
GPT 모델 별 할루시네이션(Hallucination) 평가보드

현대 기술이 급격히 발전함에 따라, 인공 지능의 부상과 함께 대규모 언어 모델(LLMs)이 주목받고 있습니다. 이러한 모델의 진화는 매력적이지만, 그 성능에 대한 객관적인 평가 또한 중요한 문제입니다.

벡타라(Vectara)가 제공하는 '공개 LLM 리더보드'는 문서를 요약할 때 LLM이 허위 정보, 즉 '환각(hallucination)'을 얼마나 자주 만들어내는지를 측정하는 '환각 평가 모델'을 이용하여 계산했습니니다. 벡타라는 모델과 LLMs의 업데이트에 발맞추어 이 리더보드를 정기적으로 갱신할 계획이라고 밝혔습니다.
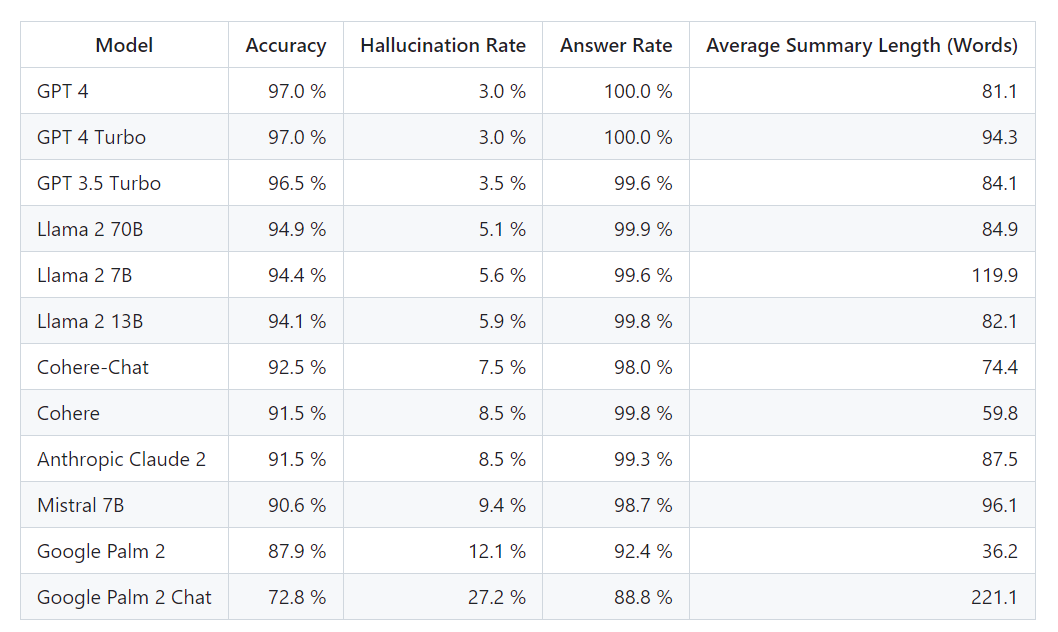
2023년 11월 1일 마지막으로 업데이트된 이 리더보드에 따르면, GPT-4는 3%의 환각 발생 비율과 100%의 답변률을 기록하고 있습니다. 이 데이터는 LLM의 성능을 객관적으로 비교할 수 있는 기준을 제공합니다.
모델이 요약 작업을 수행하며 발생하는 환각을 감지하는 과정은 광범위한 공개 데이터셋을 활용한 트레이닝을 통해 이뤄졌습니다. CNN / Daily Mail Corpus에서 가져온 1,000개의 짧은 문서를 기반으로, 각 모델에게 공개 API를 통해 이 문서들을 요약하도록 요청한 결과입니다. 이 중 831개 문서가 모든 모델에 의해 요약되었으며, 나머지 문서들은 콘텐츠 제한으로 인해 최소 한 모델에 의해 거부되었습니다.
환각률만을 따지지 않고 요약의 정확성을 평가하는 이유는, 모델의 응답이 제공된 정보와 일치하는지, 즉 '사실적으로 일관성'이 있는지를 비교할 수 있기 때문입니다. 모든 아무질문에 대해 정확히 어떤 데이터가 LLM에 트레이닝되었는지 알 수 없어 환각을 결정하는 것은 불가능합니다.
RAG(검색 결과 증강 생성) 시스템에서도 이러한 LLM 모델들이 점점 더 많이 사용되고 있습니다. 예시로 Bing Chat과 Google의 채팅 통합에서 LLM은 검색 결과를 요약하는 역할을 하게 됩니다. 이로 인해 벡타라의 리더보드는 RAG 시스템에서 모델이 사용될 때의 정확성에 대한 좋은 지표가 될 것입니다.