
[UCA수퍼컴퓨팅학원] AI가속기 칩 하드웨어 트렌드에 대해서 --(1)
메타의 라마 1 모델은 학습 가중치가 노출된 후, 해커들이 CPP버전, 라즈베리 파이같은 소형 디바이스에도 동작하도록 개조하거나, 공개된 데이터셋들을 사용해 라마 모델 구성을 그대로 재현해보는 레드파자마같은 프로젝트가 연이어 나왔다.
라마의 아류인 알파카나 비쿠나등 정신 못차리게 응용 모델들이 쏟아져나온 헤커들의 아키텍처이기도하다.

소스코드 잘 만드는 <코드라마 34B>등의 특화된 모델들이 다수 존재한다. 맥북에 설치해서 ollama로 자신의 코드 도우미로서 소프트웨어 개발 작업에 사용하는 개발자가 있다.
허깅페이스에선 <Seamless-M4T>라는 약 100개국 언어의 번역과 원어민 수준의 음성 출력이 가능한 페이스북의 고유 모델도 출시했다.
마이크로소프트는 현재 openAI와 끈끈한 밀월 관계지만, 내부적으로는 라마 아키텍처를 사용한 Phi 시리즈, WizardLM등을 개발해 일주일 간격으로 계속 발표하기도 했다.
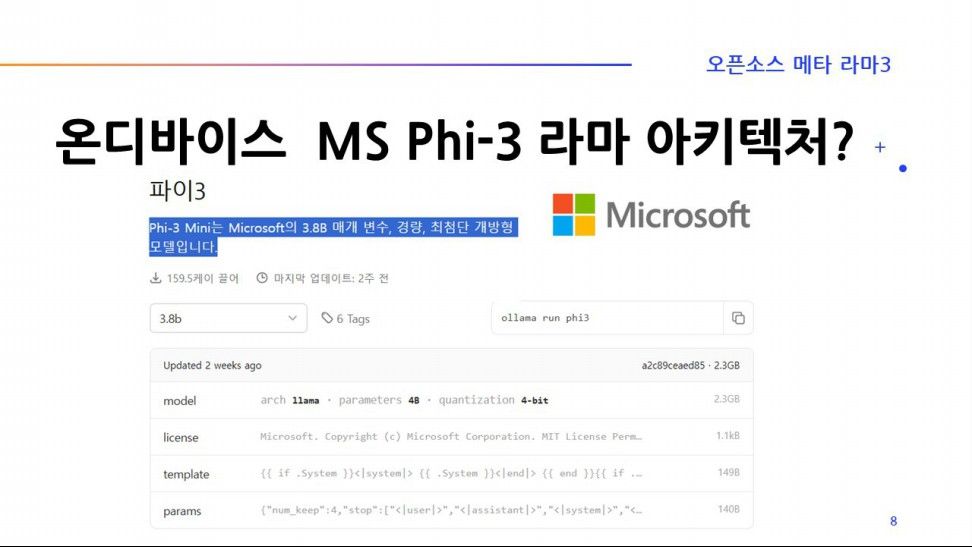
마이크로소프트 Phi-3등 4비트 양자화가 된 모델들은 파일 사이즈가 1.4G~ 4.7G등 휴대폰, 배달 로봇 두뇌 메모리등에 설치를 할수 있을정도로 용량이 매우 작고, LMStudio, Ollama등을 이용하면 양자화 모델들을 쉽게 구해서 대화를 하거나, OpenAI 스타일로 파이썬 코드 테스트도 가능하다.
온디바이스 모델들은 내 노트북 PC에 오픈소스 기반 AI 파운데이션 모델들을 다운로드받아 설치해서 코드를 짜거나 대화형으로 사용해 볼수 있다는게 가장 큰 장점이다. 이런 점 때문에 대형 AI 파운데이션 모델을 보유한 구글도 오픈소스로 풀렷지만, 작은 사이즈를 가진 gemma, 마이크로소프트 phi-3 모델등이 계속 만들어지는 거라 생각한다.
양자화란 파라미터 사이즈로 덩치가 큰 32톤 트럭들이 움직이기 힘드니 도로를 잽싸게 다닐수있는 경차형태로 모델사이즈를 변환시키는 거라고 생각하면 쉽다.

