[쉽게 설명해 보기_ 선형회귀분석] seaborn library을 활용한 선형회귀분석 실습

구글 콜랩에서 선형회귀분석을 실습할 수 있는 교안입니다.
1. seaborn 라이브러리 추가
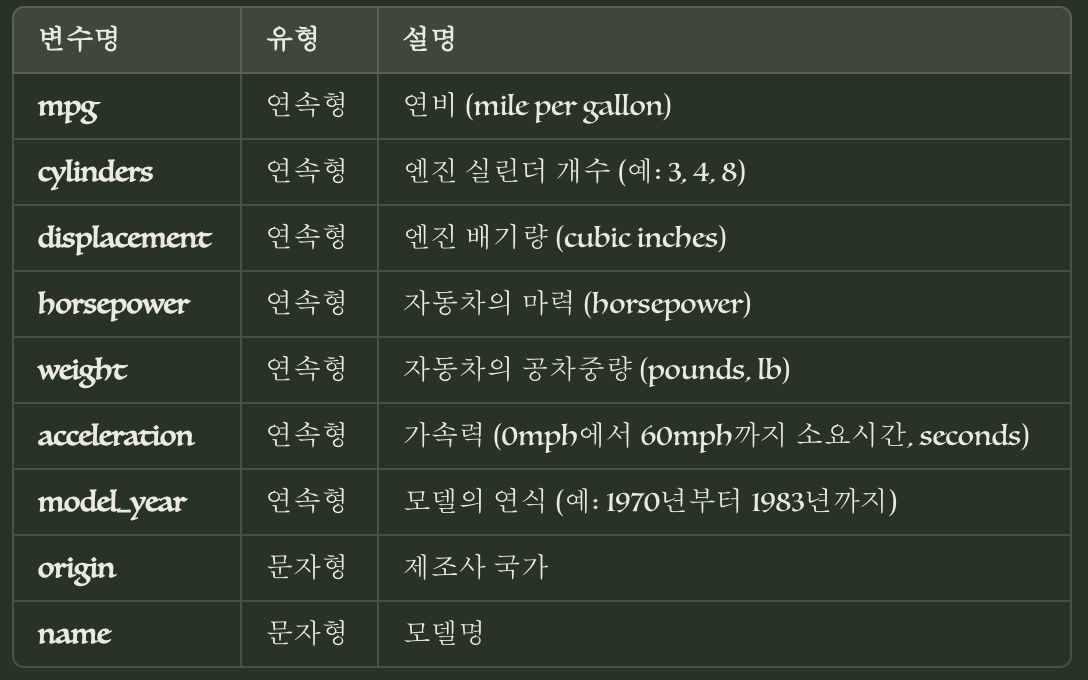
이 실습에서는 Seaborn 라이브러리의 'mpg' 데이터셋을 사용하여 선형 회귀분석을 수행해 보겠습니다.
선형 회귀분석은 독립변수와 종속변수 간의 선형 관계를 모델링하는 데 사용되는 통계적 기법입니다.
이 실습을 통해 데이터 로드, 전처리, 모델 학습, 평가 등의 과정을 경험해 볼 수 있습니다.
import seaborn as sbSeaborn은 데이터 시각화와 통계 분석을 위한 강력한 파이썬 라이브러리입니다. 'sb'라는 별칭으로 import하여 코드 작성 시 'sb'를 사용할 수 있습니다.
2. mpg 데이터 로드
Seaborn에 내장된 'mpg' 데이터셋을 로드하겠습니다.
이 데이터셋은 자동차의 연비(mpg)와 관련된 정보를 담고 있습니다.
#데이터 로드
mpgData = sb.load_dataset('mpg')
#데이터 확인하기
mpgData![[쉽게 설명해 보기_ 선형회귀분석] seaborn library을 활용한 선형회귀분석 실습 image 2](https://server.tilnote.io/images/pages/93dc3ad3-bde3-44c9-aa97-b67b984b9265.png)
sb.load_dataset('mpg')를 사용하여 'mpg' 데이터셋을 로드하고,mpgData라는 변수에 할당합니다. 그리고mpgData를 실행하여 데이터셋의 내용을 확인합니다.
3. dropna () 함수로 결측치 (na : not available) 제거
데이터셋에 존재하는 결측치(missing values)를 제거하기 위해 dropna() 함수를 사용합니다. 결측치는 데이터 분석 시 문제를 일으킬 수 있으므로 제거해 주는 것이 좋습니다.
