
파인 튜인을 해보자.

파인 튜닝을 해보자.
제미나이
제미나이에서 파인 튜일 하려면 input과 output데이터를 다 낳어주야 됬는데 최근에 모델도 1.5 flash도 추가 되고 메뉴도 바뀌었었으니 한번 알아보자.
구글 ai studio 사이트에 접속하자.
Untitled prompt | Google AI Studio
왼쪽 튜닝 모델 메뉴가 있다.
new tuned model 로 들어가면 된다.
Tune a model | Google AI Studio
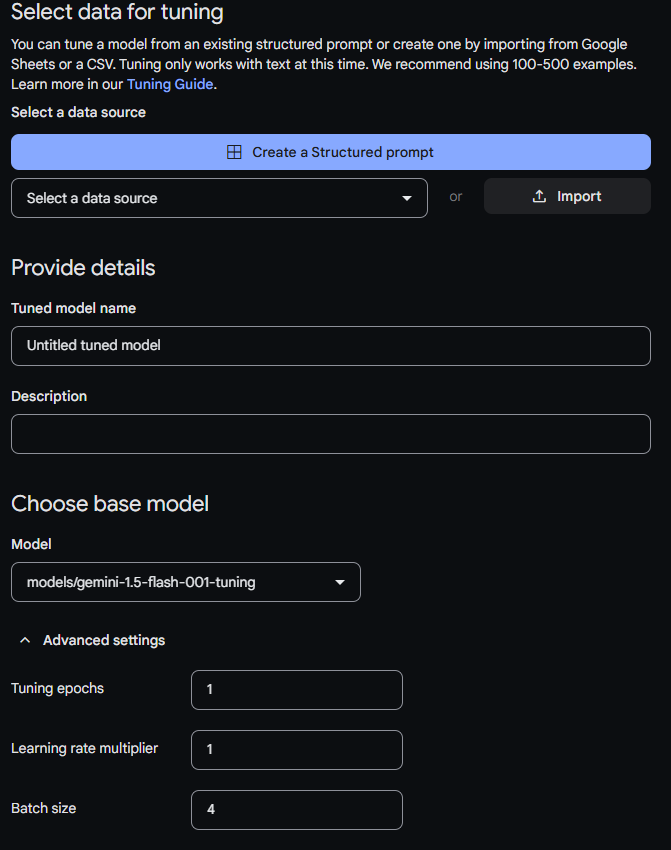
이렇게 나온다.
예전에는 제미나이 1.0 pro만 가능했는데 (성능이 정말 ...) 이제 1.5 flash가 추가 되어서 1.5 pro 만큼은 아니지만 많이 좋아졌다.
예전에는 저 create a structured prompt 로 들어가서 데이터를 일일히 넣어줘야 했다. (어느세월에..)
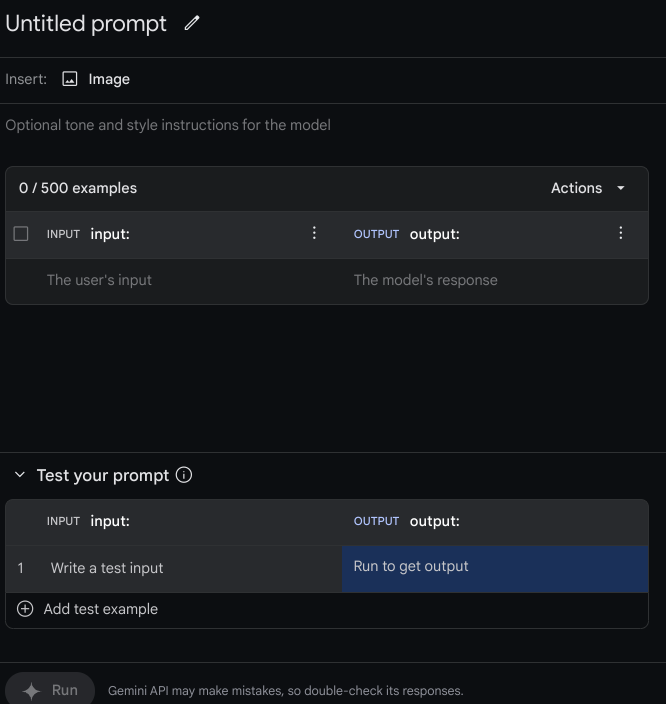
총 500개까지 넣을수 있고 넣은 데이터를 불러오거나 뺄수도 있다.
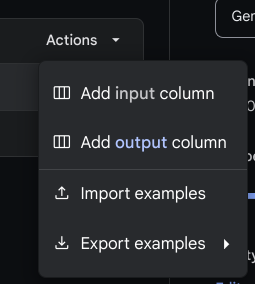
데이터 입력
여기에서 데이터를 넣어줘야된다. 만약 데이터가 없다면 기존에 들어 있는 데이터를 써볼 수도 있다.
