset consisting of about 4.5 million sentence pairs. Sentences were encoded using byte-pair encoding [3], which has a shared source-target vocabulary of about 37000 tokens. For English-French, we used the significantly larger WMT 2014 English-French dataset consisting of 36M sentences and split tokens into a 32000 word-piece vocabulary [38]. Sentence pairs were batched together by approximate sequence length. Each training batch contained a set of sentence pairs containing approximately 25000 source tokens and 25000 target tokens. We trained our models on one machine with 8 NVIDIA P100 GPUs. For our base models using the hyperparameters described throughout the paper, each training step took about 0.4 seconds. We trained the base models for a total of 100,000 steps or 12 hours. For our big models, (described on the bottom line of table 3), step time was 1.0 seconds. The big models were trained for 300,000 steps (3.5 days). We used the Adam optimizer [20] with β1 = 0.9, β2 = 0.98 and ε = 10-9. We varied the learning rate over the course of training, according to the formula: lrate = dmodel^(-0.5) * min(step_num^(-0.5), step_num * warmup_steps^(-1.5)). This corresponds to increasing the learning rate linearly for the first warmup_steps training steps, and decreasing it thereafter proportionally to the inverse square root of the step number. We used warmup_steps = 4000. We employ three types of regularization during training:
한국어: 이 섹션에서는 우리 모델의 훈련 체제에 대해 설명합니다. 약 450만 개의 문장 쌍으로 구성된 표준 WMT 2014 영어-독일어 데이터 세트에서 훈련했습니다. 문장은 약 37000개의 토큰으로 구성된 공유 소스-대상 어휘를 가진 바이트 쌍 인코딩 [3]을 사용하여 인코딩되었습니다. 영어-프랑스어의 경우, 3600만 개의 문장으로 구성되고 토큰을 32000개의 단어 조각 어휘 [38]로 분할한 상당히 더 큰 WMT 2014 영어-프랑스어 데이터 세트를 사용했습니다. 문장 쌍은 대략적인 시퀀스 길이에 따라 함께 일괄 처리되었습니다. 각 훈련 배치는 대략 25000개의 소스 토큰과 25000개의 대상 토큰을 포함하는 일련의 문장 쌍을 포함했습니다. 8개의 NVIDIA P100 GPU가 장착된 한 대의 머신에서 모델을 훈련했습니다. 논문 전체에서 설명된 하이퍼파라미터를 사용하는 기본 모델의 경우 각 훈련 단계는 약 0.4초가 걸렸습니다. 기본 모델을 총 100,000단계 또는 12시간 동안 훈련했습니다. 대형 모델(표 3의 맨 아래 줄에 설명됨)의 경우 단계 시간은 1.0초였습니다. 대형 모델은 300,000단계(3.5일) 동안 훈련되었습니다. β1 = 0.9, β2 = 0.98, ε = 10-9인 Adam 옵티마이저 [20]를 사용했습니다. 훈련 과정에서 학습률을 공식에 따라 변경했습니다: lrate = dmodel^(-0.5) * min(step_num^(-0.5), step_num * warmup_steps^(-1.5)). 이는 처음 warmup_steps 훈련 단계 동안 학습률을 선형적으로 증가시킨 다음 단계 수의 역 제곱근에 비례하여 감소시키는 것에 해당합니다. warmup_steps = 4000을 사용했습니다. 훈련 중에 세 가지 유형의 정규화를 사용합니다.
어휘 집중(Vocabulary Focus):
영어: "regime" (noun): A system or planned way of doing things. Example: "The training regime for our models is described in this section."
한국어: "체제" (명사): 일을 하는 시스템 또는 계획된 방식. 예: "우리 모델의 훈련 체제는 이 섹션에 설명되어 있습니다."
영어: "byte-pair encoding" (noun): A data compression technique that iteratively merges the most frequent pair of bytes in a sequence. Example: "Sentences were encoded using byte-pair encoding."
한국어: "바이트 쌍 인코딩" (명사): 시퀀스에서 가장 빈번한 바이트 쌍을 반복적으로 병합하는 데이터 압축 기술. 예: "문장은 바이트 쌍 인코딩을 사용하여 인코딩되었습니다."