#데이터 차원 확인
print(mpgData.shape)
#결측치 제거
mpgData = mpgData.dropna()
#결측치 제거 후 데이터 차원 확인
print(mpgData.shape)먼저 mpgData.shape을 출력하여 데이터셋의 차원(행과 열의 개수)을 확인합니다.
그리고 mpgData.dropna()를 사용하여 결측치가 포함된 행을 제거합니다.
결측치 제거 후에는 다시 mpgData.shape을 출력하여 데이터셋의 차원 변화를 확인합니다.
![[쉽게 설명해 보기_ 선형회귀분석] seaborn library을 활용한 선형회귀분석 실습 image 3](https://server.tilnote.io/images/pages/77c901d8-c95e-4bc6-9ea7-dc522493d558.png)
DataFrame 자료 구조의 ‘shape’ 속성으로 크기 확인합니다.
결측치 제거 후 레코드 수가 398 개 에서 392 개로 줄어들었습니다.
4. 독립변수 정의
선형 회귀분석에서 사용할 독립변수를 정의합니다.
여기서는 'cylinders', 'displacement', 'horsepower', 'weight', 'acceleration', 'model_year' 열을 독립변수로 선택하겠습니다.
#독립변수 정의
indVarNames = ['cylinders', 'displacement','horsepower','weight','acceleration','model_year']
x_total = mpgData[indVarNames]
x_total![[쉽게 설명해 보기_ 선형회귀분석] seaborn library을 활용한 선형회귀분석 실습 image 4](https://server.tilnote.io/images/pages/0668dba0-4ebc-4644-8bf1-2376d9b4cc7a.png)
indVarNames 리스트에 독립변수로 사용할 열의 이름을 지정합니다.
그리고 mpgData[indVarNames]를 사용하여 해당 열만 선택하고,
x_total 변수에 할당합니다.
x_total을 실행하여 선택된 독립변수 데이터를 확인합니다.
5. 종속변수 정의
선형 회귀분석에서 예측하고자 하는 종속변수를 정의합니다.
여기서는 'mpg' 열을 종속변수로 선택하겠습니다.
#종속변수 정의
depVarName = 'mpg'
y_total = mpgData[depVarName]
y_total![[쉽게 설명해 보기_ 선형회귀분석] seaborn library을 활용한 선형회귀분석 실습 image 5](https://server.tilnote.io/images/pages/3d465a90-3868-46f6-b7d2-e191de41c65c.png)
depVarName 변수에 종속변수로 사용할 열의 이름('mpg')을 할당합니다.
그리고 mpgData[depVarName]을 사용하여 해당 열만 선택하고, `
y_total` 변수에 할당합니다.
y_total을 실행하여 선택된 종속변수 데이터를 확인합니다.
6. 훈련(학습)데이터와 테스트 데이터로 분할
모델 학습 및 평가를 위해 전체 데이터를 훈련 데이터와 테스트 데이터로 분할합니다.
여기서는 sklearn의 train_test_split 함수를 사용하여
전체 데이터를 7:3 비율로 나누겠습니다.
sklearn의 하위 모듈인 model_selection 의 train_test_split 함수를 추가
##데이터를 학습/훈련 집합 및 테스트 집합으로 분할
#데이터 분할을 위한 메소드 추가
from sklearn.model_selection import train_test_split
#DataFrame인 변수를 numpy 배열로 변환
x_total_np = x_total.to_numpy()
y_total_np = y_total.to_numpy()
#전체 데이터를 훈련 7: 테스트 3으로 분할
x_train, x_test, y_train, y_test = train_test_split(x_total_np,y_total_np, test_size=0.30, random_state=10)[test_size =0.30] 전체 데이터의 30% 를 테스트 집합으로 할당
[random_state =10] 일관된 난수 생성을 위한 설정
먼저 train_test_split 함수를 사용하기 위해 sklearn.model_selection 모듈에서 import합니다.
그리고 x_total과 y_total을 numpy 배열로 변환하여
x_total_np와 y_total_np에 할당합니다.
train_test_split 함수를 사용하여
x_total_np와 y_total_np를 훈련 데이터와 테스트 데이터로 분할합니다.
test_size=0.30은 전체 데이터의 30%를 테스트 데이터로 사용하겠다는 의미이며,
random_state=10은 데이터 분할 시 재현 가능한 결과를 얻기 위해 설정하는 값입니다.
분할된 데이터는 x_train, x_test, y_train, y_test 변수에 각각 할당됩니다.