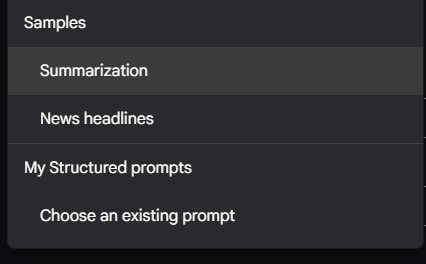
샘플 데이터로는 요약과 신문기사가 있다. 총 50개가 있다. 오른쪽에 import를 누르면 구글 독스에 연결되서 이미 만들어둔 시트를 연결할수 있다.
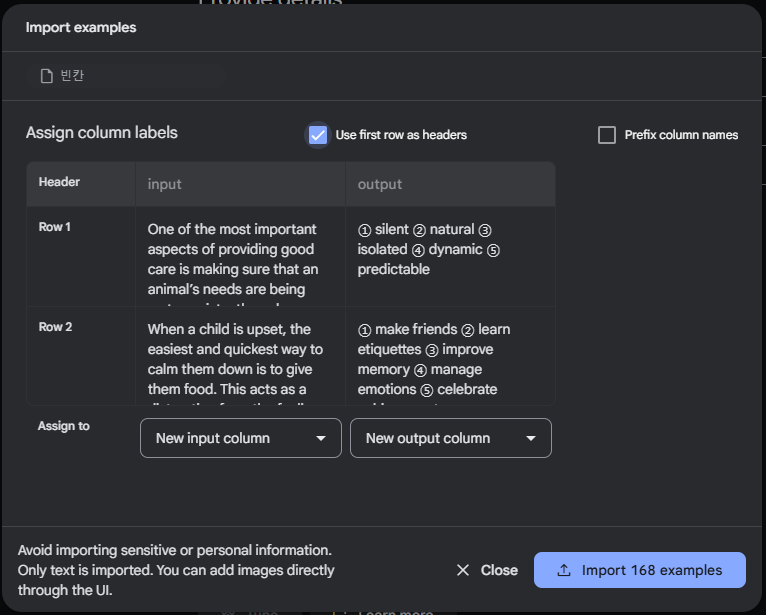 미리 셀에 input, output을 header를 미리 만들어 주고 해도 되고 그냥 없이 해도 된다. 했다면 각 셀을 input column과 output column으로 assign 해주고 import 해보자.
미리 셀에 input, output을 header를 미리 만들어 주고 해도 되고 그냥 없이 해도 된다. 했다면 각 셀을 input column과 output column으로 assign 해주고 import 해보자.
주의할것은 데이터가 20개 이하면 진행이 안된다. 최소한 20개는 준비해야된다.
학습 데이터 크기
최소 20개의 예로 모델을 세부 조정할 수 있습니다. 추가 데이터 일반적으로 응답의 품질이 향상됩니다. 100개 사이를 타겟팅해야 합니다 애플리케이션에 따라 500개의 예시가 제공됩니다 다음 표에서는 다양한 일반적인 작업에 대한 텍스트 모델을 미세 조정하는 데 권장되는 데이터 세트 크기:
작업 데이터 세트에 있는 예의 개수 분류 100+ 요약 100-500+ 문서 검색 100+
고급 설정은 다음과 같다.
고급 조정 설정
조정 작업을 만들 때 다음과 같은 고급 설정을 지정할 수 있습니다.
에포크: 전체 학습 세트에 대한 전체 학습 단계가 예시가 한 번 처리되었습니다.
배치 크기: 하나의 학습 반복에 사용되는 예시 집합입니다. 이 배치 크기는 배치의 예 수를 결정합니다.
학습률: 학습률이 모델을 반복할 때마다 강력하게 조정해야 합니다 예를 들어 학습률이 0.3이면 가중치와 편향이 3배 더 많이 조정됩니다. 0.1보다 강력합니다. 높은 학습률과 낮은 학습률은 사용 사례에 따라 조정해야 합니다
학습률 배율: 학습률 배율로 모델의 원본 학습률과 일치합니다. 값이 1이면 있습니다. 1보다 큰 값은 학습률과 1 사이의 값을 증가시킵니다. 0은 학습률을 낮춥니다
추천 구성
다음 표에서는 기반 모델:
초매개변수 기본값 추천 조정 세대 5 5세대 이전에 손실이 고원하기 시작하면 더 작은 값을 사용합니다.손실이 수렴하고 고원처럼 보이지 않으면 더 높은 값을 사용합니다. 배치 크기 4 학습률 0.001 데이터 세트가 작을 경우 더 작은 값을 사용하세요. 손실 곡선은 모델의 예측이 이상적인 예측에서 얼마나 벗어나는지 보여줍니다. 예측을 수행하는 방법을 보여줍니다. 이상적으로는 곡선의 최저점에서 학습을 진행함을 의미합니다. 예를 들어 아래 그래프는 에포크 4~6에서의 손실 곡선 정체를 보여줍니다.