영어: "word-piece vocabulary" (noun): A vocabulary where words are split into subword units. Example: "We used a 32000 word-piece vocabulary for English-French."
한국어: "단어 조각 어휘" (명사): 단어가 하위 단어 단위로 분할되는 어휘. 예: "영어-프랑스어에 32000개의 단어 조각 어휘를 사용했습니다."
영어: "batched" (verb): Grouped together. Example: "Sentence pairs were batched together by approximate sequence length."
한국어: "일괄 처리된" (동사): 함께 그룹화된. 예: "문장 쌍은 대략적인 시퀀스 길이에 따라 함께 일괄 처리되었습니다."
영어: "hyperparameters" (noun): Parameters whose values are set before training begins. Example: "We used the hyperparameters described throughout the paper."
한국어: "하이퍼파라미터" (명사): 훈련이 시작되기 전에 값이 설정되는 매개변수. 예: "논문 전체에서 설명된 하이퍼파라미터를 사용했습니다."
영어: "optimizer" (noun): An algorithm used to update the parameters of a model during training. Example: "We used the Adam optimizer."
한국어: "옵티마이저" (명사): 훈련 중에 모델의 매개변수를 업데이트하는 데 사용되는 알고리즘. 예: "Adam 옵티마이저를 사용했습니다."
영어: "learning rate" (noun): A hyperparameter that controls how much the parameters of a model are updated during training. Example: "We varied the learning rate over the course of training."
한국어: "학습률" (명사): 훈련 중에 모델의 매개변수가 얼마나 업데이트되는지 제어하는 하이퍼파라미터. 예: "훈련 과정에서 학습률을 변경했습니다."
영어: "regularization" (noun): Techniques used to prevent overfitting. Example: "We employ three types of regularization during training."
한국어: "정규화" (명사): 과적합을 방지하는 데 사용되는 기술. 예: "훈련 중에 세 가지 유형의 정규화를 사용합니다."
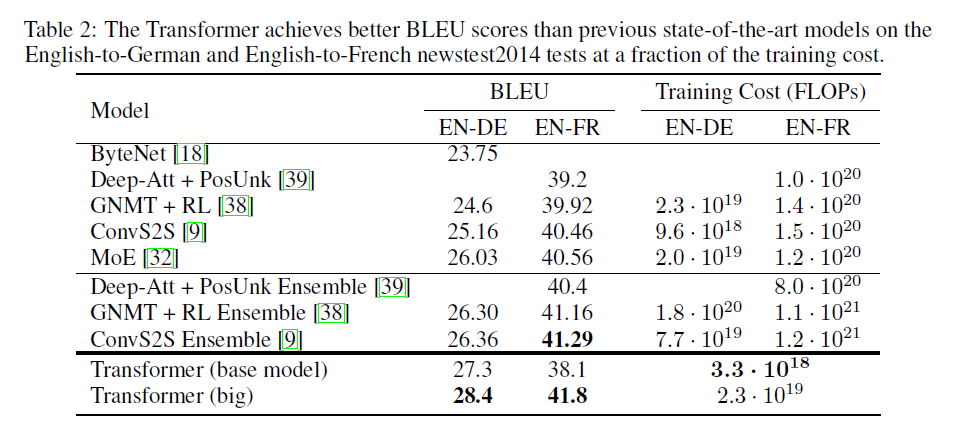
결과 (Results)
기계 번역, 모델 변형, 영어 구문 분석 (Machine Translation, Model Variations, English Constituency Parsing)
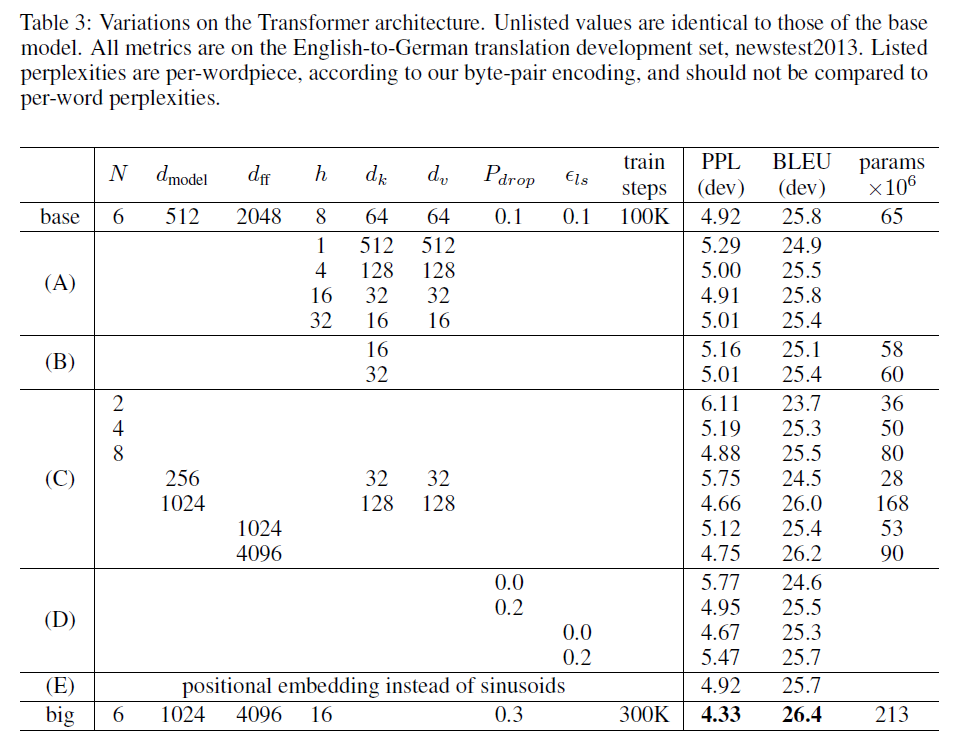
