
GGUF에 대해 알아보기

GGUF 포맷은 Georgi Gerganov(@ggerganov)라는 개발자가 만든 딥러닝 모델 저장용 단일 파일 포맷입니다. 이 포맷은 주로 LLM(Large Language Model) 추론에 활용되며, 다음과 같은 특징을 가지고 있습니다:
GGUF 뜻
Georgi Gerganov Machine Learning Unified Format
GGUF 특징
단일 파일 구조: 모델을 하나의 파일로 쉽게 공유할 수 있습니다. 이는 모델의 배포와 사용을 간편하게 만듭니다.
메타데이터와 텐서 데이터: 파일 내에 모델의 가중치(weight) 텐서 값들과 메타데이터가 Key-Value 형식으로 저장됩니다. 메타데이터는 모델의 구조, 버전, 텐서 개수 등을 포함합니다.
다양한 양자화 지원: GGUF는 16-bit 부동 소수점(floating point)뿐만 아니라 8-bit, 6-bit, 5-bit, 4-bit, 3-bit, 그리고 2-bit까지의 다양한 양자화된 텐서 타입을 지원합니다. 이는 모델을 더 작게 만들어 추론 속도를 높이고, 메모리 사용을 줄이는 데 유용합니다.
양자화란?
모델의 가중치를 더 낮은 비트 정밀도로 변환하는 기술입니다. 예를 들어, 16-bit에서 4-bit로의 변환은 각 가중치의 표현에 필요한 비트 수를 줄여, 모델의 크기를 작게 만들고, 메모리 사용량을 줄이며, 경우에 따라서는 추론 속도를 높일 수 있습니다.
호환성: GGML 라이브러리 기반의 런타임에서 주로 사용되며, CPU에서도 실행 가능하다는 점에서 사용자의 접근성을 높입니다.
발전성: GGML 포맷을 이어받아 더 큰 유연성과 확장성을 제공하며, 다양한 모델을 지원하여 언어 모델 파일 형식의 발전에 기여하고 있습니다.
GGUF모델 종류별 특징
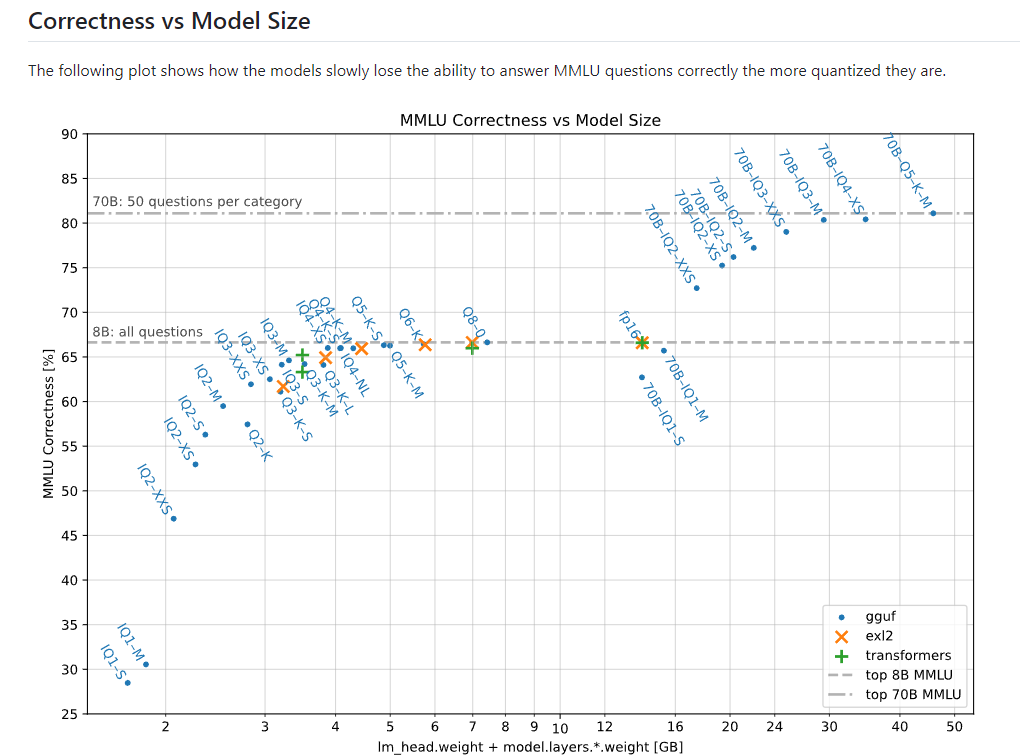
GGUF 모델 종류와 특징:
Q8_0: 8비트 양자화 모델로, 원본 모델의 품질을 거의 그대로 유지하면서 크기를 절반으로 줄입니다.