Epoch매개변수를 4로 설정해도 동일한 성능을 얻을 수 있습니다.
튜닝결과
오랜 시간 기다리면 오른쪽 모델에 파인 튜인해둔 모델이 추가 된다.
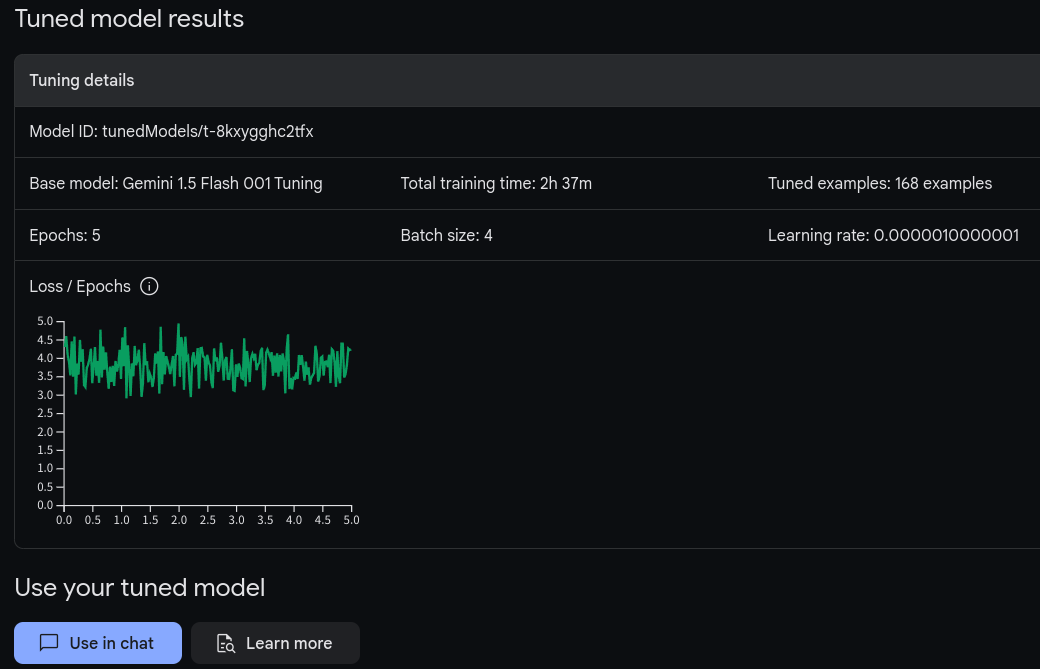
들어 가보면 tuning 상황을 알수 있다.
epoch 5, batch size 4, learng rate:0.001 로 했고, 2시간 37분후에 훈련이 끝났다. 그래프를 보니 epoch를 더 늘려야 할듯
다되면 왼쪽 모델에 튜닝된 모델이 추가 된다. 테스트를 해보고 사용해 볼수도 있다.
기타 방법
미세 조정 튜토리얼 | Gemini API | Google AI for Developers
여기에 가면 파이썬 코드로 코랩등에서 직접 돌려 볼수 있다. 직접 조절이 더 가능 하다는건 장점 이지만, 중간에 데이터를 직접 넣어 주는건 조금 귀찮은 일이 될수도 있다.
import time
base_model = "models/gemini-1.5-flash-001-tuning"
training_data = [
{"text_input": "1", "output": "2"},
# ... more examples ...
# ...
{"text_input": "seven", "output": "eight"},
]이렇게 1에는 input을 2에는 output을 넣어 주면 된다.
chatgpt
chat gpt의 fine tuning은 다음 페이지에서 조절할수 있다.