7. 라이브러리를 추가하여 선형 모형 학습
sklearn의 LinearRegression 클래스를 사용하여 선형 회귀 모델을 생성하고 훈련 데이터로 학습시킵니다.
선형 회귀분석 수행 : scikit learn (sklearn)
선형 모듈 : sklearn 의 linear_model
선형 모형 생성 : linear_model.LinearRegression
[reg.fit x_train , y_train )]: 훈련 데이터로 모형 학습
#선형 회귀분석 모델 추가
from sklearn import linear_model
#선형 회귀분석 객체 생성
reg = linear_model.LinearRegression()
#생성한 선형 회귀분석 모델을 훈련 데이터로 학습시키기
reg.fit(x_train, y_train)linear_model 모듈에서 LinearRegression 클래스를 import합니다.
그리고 LinearRegression 객체를 생성하여 reg 변수에 할당합니다.
reg.fit(x_train, y_train)을 사용하여
생성한 선형 회귀 모델을 훈련 데이터(x_train, y_train)로 학습시킵니다.
이 과정에서 모델은 훈련 데이터를 바탕으로 최적의 계수를 찾습니다.
8. 학습된 모형의 상수항과 계수 확인
학습된 선형 회귀 모델의 상수항과 계수를 확인합니다.
[reg.intercept _]: 모형의 상수항 출력 [reg.coef _]: 모형의 계수 출력
#선형 회귀분석 모델의 상수항
print("상수항: %.4f" %reg.intercept_)
#선형 회귀분석 모델의 계수
print("계수: ", reg.coef_)![[쉽게 설명해 보기_ 선형회귀분석] seaborn library을 활용한 선형회귀분석 실습 image 6](https://server.tilnote.io/images/pages/51c57912-d422-4892-a2f2-65d6a60fa863.png)
reg.intercept_를 출력하여 학습된 선형 회귀 모델의 상수항을 확인합니다.
상수항은 모든 독립변수의 값이 0일 때 종속변수의 값을 나타냅니다.
reg.coef_를 출력하여 학습된 선형 회귀 모델의 계수를 확인합니다.
계수는 각 독립변수가 종속변수에 미치는 영향력을 나타냅니다.
9. 모형의 성능 평가
테스트 집합의 추정치와 실제 결과 비교 [reg.predict x_test )]:
테스트 데이터의 종속변수 추정
결정계수 sklearn 의 하위 모듈 metrics 에서 ‘r2_score' 수정된 결정계수 계산 :
관계식을 활용하여 직접 계산
#학습된 모형으로 테스트 집합의 종속변수 추정
y_predicted = reg.predict(x_test)
#결정계수(R-square) 함수 추가 및 계산
from sklearn.metrics import r2_score
print("결정계수 %.4f" %r2_score(y_test, y_predicted))
#수정된 결정계수(adjusted R-square) 계산
adj_r2_score = 1-(1-r2_score(y_test, y_predicted)) * (len(y_total)-1)/(len(y_total)-x_total.shape[1]-1)
print("수정된 결정계수 %.4f" % adj_r2_score)학습된 선형 회귀 모델의 성능을 평가하기 위해 테스트 데이터에 대한 예측을 수행하고,
결정계수(R-square)와 수정된 결정계수(Adjusted R-square)를 계산합니다.
![[쉽게 설명해 보기_ 선형회귀분석] seaborn library을 활용한 선형회귀분석 실습 image 7](https://server.tilnote.io/images/pages/66735fd8-5bb9-4f13-94ad-1e49e05e6d97.png)
reg.predict(x_test)를 사용하여 테스트 데이터(x_test)에 대한 예측을 수행하고,
예측 결과를 y_predicted 변수에 할당합니다.
r2_score 함수를 사용하여 결정계수를 계산합니다.
결정계수는 모델의 예측 성능을 평가하는 지표로, 0에서 1 사이의 값을 가지며
1에 가까울수록 모델의 설명력이 높다는 것을 의미합니다.
수정된 결정계수는 독립변수의 개수를 고려하여 결정계수를 조정한 값입니다.
수정된 결정계수는 독립변수의 개수가 많을 때 모델의 성능을 보다 정확하게 평가할 수 있습니다.
이상으로 Seaborn 라이브러리를 활용한 선형 회귀분석 실습을 완료하였습니다.
이 실습을 통해 데이터 로드, 전처리, 모델 학습, 평가 등의 과정을 경험해 보았습니다.
실습 코드와 함께 제공된 설명을 참고하여 각 단계의 의미를 이해하고 활용해 보시기 바랍니다.
<실습노트>