HBM (High Banbdwidth Memory)는 기존 GPU 옆에 붙어있는 VRAM들이 너무 데이터를 주고받는 속도가 느려서 마치 30층 고층빌딩에서 가운데 뻥 뚫린 터널이 있는데, 통로를 다니는 방식이 자유 낙하같은 속도로 다니는게 아니라 나선형 계단으로 사람이 뛰어내려가는 듯한 속도감처럼 느리다는 점이다.
속도문제를 해결하려고 적층 12단 메모리 사이에 초고속 궤도 엘리베이터를 설치해 번개같은 속도로 데이터를 송수신하는 형태로 만들어지고 있다.

현재 GPU 하드웨어에 붙어있는 DRAM의 데이터 I/O 통로가 64개라면, SK하이닉스의 HBM3E(5세대)는 X 16배인 1024개이다. 내 후년 양산예정인 HBM4 칩에서는 2048개로 (x2) 더 늘어날 예정이다.
현재 HBM3E(5세대)는 전송 속도는 30기가짜리 영화 약 40개를 1초 안에 동시에 전송한다.
아래 사진을 보면 가운데 2개의 GPU가 배치되어있고, GPU를 기준으로 하여 양옆에 적층 구조의 메모리가 보인다. 마이크론도 GPU 옆 HBM3E 메모리를 적층 8단까지 쌓아서 nVidia 블랙웰 H200장비에 납품을 했다. SK하이닉스가 유일하게 12단으로 쌓아올려서 제품을 구성한 개발사다.
수율은 약 80%가 나온다고 한다.