영어: On the WMT 2014 English-to-German translation task, the big transformer model (Transformer (big) in Table 2) outperforms the best previously reported models (including ensembles) by more than 2.0 BLEU, establishing a new state-of-the-art BLEU score of 28.4. The configuration of this model is listed in the bottom line of Table 3. Training took 3.5 days on 8 P100 GPUs. Even our base model surpasses all previously published models and ensembles, at a fraction of the training cost of any of the competitive models. On the WMT 2014 English-to-French translation task, our big model achieves a BLEU score of 41.0, outperforming all of the previously published single models, at less than 1/4 the training cost of the previous state-of-the-art model. The Transformer (big) model trained for English-to-French used dropout rate Pdrop = 0.1, instead of 0.3. To evaluate the importance of different components of the Transformer, we varied our base model in different ways, measuring the change in performance on English-to-German translation on the development set, newstest2013. We used beam search as described in the previous section, but no checkpoint averaging. We present these results in Table 3.
한국어: WMT 2014 영어-독일어 번역 작업에서 대형 Transformer 모델(표 2의 Transformer (big))은 이전에 보고된 최고 모델(앙상블 포함)보다 2.0 이상의 BLEU 점수로 능가하여 새로운 최고 BLEU 점수인 28.4를 수립했습니다. 이 모델의 구성은 표 3의 맨 아래 줄에 나열되어 있습니다. 훈련은 8개의 P100 GPU에서 3.5일이 걸렸습니다. 기본 모델조차도 경쟁 모델의 훈련 비용의 일부로 모든 이전에 게시된 모델과 앙상블을 능가합니다. WMT 2014 영어-프랑스어 번역 작업에서 대형 모델은 BLEU 점수 41.0을 달성하여 이전 최고 모델의 훈련 비용의 1/4 미만으로 이전에 게시된 모든 단일 모델을 능가합니다. 영어-프랑스어용으로 훈련된 Transformer (big) 모델은 0.3 대신 드롭아웃 비율 Pdrop = 0.1을 사용했습니다. Transformer의 서로 다른 구성 요소의 중요성을 평가하기 위해 개발 세트 newstest2013에서 영어-독일어 번역 성능의 변화를 측정하여 기본 모델을 다양하게 변경했습니다. 이전 섹션에서 설명한 대로 빔 검색을 사용했지만 체크포인트 평균화는 사용하지 않았습니다. 이러한 결과는 표 3에 나와 있습니다.