Q6_K, Q5_K_M, Q5_K_S: 6비트와 5비트 양자화 모델들로, 품질 손실은 미미하지만 크기가 더 작습니다.
Q4_K_M, Q4_K_S: 4비트 양자화 모델로, 약간의 품질 손실이 있지만 크기가 매우 작습니다.
IQ4_NL, IQ4_XS: 개선된 4비트 양자화 모델로, Q4 모델보다 품질이 조금 더 좋습니다.
IQ3_M, IQ3_S, IQ3_XS, IQ3_XXS: 3비트 양자화 모델들로, 크기가 매우 작지만 품질 손실이 더 커집니다.
IQ2_M, IQ2_S, IQ2_XS, IQ2_XXS: 2비트 양자화 모델들로, 크기가 가장 작지만 품질 손실도 가장 큽니다.
뒤에 붙은 숫자는 블록의 크기, 정밀도, 범위 등등에 따른 양자화 방법에 따라 나뉜거라 생각하시면 될 것 같습니다. 깊게는 저도 잘 모릅니다.***
그래픽 카드 성능이 제한적인 상황에서의 모델 선택:
VRAM이 8GB 이상인 경우:
8B 모델의 Q5_K_M 또는 Q4_K_M을 추천합니다.
이 모델들은 품질 손실이 적으면서도 크기가 작아 중간 사양의 GPU에서도 잘 작동합니다.
VRAM이 4-6GB인 경우:
8B 모델의 IQ4_XS 또는 IQ3_M을 고려해보세요.
이 모델들은 크기가 더 작아 제한된 VRAM에서도 작동하며, 여전히 괜찮은 성능을 보여줍니다.
VRAM이 4GB 미만인 경우:
8B 모델의 IQ2_M 또는 IQ2_S를 사용해볼 수 있습니다.
품질 손실이 더 크지만, 매우 제한된 하드웨어에서도 작동할 수 있습니다.
CPU만 사용 가능한 경우:
8B 모델의 IQ2_XS 또는 IQ2_XXS를 고려해보세요.
성능은 크게 떨어지지만, GPU 없이도 모델을 실행할 수 있습니다.
주의사항:
더 작은 모델일수록 추론 속도는 빨라지지만, 출력 품질은 떨어질 수 있습니다.
가능하다면 테스트를 통해 사용 목적에 맞는 최적의 모델을 찾는 것이 좋습니다.
VRAM 사용량은 컨텍스트 길이에 따라 달라지므로, 긴 컨텍스트가 필요하지 않다면 더 작은 모델을 선택할 수 있습니다.

참고 자료
llama-3-quant-comparison/README.md at main · matt-c1/llama-3-quant-comparison
https://i.redd.it/t55tv97usrid1.jpeg
{kind=link}
What LLM quantization works best for you? Q4_K_S or Q4_K_M
k-quants by ikawrakow · Pull Request #1684 · ggerganov/llama.cpp
What LLM quantization works best for you? Q4_K_S or Q4_K_M
이미지 생성을 위한 GGUF 파일 받는 곳
[city96 github 데이터]
GitHub - city96/ComfyUI-GGUF: GGUF Quantization support for native ComfyUI models
[schnell,Dev 모델]
city96/FLUX.1-schnell-gguf at main
city96/FLUX.1-dev-gguf · Hugging Face
[Clip model]