
[UCA수퍼컴아카데미] 라마3 llama3 70B API 코딩 --(1)

메타의 라마3 llama 7B(혹은 8B 인스트럭션)및 70B 모델이 출시되었다.
meta.ai는 아직 나라별로는 출시국이 아니라서 접속이 되지않는다.
TouchVPN 확장을 써서 미국, 영국 IP로 로 들어가려고 해도 안되는 건데, SNS 로그인 아이디인 페이스북 아이디가 한국이라서 그런지 페이스북 로그인 아이디의 나라부분을 체크하는듯하다.
라마3 70B처럼 VRAM 147G정도를 요구하는 모델은 사실 그림의 떡이다. 메모리가 더 작아도 그럭저럭 돌아는간다고 한다.
이 라마 70b모델을 다운받아 제작한 sionic AI 측도 V100 4장을 갖고 학습시켜야 돌아가는것을 보며 가성비로는 맥북 M2나 M3 탑재 노트북이 최고인거같다. 메모리만 충분하다면 모델이 돌아간다고한다. 앞으로도 비싼 nVidia 4090 GPU가 없어도 메모리 충분한 M2 맥북이라도 있으면 어떤 파운데이션 모델이든 돌려볼 수 있을거 같다.
허깅페이스 meta-ai 8B 인스트럭션 Serverless 예제도 서버리스인데도 불구하고, 메모리 로딩에러가 난다. 허깅페이스에서도 Dedicated Space를 사용하라고 권고한다.
구글 코랩 기본형이나 깃허브 코드스페이스등에서도 8B조차 다 사용 불가능하다.
돈을 들여야하나?
import requests
API_URL = "https://api-inference.huggingface.co/models/meta-llama/Meta-Llama-3-8B"
headers = {"Authorization": "Bearer hf_trnjc..."}
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
output = query({ "inputs": "Can you please let us know more details about
your ", })
print(output)
{
'error': 'The model meta-llama/Meta-Llama-3-8B is too large to be loaded automatically (16GB > 10GB).
Please use Spaces (https://huggingface.co/spaces) or Inference Endpoints (https://huggingface.co/inference-endpoints).'
}
그래서 발견한게 sionic AI의 xionic-ko-llama-3-70b인데, 주말에 일을 하느라 며칠 블로그 포스팅을 못했더니 개발자들중엔 이미 라마3로 한글 파인튜닝까지 마친 분들도 수두룩하다.
주어지는 코드를 보자.
사용가능한 API-KEY도 안에 들어있다
api_key = "934c4bbc-c384-4bea-af82-1450d7f8128d"
![[UCA수퍼컴아카데미] 라마3 llama3 70B API 코딩 --(1) image 3](https://blogfiles.pstatic.net/MjAyNDA0MjJfMjY4/MDAxNzEzNzQ2NTgyMjE3.ZSQbXyRtZOJSKhXoIQcfbBpBOV9cUGBSYTY9iEM6rCYg.RTWqOtWMgKTKexdrrd7T7dCc6_s71rBF6qA3OBJSJX0g.JPEG/llama3.jpg?type=w1)
파이썬 샘플코드
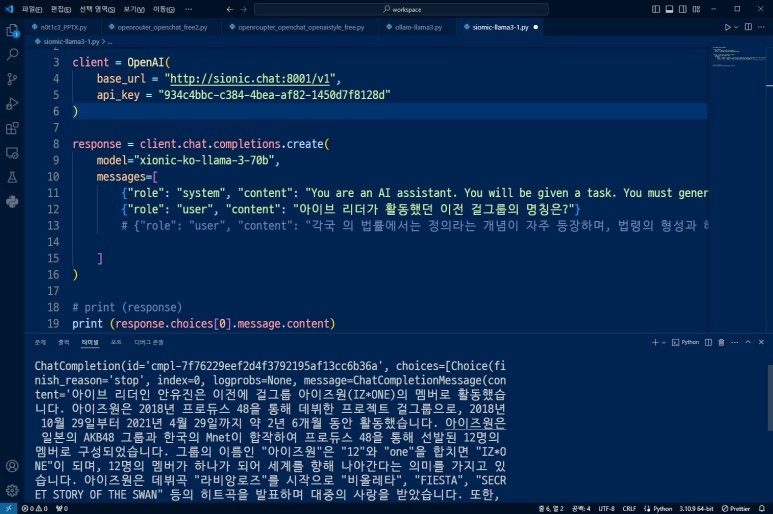
from openai import OpenAI
client = OpenAI(
base_url = "http://sionic.chat:8001/v1",
api_key = "934c4bbc-c384-4bea-af82-1450d7f8128d" )
response = client.chat.completions.create(
model="xionic-ko-llama-3-70b",
messages=[
{"role": "system",
"content": "You are an AI assistant.