어휘 집중(Vocabulary Focus):
영어: "outperforms" (verb): Performs better than. Example: "The big transformer model outperforms the best previously reported models."
한국어: "능가하다" (동사): ~보다 더 나은 성능을 보이다. 예: "대형 Transformer 모델은 이전에 보고된 최고 모델을 능가합니다."
영어: "state-of-the-art" (adjective): The highest level of development at a particular time. Example: "The model establishes a new state-of-the-art BLEU score."
한국어: "최첨단" (형용사): 특정 시점에서 가장 높은 수준의 발전. 예: "이 모델은 새로운 최첨단 BLEU 점수를 수립합니다."
영어: "configuration" (noun): The way in which something is arranged. Example: "The configuration of this model is listed in Table 3."
한국어: "구성" (명사): 어떤 것이 배열되는 방식. 예: "이 모델의 구성은 표 3에 나열되어 있습니다."
영어: "at a fraction of the cost" (prepositional phrase): For a small part of the cost. Example: "Our base model surpasses all previously published models at a fraction of the training cost."
한국어: "비용의 일부로" (전치사구): 적은 비용으로. 예: "기본 모델은 훈련 비용의 일부로 이전에 게시된 모든 모델을 능가합니다."
영어: "beam search" (noun): A heuristic search algorithm that explores a graph by expanding the most promising node in a limited set. Example: "We used beam search during inference."
한국어: "빔 검색" (명사): 제한된 집합에서 가장 유망한 노드를 확장하여 그래프를 탐색하는 휴리스틱 검색 알고리즘. 예: "추론 중에 빔 검색을 사용했습니다."
영어: "checkpoint averaging" (noun): A technique where the parameters of a model are averaged over multiple checkpoints during training. Example: "We did not use checkpoint averaging in this experiment."
한국어: "체크포인트 평균화" (명사): 훈련 중 여러 체크포인트에 걸쳐 모델의 매개변수를 평균화하는 기술. 예: "이 실험에서는 체크포인트 평균화를 사용하지 않았습니다."
3부: AI/기술 개념 심층 분석 (Part 3: AI/Technology Concept Deep Dive)
개념 (Concept): 셀프 어텐션 메커니즘 (Self-Attention Mechanism)
복습 (Review):
영어: Briefly reintroduce the concept of self-attention as the core mechanism of the Transformer.
한국어: Transformer의 핵심 메커니즘인 셀프 어텐션의 개념을 간략하게 다시 소개합니다.
상세 설명 (Detailed Explanation):
영어:
Explain how self-attention allows the model to weigh the importance of different words in a sequence when encoding a specific word.
Describe the process of calculating attention scores using queries, keys, and values.
Explain the role of scaled dot-product attention and multi-head attention.
Discuss the advantages of self-attention over RNNs and CNNs in terms of parallelization and capturing long-range dependencies. (Leverage Stage 1 analysis)
한국어:
셀프 어텐션이 특정 단어를 인코딩할 때 시퀀스 내 단어의 중요도에 가중치를 부여하는 방법을 설명합니다.
쿼리, 키, 값을 사용하여 어텐션 점수를 계산하는 과정을 설명합니다.
스케일드 닷-프로덕트 어텐션과 멀티 헤드 어텐션의 역할을 설명합니다.
병렬화 및 장거리 의존성 캡처 측면에서 RNN 및 CNN 대비 셀프 어텐션의 장점에 대해 논의합니다. (1단계 분석 활용)
실제 적용 사례 (Real-World Application Showcase):
사례 연구 1: 기계 번역 (Case Study 1: Machine Translation)
영어: Explain how self-attention enables the Transformer to outperform traditional models in translation tasks by capturing relationships between words in different languages. Include an AI-generated image of a sentence being translated, with attention weights highlighted.