https://platform.openai.com/docs/guides/fine-tuning
데이터 준비
In this example, our goal is to create a chatbot that occasionally gives sarcastic responses, these are three training examples (conversations) we could create for a dataset:
1{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already."}]} 2{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?"}]} 3{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters."}]}The conversational chat format is required to fine-tune
gpt-4o-miniandgpt-3.5-turbo. Forbabbage-002anddavinci-002, you can follow the prompt completion pair format as shown below.1{"prompt": "<prompt text>", "completion": "<ideal generated text>"} 2{"prompt": "<prompt text>", "completion": "<ideal generated text>"} 3{"prompt": "<prompt text>", "completion": "<ideal generated text>"}Multi-turn chat examples
Examples in the chat format can have multiple messages with the assistant role. The default behavior during fine-tuning is to train on all assistant messages within a single example. To skip fine-tuning on specific assistant messages, a
weightkey can be added disable fine-tuning on that message, allowing you to control which assistant messages are learned. The allowed values forweightare currently 0 or 1. Some examples usingweightfor the chat format are below.1{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]} 2{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]} 3{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
이렇게 데이터를 준비하라고 되어있다. 데이터를 보면 알겠지만 json 포맷인데 실제 넣는건 jsonl로 확장자를 변환해 줘야 한다. 실제로 이런 데이터를 일일이 하는건 어렵고, 엑셀로 준비했다가. gpt를 시켜셔 변환하는데 더 빠른 방법을 보인다.
사이트 접속
데이터를 준비해쓰면 사이트에 접속하자.
https://platform.openai.com/finetune
create 를 눌러서 작업을 추가 해보자.
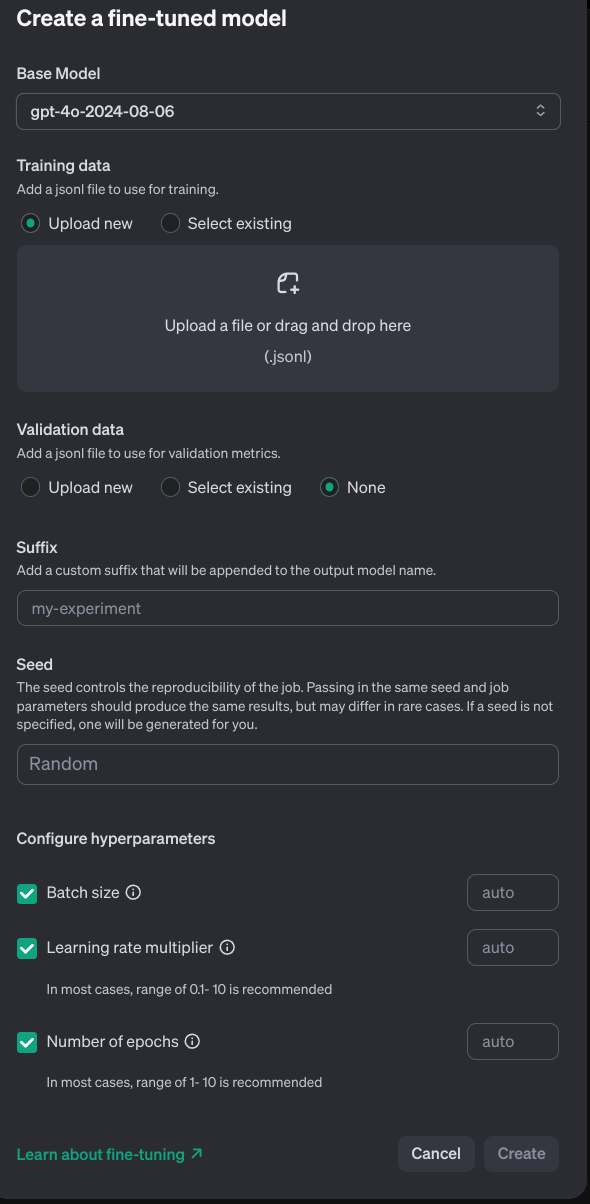
모델을 gpt 4o로 하고 데이터를 넣어주고 설정을 해주면 된다. 한달동안 gpt 4.o 의 파인 튜닝 비용은 무료라고 하지만 무료 계정으로는 되지 않는다. 그래서 gpt는 하지 않았다.
결론
이렇게 파인 튜닝을 찍먹해봤다.
다른 사람들의 말이 다 맞았다.
데이터 전처리며 데이터 수집및 가공에 정말 시간이 많이 걸린다. 있는 문서 데이터를 가공하면 좀 빠르게 되겠지만, 이제부터 데이터를 수집한다면 정말 시간이 많이 걸린다.
데이터 만큼 훈련 파라미터등 조절해 볼게 있다. 다만 훈련에 시간이 많이 걸리기때문에 그 만큼의 미세 조정은 그만큼의 시간이 든다. (제미나이 제외하고는 돈도 들것이다. 직접 하면 전기 요금 정도?)
100여개의 데이터로는 차이를 알기 쉽지 않다. 더 많아지만 가능할지도 모르겠지만, 내가 있는 도메인에서 데이터를 그렇게 모을수 있을지 모르겠다.
차라리, 프롬프트를 잘 짜고, 편집을 더 잘하자. 끄읕