[UCA수퍼컴아카데미] nVidia n-way GPU프로그래밍 CUDA 기초 --(1)

울산UCA코딩아카데미 nVidia n울산-way GPU 프로그래밍 CUDA 기초 --(1)
CUDA는 Compute Unified Device Architecture 의 준말로 엔비디아 (nVidia)사의 GPU 장비를 사용해서 병렬 프로그래밍을 하게 해주는 프로그래밍 인터페이스입니다.
보통 C/C++확장 형태로 공급됩니다. 요즘 nVidia의 수퍼컴퓨터에도 인텔 칩 에뮬레이션 기능이라던가 OpenACC, Cuda-C, Cuda-Python등이 설치되어 있습니다.
2006년이후, CUDA 12.3.X까지 나와있고, 윈도 OS말고도 WSL 2같은 윈도 11 OS내에서 서브 시스템으로 돌아가는 우분투 리눅스 22.0 LTS에서도 CUDA 및 nVidia 카드용 RTX 드라이버가 지원되기때문에 적절한 WSL2용 드라이버를 설치하면 윈도 리눅스 서브시스템에서도 CUDA가 돌아갑니다.
보통 이런 가속기로는 인텔의 OneAPI, OpenCL이나 AMD RocM등이 비슷한 아류들인데, AMD는 윈도 OS에선 적진인 CUDA 지원이 잘 안되는 편이고, 대신 리눅스 OS쪽에선 RocM하고 적절한 리눅스 드라이버만 설치하면 잘 지원한다고 합니다.
유명한 딥러닝 개발툴인 메타의 PyTorch, 구글의 keras, Tensorflow등이 CUDA를 적극 지원하고 있고, caffe, numba, RAPIDS등의 개발도구들도 있습니다.
CPU는 메모리에 연속된 데이터들을 다루는데 특화된 칩이고, GPU는 대규모 병렬 처리에 특화된 칩으로 아카텍처 구조상 사용하는 영역에서 성능의 차이가 난다는게 다릅니다. CUDA 코어가 보통 8천개~1만 6천개 정도 장착되어있다면 각각의 쿠다 코어 성능은 매우 약하지만 병렬로 처리를 하다보니 총 처리량이 CPU를 압도하는겁니다.
프로그램은 시작은 원래 CPU에서 먼저 로드되는데 이 부분을 HOST라고 하고, GPU는 DEVICE라고 표시합니다. GPU 메모리는 Device Memory겠죠. GPU DEVICE에서 동작하는 함수는 커널(KERNEL)이라고 합니다.
그리고 연산하려는 데이터를 GPU 메모리로 복사하는 코드에선 이렇게 표시합니다.
cudaMemcpy(d_x, x, N , cudaMemcpyHostToDevice);
보통 메모리에서 GPU 메모리로 데이터를 옮기고 계산을 하는데,
GPU 연산을 위해 메인 메모리에서 GPU 디바이스 내부의 메모리로 올리는데 비용이 많이 소요되고, Memcpy로 메모리 복사가 일어나는 시간만큼 연산 속도도 늦어집니다. CPU 연산에서는 메모리의 데이터가 바뀌면 메모리의 값들을 EAX, EDX같은 레지스터에 정보를 저장을 하는 단계가 필요하다면 GPU는 1024개의 코어들에 다 레지스터를 일일이 박아놔서 컨텍스트 스위칭이 일어나지않는다고 합니다. 맡겨놓은 연산만 열심히 하면 됩니다.
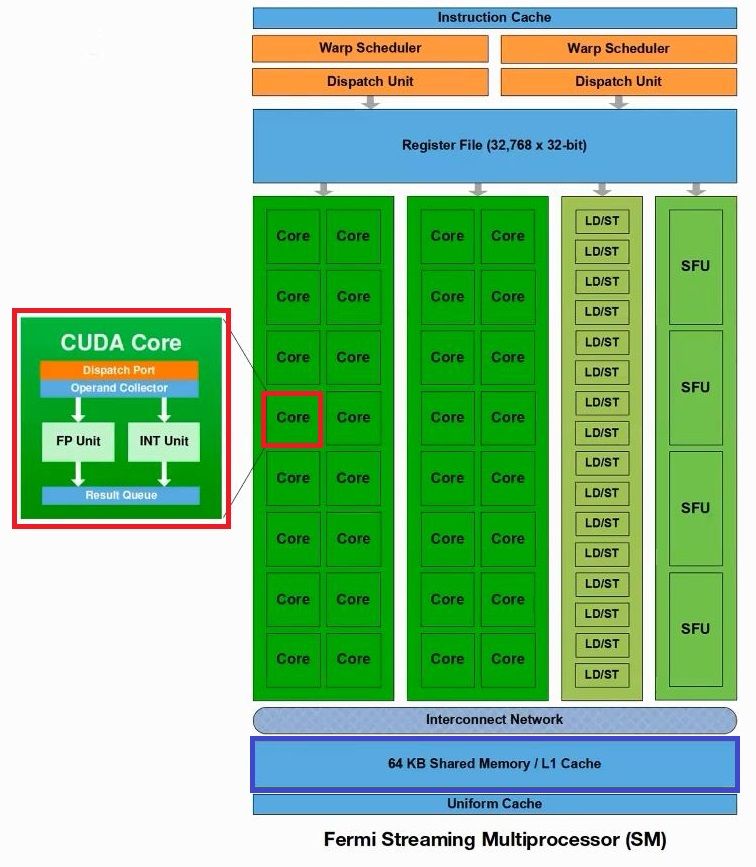
쿠다코어 32개씩 묶인 단위를 스트리밍 프로세서라고 하는데, 1개 명령어에 대해서 32개 연산을 동시 실행합니다.
스트리밍 프로세서는 약 32개씩 묶은 CUDA 코어외에 인스트럭션 캐시, 공유메모리 (L1캐시)등을 갖고있는데 공유 메모리가 프로그래밍이 가능해서 딥러닝 연산의 경우, 가중치등을 공유 메모리에 담아놓고, 한꺼번에 연산을 시킬수 있습니다.
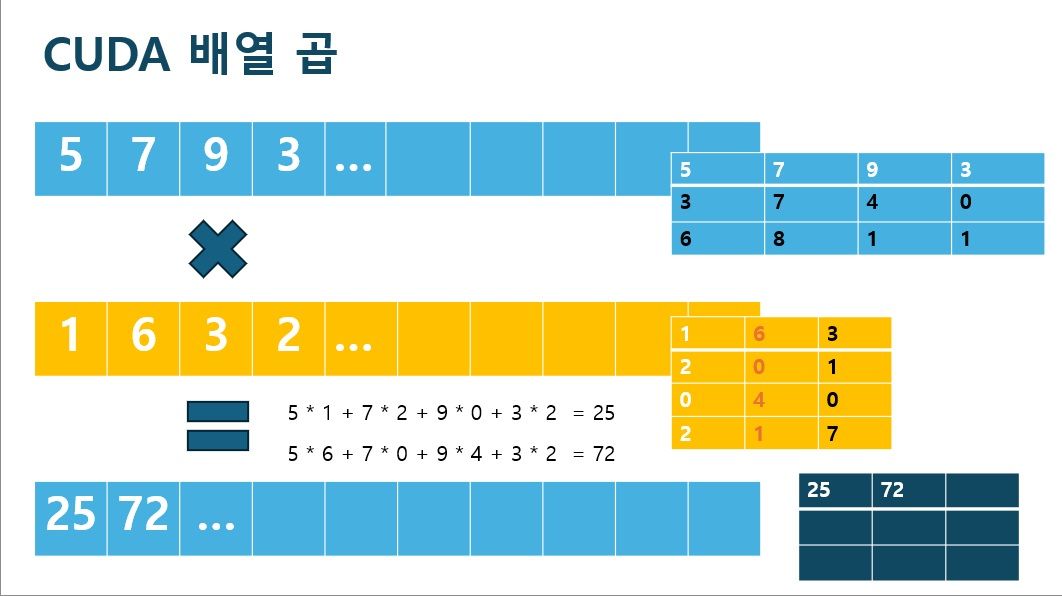
CUDA 코어라고해도 약 1000여개 <배열의 합> 연산 정도에선 전혀 빠른 편이 아닙니다. 오히려 CPU보다 속도가 더 늦습니다.