한국어: 셀프 어텐션이 어떻게 Transformer가 서로 다른 언어의 단어 간 관계를 포착하여 번역 작업에서 기존 모델을 능가할 수 있는지 설명합니다. 번역 중인 문장에 어텐션 가중치가 강조된 AI 생성 이미지를 포함합니다.
사례 연구 2: 텍스트 요약 (Case Study 2: Text Summarization)
영어: Describe how self-attention can be used to identify the most important sentences in a document for summarization. Include an AI-generated image of a document with key sentences highlighted based on attention scores. (200-300 words)
한국어: 셀프 어텐션을 사용하여 요약을 위해 문서에서 가장 중요한 문장을 식별하는 방법을 설명합니다. 어텐션 점수를 기반으로 핵심 문장이 강조된 문서의 AI 생성 이미지를 포함합니다.
4부: 상호작용 학습 및 응용 (Part 4: Interactive Learning and Application)
이해력 퀴즈 (Comprehension Quiz):
영어: 10-15 multiple-choice and short-answer questions covering:
The definition of sequence transduction.
The differences between recurrent, convolutional, and attention-based models.
The components of the Transformer architecture.
The advantages of self-attention.
The meaning of key vocabulary words (e.g., "parallelization," "BLEU score," "constituency parsing").
The role of positional encoding.
The results achieved by the Transformer on machine translation tasks.
한국어: 다음을 다루는 10-15개의 객관식 및 단답형 질문:
시퀀스 변환의 정의.
순환, 합성곱, 어텐션 기반 모델 간의 차이점.
Transformer 아키텍처의 구성 요소.
셀프 어텐션의 장점.
주요 어휘("병렬화," "BLEU 점수," "구문 분석" 등)의 의미.
위치 인코딩의 역할.
Transformer가 기계 번역 작업에서 달성한 결과.
프롬프트 엔지니어링 챌린지 (Prompt Engineering Challenge):
프롬프트 1 (Prompt 1):
영어: "Explain the concept of self-attention in the Transformer model as if you were teaching it to a high school student, using simple language and analogies."
한국어: "Transformer 모델의 셀프 어텐션 개념을 고등학생에게 가르친다고 가정하고, 쉬운 언어와 비유를 사용하여 설명해 보세요."
프롬프트 2 (Prompt 2):
영어: "Generate a Python code snippet that demonstrates how to calculate scaled dot-product attention for a given set of queries, keys, and values using a deep learning library like TensorFlow or PyTorch."
한국어: "TensorFlow 또는 PyTorch와 같은 딥 러닝 라이브러리를 사용하여 주어진 쿼리, 키, 값 세트에 대해 스케일드 닷-프로덕트 어텐션을 계산하는 방법을 보여주는 Python 코드 조각을 생성해 보세요."
프롬프트 3 (Prompt 3):
영어: "Compare and contrast the Transformer model with traditional recurrent neural networks, highlighting the strengths and weaknesses of each architecture."
한국어: "Transformer 모델과 기존 순환 신경망을 비교 대조하고, 각 아키텍처의 강점과 약점을 강조해 보세요."
프롬프트 4 (Prompt 4):
영어: "Describe how the Transformer model could be applied to a real-world problem other than machine translation, such as text classification or question answering."
한국어: "Transformer 모델이 기계 번역 이외의 실제 문제(예: 텍스트 분류 또는 질문 답변)에 어떻게 적용될 수 있는지 설명해 보세요."
프롬프트 5 (Prompt 5):
영어: "Generate a dialogue between two researchers discussing the implications of the Transformer model for the future of artificial intelligence."
한국어: "Transformer 모델이 인공 지능의 미래에 미치는 영향에 대해 논의하는 두 연구원 간의 대화를 생성해 보세요."
창의적 응용 프로젝트 (Creative Application Project):
프로젝트 (Project):
영어: "Design a presentation that explains the Transformer model to a non-technical audience, such as a group of business executives. Your presentation should include clear explanations of the key concepts, visual aids, and real-world examples of how the Transformer is being used in various applications. You should also address potential ethical considerations related to the use of AI models like the Transformer."