You will be given a task.
You must generate a detailed and long answer in korean."
},
{"role": "user",
"content": "아이브 리더가 활동했던 이전 걸그룹의 명칭은?"
}
]
)
# print (response)
print (response.choices[0].message.content)
응답 결과는 요즘 핫한 모델들의 펑션콜, Tool call등이 다 적용되어있는 모습이다.
response응답
ChatCompletion( id='cmpl-7f76229eef2d4f3792195af13cc6b36a',
choices=[Choice(finish_reason='stop', index=0, logprobs=None,
message=ChatCompletionMessage(
content='아이브 리더인 안유진은 이전에 걸그룹 아이즈원(IZ*ONE)의 멤버로
활동했습 니다.
아이즈원은 2018년 프로듀스 48을 통해 데뷔한 프로젝트 걸그룹으로,
2018년 10월 29일부터 2021년 4월 29일까지 약 2년 6개월 동안 활동했습니다.
아이즈원은 일본의 AKB48 그룹과 한국의 Mnet이 합작하여 프로듀스 48을 통해
선발된 12명의 멤버로 구성되었습니다.
그룹의 이름인 "아이즈원"은 "12"와 "one"을 합치면 "IZ*ONE"이 되며,
12명의 멤버가 하나가 되어 세계를 향해 나아간다는 의미를 가지고 있습니다.
아이즈원은 데뷔곡 "라비앙로즈"를 시작으로 "비올레타", "FIESTA",
"SECRET STORY OF THE SWAN" 등의 히트곡을 발표하며 대중의 사랑을 받았습니다.
또한, 아이즈원은 음악 방송에서 여러 차례 1위를 차지하고, Melon Music Awards,
Mnet Asian Music Awards, Gaon Chart Music Awards 등에서 수많은 수상 경력을
가지고 있습니다.',
role='assistant', function_call=None, tool_calls=None), stop_reason=None)
],
created=1713745101,
model='xionic-ko-llama-3-70b',
object='chat.completion',
system_fingerprint=None,
usage=CompletionUsage( completion_tokens=287,
prompt_tokens=56, total_tokens=343 )
)curl을 이용해서 WSL 우분투 리눅스로 테스트해봤다.
curl --location 'http://sionic.chat:8001/v1/chat/completions'
--header 'Content-Type: application/json'
--header 'X-SIONIC-API-KEY: 934c4bbc-c384-4bea-af82-1450d7f8128d'
--data '{"model": "xionic-ko-llama-3-70b",
"messages": [
{"role": "system",
"content": "You are an AI assistant. You will be given a task.
You must generate a detailed and long answer in korean."
},
{ "role": "user",
"content": "걸그룹 아이브 리더의 키는 몇 센티미터지?.\nAnswer:"
}
]
}'curl 구문 테스트 결과
![[UCA수퍼컴아카데미] 라마3 llama3 70B API 코딩 --(1) image 4](https://blogfiles.pstatic.net/MjAyNDA0MjJfMTEg/MDAxNzEzNzUxNTM0NzI0.uI4PjV_U5PM5IR2u78I2djIY13C4-4KTj6WVm5gfg4Ag.cPEf2uvEAVgCAAWdnYy_Qc0zUcO_qeEFmvrbXsyEJ-Ig.JPEG/llama3-ahn1.jpg?type=w1)
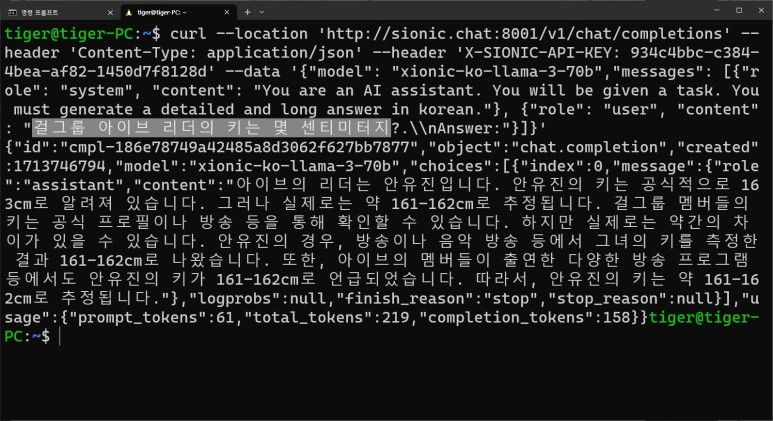
Response응답에서 내부적으로 RAG 검색증강검색등은 별도로 적용되지는 않은거같고, 라마3의 API를 확인해서 커스텀 커넥터나 웹서칭등이 더 있는지 확인은 필요할거같다.