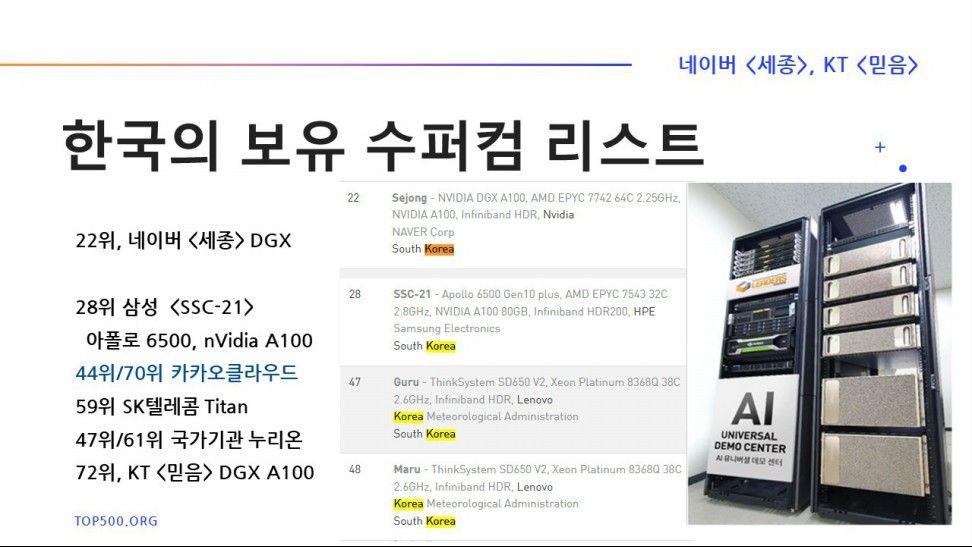
Top500.org에서 한국이 보유한 수퍼컴퓨터들을 리스트업 해 봤다. 22위 네이버의 세종, 28위 삼성 타이탄, 59위 SKT의 타이탄, 72위 KT 믿음까지 거의 nVidia 회사의 DGX 서버임을 알 수 있다.
누리온의 마루, 구루는 학술 연구용이다. 주피터노트북을 포트포워딩 방식으로 붙여서 연결하여 코딩하고, 연산및 데이터 처리는 원격 수퍼컴이 하고, 결과를 주피터노트북으로 받아보는식이다.
작년에 목록에 없던 카카오의 서버가 각각 44위, 70위로 첫 등장했다.
KT클라우드는 nVidia V100등 2017년도경에 생산된 구형 GPU를 아직 서비스에서 운영하고 있다. CUDA가 12.1정도 버전이어야하는데, KT클라우드는 V100등 구형 GPU가 있어서 아직 CUDA 8.0버전으로 돌리고있다. AMD기반 GPU도 약 2천여 개 이상 보유하고있다.
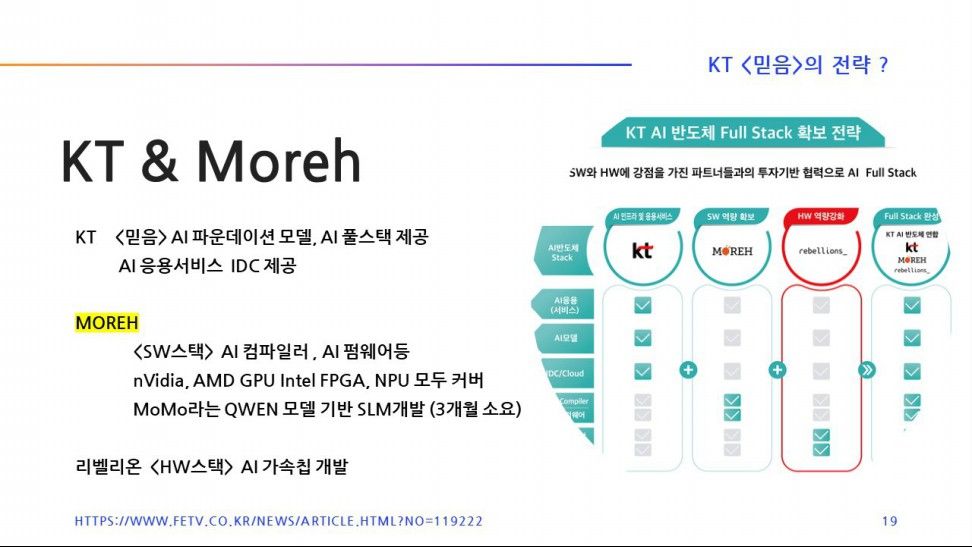
KT는 서비스를 제공하기 위해 보유하고있는 AI 가속기가 nVidia 제품인지 아니면 Intel FPGA인지 전혀 신경쓰지않아도 된다. Moreh의 소프트웨어가 다 커버를 해준다.
KT는 2023년 리벨리온으로부터 <아톰>이라는 NPU를 공급받아 여러 가지 실증 사업을 거쳤다. KT는 여러 개의 NPU나 GPU칩들이 혼합되어 서비스하는 환경이다.
Moreh는 알리바바의 QWEN 모델을 가져다가 달랑 AI 엔지니어 2명만 3달정도 집중 투입해 MoMo 라는 이름의 파운데이션 모델을 개발했다. 잠깐동안이지만, 오픈소스 리더보드에서 1등도 차지했다.
CUDA와 겨루기위한 AMD의 ROCm 호환 소프트웨어도 있지만, 성능은 CUDA에 미치지못하고, 후속작으로 여겨진 ZLUDA는 AMD 자금 후원이 끊기고 개발이 중단되었다가 조용히 오픈소스로 변경 공개되긴했다.
AMD는 AI 개발자들이 AMD 라데온 GPU를 설치하고, ROCm 스택 위에서 소스 코드 변경 없이 CUDA 응용애플리케이션들이 실행될 수 있도록 하기위해 ZLUDA 개발자금을 지원해온건데, 중단된 상태고, Moreh에는 따로 약 200억원의 투자금을 타진하고있다고한다.
Moreh측의 드라이버나 AI 컴파일러등의 응용소프트웨어가 더 승산이 있다는 판단을 한걸까?
AMD는 NVIDIA를 자신의 라이벌로 생각하지만, 10여년의 개발기간을 거친 CUDA의 아성은 너무 단단했다. 일종의 그래픽 카드 전용 저수준 기계어와같은 CUDA API를 대상으로 하는 코드베이스를 AMD ROCm에서 실행만 되면 nVidia를 제낄수 있으니 말이다.
ZLUDA 개발자 Andrzej Janik은 AMD 라데온 계열의 GPU에서 실제로 리버스 엔지니어링을 통해 ZLUDA를 구현해냈다고 한다. ZLUDA 응용소프트웨어가 현재 100% 완벽한 상태가 아니지만, 그래도 CUDA가 코드 수정 없이 ROCm 위에서 실행될 수 있도록 만들어냈다. 이이러니컬하게도 일단 다된 밥이긴한데 AMD는 따로 밥상 차리기를 포기했단거다. AMD는 100% 완벽하지않은 ZLUDA를 정식 드라이버로 출시하지 않기로 결정했다.

UCA수퍼컴퓨팅학원
교육청허가 6643호
교습비 주3시간/4회 월 38만원 / 성인/대학생 45만원
교습과목 파이썬/게임개발/정보보안/ AI코딩