한국어: "비즈니스 임원과 같은 비전문가 청중에게 Transformer 모델을 설명하는 프레젠테이션을 설계하세요. 프레젠테이션에는 주요 개념에 대한 명확한 설명, 시각 자료, Transformer가 다양한 애플리케이션에서 어떻게 사용되고 있는지에 대한 실제 사례가 포함되어야 합니다. 또한 Transformer와 같은 AI 모델 사용과 관련된 잠재적인 윤리적 고려 사항도 다루어야 합니다."
평가 기준 (Rubric):
영어: Evaluation will be based on clarity of explanation, accuracy of information, visual appeal, relevance to the audience, and consideration of ethical implications.
한국어: 설명의 명확성, 정보의 정확성, 시각적 매력, 청중과의 관련성, 윤리적 영향 고려를 기반으로 평가합니다.
3단계: 맞춤형 GPT 개발 지침 (Stage 3: Custom GPT Development Guidance)
GPT 전문화 (GPT Specialization): "Transformer 설명 및 튜터" ("Transformer Explainer and Tutor")
지식 베이스 (Knowledge Base): 분석된 연구 논문 "Attention Is All You Need", Ashish Vaswani의 약력 정보, 신경망, 어텐션 메커니즘, 기계 번역에 대한 추가 자료.
상호 작용 스타일 (Interaction Style): 공식적이고, 유익하며, 격려하고, 인내심 있는 스타일. GPT는 복잡한 개념을 명확히 하기 위해 정의, 예, 비유를 제공할 수 있어야 합니다. 또한 사용자가 더 깊이 이해할 수 있도록 소크라테스식 질문을 할 수 있어야 합니다.
프롬프트 엔지니어링 지원 (Prompt Engineering Support): GPT는 템플릿 제공, 키워드 제안, 프롬프트 명확성에 대한 피드백 제공 등을 통해 사용자가 효과적인 프롬프트를 작성하도록 지원해야 합니다. 예를 들어, 더 간단한 설명을 끌어내기 위해 "5살 아이에게 설명하듯" 또는 "실제 비유를 들어 설명해 보세요"와 같은 문구를 사용하도록 제안할 수 있습니다. 또한 프롬프트가 너무 광범위하거나 좁은지 여부에 대한 피드백을 제공할 수 있습니다.
4단계: 시각적 및 상호작용 강화 (Stage 4: Visual and Interactive Enhancement)
AI 생성 이미지 (AI-Generated Images):
가이드라인 (Guidelines): 이미지는 명확하고, 유익하며, 논의 중인 개념과 관련이 있어야 합니다. 시각적으로 매력적이고 이해하기 쉬워야 합니다.
통합 (Integration): Transformer 아키텍처, 셀프 어텐션 메커니즘, 멀티 헤드 어텐션, 실제 적용 사례와 같은 주요 개념을 설명하기 위해 모듈 전체에 이미지가 전략적으로 배치됩니다.
캡션 (Captions): 각 이미지에는 내용과 텍스트와의 관련성을 설명하는 설명 캡션(50-100 단어)이 있습니다.
상호작용 요소 (Interactive Elements):
퀴즈 (Quizzes): 학습을 강화하고 이해도를 평가하기 위해 객관식 및 단답형 질문이 사용됩니다.
GPT 상호 작용 지점 (GPT Interaction Points): 명확한 설명, 추가 예 또는 창의적인 탐구를 위해 사용자가 맞춤형 GPT와 상호 작용하도록 장려하는 프롬프트가 모듈 전체에 삽입됩니다. 예를 들어, 멀티 헤드 어텐션 섹션 뒤에 "GPT에게 멀티 헤드 어텐션이 여러 전문가가 문제의 다양한 측면을 분석하는 것과 어떻게 유사한지 설명하도록 요청하세요"와 같은 프롬프트가 있을 수 있습니다.
(저자)
Ashish Vaswani

Ashish Vaswani, lead author of 'Attention Is All You Need' and a key figure in the development of the Transformer model at Google Brain.
Attention Is All You Need'의 주 저자이자 Google Brain에서 Transformer 모델 개발의 핵심 인물인 Ashish Vaswani.