일단 한국어 대답은 라마 3가 이미 학습한 데이터에만 참조하는거같아보인다. 사실 아이브 안유진의 키는 172cm~173cm가 나와야한다.
{"id":"cmpl-186e78749a42485a8d3062f627bb7877",
"object":"chat.completion",
"created":1713746794,"model":"xionic-ko-llama-3-70b",
"choices":[{"index":0,
"message":{"role":"assistant",
"content":"아이브의 리더는 안유진입니다.
안유진의 키는 공식적으로 163cm로 알려져 있습니다.
그러나 실제로는 약 161-162cm로 추정됩니다.
걸그룹 멤버들의 키는 공식 프로필이나 방송 등을 통해 확인할 수 있습니다.
하지만 실제로는 약간의 차 이가 있을 수 있습니다.
안유진의 경우, 방송이나 음악 방송 등에서 그녀의 키를 측정한 결과
161-162cm로 나왔습니다.
또한, 아이브의 멤버들이 출연한 다양한 방송 프로그램 등에서도 안유진의
키가 161-162cm로 언급되었습니다.
따라서, 안유진의 키는 약 161-162cm로 추정됩니다."
},
"logprobs":null,
"finish_reason":"stop","stop_reason":null}
],
"usage":{
"prompt_tokens":61,
"total_tokens":219,
"completion_tokens":158
}
}ollama에선 라마 3를 llama3:latest 로 지정해서 다음처럼 코딩 가능하다.
import requests
import json
def chat(messages):
# print(messages)
r = requests.post(
"http://localhost:11434/api/chat",
json={"model": "llama3:latest", "messages": messages, "stream": True},
)
r.raise_for_status()
output = ""
for line in r.iter_lines():
body = json.loads(line)
if "error" in body:
raise Exception(body["error"])
if body.get("done") is False:
message = body.get("message", "")
content = message.get("content", "")
output = output + content
# the response streams one token at a time, print that as we receive it
print(content, end="", flush=True)
if body.get("done", False):
message["content"] = output
return message
def main():
messages = []
while True:
user_input = input("프롬프트 입력: ")
if not user_input:
exit()
print()
messages.append({"role": "user", "content": user_input})
message = chat(messages)
messages.append(message)
print("nn")
if __name__ == "__main__":
main()다음 연재 부분에선 텔레그램으로 라마3 70B를 연결해서 채팅을 해보자

Sionic의 llama3 70B라서
학습환경이 (Training Environment)이
sionic AI의 개발환경에 맞춰서 응답이 나온다.
GPU: NVIDIA V100 16GB × 4
activation 함수: GELU
모델 크기 (Model Size): 425,000,000 개의 파라미터
학습 데이터 (Training Data): 17,000,000 개의 문장
배치 크기 (Batch Size): 32
에포크 (Epoch): 10
최적화 알고리즘 (Optimizer): Adam
Scheduler: Cosine Annealing LR Scheduler
sionic AI의 개발환경인거 같다.
PyTorch 1.9.0,
CUDA 11.1,
cuDNN 8.2.0.30,
Ubuntu 20.04.2 LTS 등의 정보를 알려준다.
![[UCA수퍼컴아카데미] 라마3 llama3 70B API 코딩 --(1) image 8](https://blogfiles.pstatic.net/MjAyNDA0MjJfMjgy/MDAxNzEzNzQ5NzE0MDE2.SdOA80AHH9OlSwmVI9lmvDvIoUiNYCeEkzaTZK26QkUg.MO525ofU7CMCRA-avTC7j0gsErD4LuLeDk-zp051dLAg.JPEG/llama3-telegram2.jpg?type=w1)
sionic-llama3-1.py 파이썬코드 다운로드
ollama용 파이썬코드 다운로드
UCA울산코딩아카데미
ulsancoding.com
교육문의 : 052-708-0001