| 배열사이즈 | CPU | GPU |
|---|---|---|
| 1000 | 0.000000 | 0.000018 |
배열이 십만개 정도면 두 프로세서의 성능이 대체로 비슷하고, 계산해야할 배열이 한 1백만개는 넘어가야 그 때부터 제대로 GPU 성능이 나오는 겁니다.
| 배열사이즈 | CPU | GPU |
|---|---|---|
| 1,000,000 | 0.000315 | 0.000025 |
| 2,000,000,000 | 1.182974 | 0.025922 |
GPU연산은 <행렬 곱>처럼 병렬로 수십만 개씩 나눠서 쭉 계산하는것만 연산에 도움이 되고, 사실 한 개 단위씩 연산하는건 별로 도움이 안됩니다. 한 개 단위는 CPU가 더 빠르고 훨씬 낫습니다.
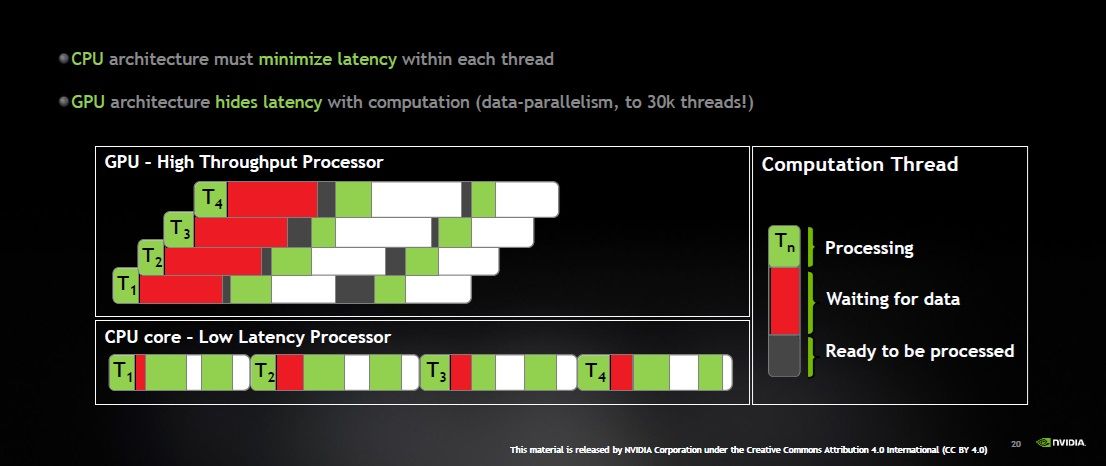
그리고, 아래 붉은 색이 장비가 연산 데이터를 기다려야하는 구간인데, CPU는 중간에 노는 구간이 4군데입니다. GPU쪽은 그걸 거의 다 한 곳에 모아둔겁니다. 그리고, 데이터가 도착하자마자 나머지 구간에서는 장비가 하나도 놀지않고 병렬로 계속 연산을 하게 만들고 있죠.
그래서 IF .. ELSE 같은 조건문은 각 블럭 덩어리를 나눠서 연산시켜야만 연산 효율이 좋습니다. ELSE 블럭을 타면 IF 블럭 쪽의 쓰레드가 다 멈춰야 하므로 같은 블럭을 안 타게 코딩하는게 "기술"입니다.
Cuda toolkit 12.X 다운로드를 하면 CUDA C 컴파일러인 NVCC가 들어있는데, 파일확장자는 .cu 이고, 병렬 처리용입니다.
compiler-explorer.com 사이트에서 우측에서 언어를 고를때 CUDA-C를 선택하고 설치없이 코드를 구경해 볼 수 있습니다.
NVCC는 GCC 사용자라면 능숙하게 사용할 수 있습니다.
Cuda toolkit 안에는 덩치가 큰 CuDNN 라이브러리같은건 따로 받아야합니다. CUDA 라이브러리용 매뉴얼등은 포함됩니다.

일단 CNN 딥러닝을 설명하는 블로그등에 방문해보면 첨부 이미지등을 살펴봅니다, MNIST 손글씨 이미지 같은걸 길게 한 줄의 768바이트 배열처럼 만들어줍니다. 그리고 RGB값을 읽어서 연산을 할때, 해당 배열에서 지금 연산해야하는 배열의 좌표가 GPU 코어에서는 대충 어디에서 연산해야하는지 계산해주는 식처럼 보일겁니다.

만약 연산을 해야 할 데가 1144 의 위치라면 512나 1024 블럭 단위인 512 * 2 + 120 으로 표시할수 있는데,
그림에서
int i = blockIdx.x * 2 (=blockDim.x) + threadIdx.x 처럼 몇번째 블럭에서 배열이 위치하는 좌표를 찾아서 계산하는 겁니다.

NVCC 문법은 대충 한줄로 길게 늘린 배열에서 1024 단위로 나눈 블럭의 연산하려는 배열의 위치를 찾도록 코딩하는 식으로 되어있다고 보면 됩니다.
그리고 GPU메모리로 복사하는 명령인
cudaMemcpy(d_x, x, N , cudaMemcpyHostToDevice);
명령등이 보입니다.
다음 시간에는 nVidia가 n-way GPU 교육에 사용하는 구체적인 C 코드 예제를 보면서 설명을 이어나가겠습니다.
ulsancoding.com을 방문하시면 더 많은 아티클을 보실 수 있습니다.