
[번역글] 음성인식, 음성합성, 그리고 더 많은 일을 할 수 있는 SpeechT5
원문은 Huggingface 공식 블로그에 영어로 게시되어 있습니다.
Speech Synthesis, Recognition, and More With SpeechT5
SpeechT5는 Microsoft Research Asia의 SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing 라는 논문에서 처음 소개되었습니다. 저자가 배포중인 공식 체크포인트는 Hugging Face Hub에서도 이용할 수 있습니다.
다음의 데모에서 바로 이용해볼 수 있습니다:
소개
SpeechT5는 하나도 둘도 아닌 세가지의 음성 모델이 하나의 아키텍처에 있습니다.
Speech to Text 모델
음성 인식과 화자 구분 태스크를 수행합니다Text to Speech 모델
텍스트에서 음성을 합성합니다Speech to Speech
목소리를 변환하거나 음성 품질(원문: Speech Enhancement)을 향상시킵니다
Text to Speech, Speech to Text, Text to Text, Speech to Speech 데이터를 혼합하여 하나의 모델에 학습시키는 것이 SpeechT5의 기본 아이디어입니다. 이를 통해서 모델은 텍스트와 음성에 대해 동시에 배울 수 있습니다. 이러한 접근방법의 결과로 모델은 텍스트와 음성을 모두 표현할 수 있는 통합된 공간(원문: Unified space of hidden representation shared by both text and speech)을 가지게 됩니다.
SpeechT5의 중심은 일반적인 Encoder-Decoder 트랜스포머 모델입니다. 다른 트랜스포머 모델과 비슷하게, Hidden Representation을 이용하여 Sequence to Sequence 태스크를 수행하게 됩니다. 이러한 트랜스포머 구조는 SpeechT5가 수행하는 모든 태스크를 뒷받침합니다.
하나의 트랜스포머가 텍스트와 음성 데이터를 모두 다룰 수 있게 하기 위해서, Pre-nets와 Post-nets라는 레이어를 추가하였습니다. Pre-net은 입력되는 텍스트와 음성을 트랜스포머가 이해할 수 있도록 Hidden representation으로 변환하고, Post-net은 트랜스포머의 출력을 다시 텍스트와 음성으로 변환합니다.
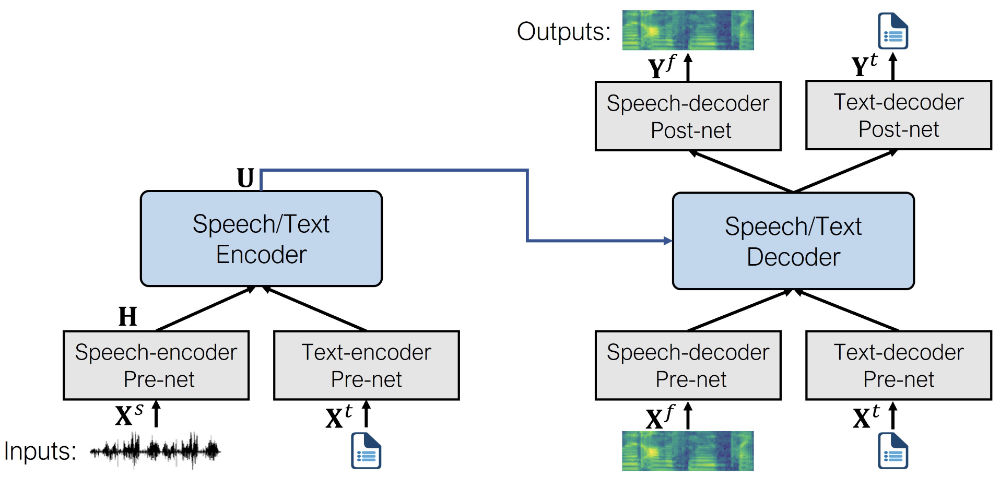
사전학습의 과정에서는 pre-nets와 post-nets를 모두 사용합니다. 이후 미세조정의 단계에서는 주어진 태스크(역자: 음성인식, 음성합성, 음성변환 등..)에 맞게 pre-nets와 post-nets중 필요한 것만 선택적으로 사용합니다. 예를 들어 SpeechT5를 음성 합성(Text to Speech)에 사용하려면 텍스트 입력을 위한 텍스트 인코더 pre-net, 음성 출력을 위한 음성 디코더 pre-net, 음성 디코더 post-net이 필요합니다.
메모: 사전학습 모델의 가중치에서 미세조정이 시작된다고 해도, 추가 학습이 끝난 이후의 모델은 처음과 상당히 달라집니다. 그렇기 때문에, 미세조정을 통해 음성인식 모델을 만들고 pre-nets와 post-nets를 서로 바꿔낀다고 하더라도 제대로 동작하는 음성합성 모델을 만들 수는 없습니다. SpeechT5는 유연한 모델이지만, 그런 방식의 유연함은 아닙니다.
Text to Speech
음성 합성 태스크를 위해서 다음의 pre/post nets를 사용합니다.
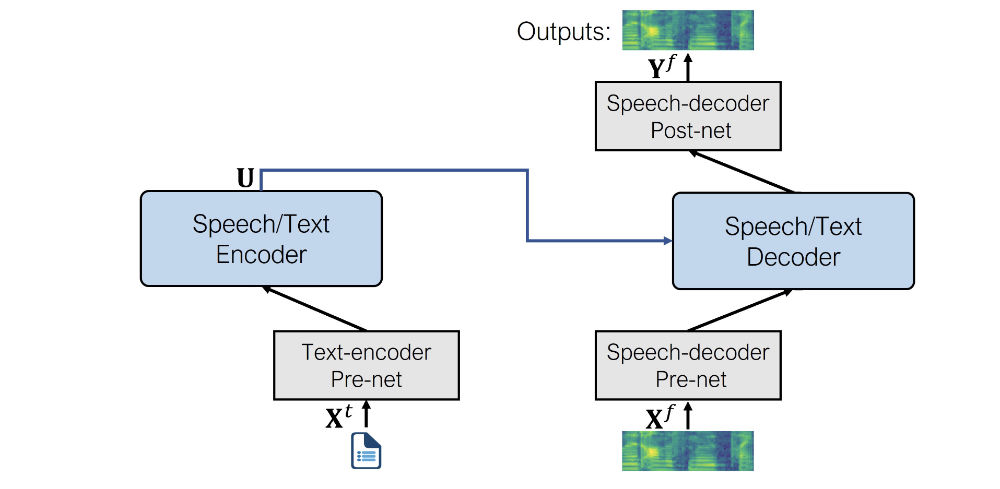
텍스트 인코더 pre-net
트랜스포머의 인코더가 이해할 수 있도록 텍스트 토큰을 Hidden Representation으로 변환해주는 텍스트 임베딩 레이어입니다. BERT 같은 NLP 모델과 비슷한 일을 합니다.음성 디코더 pre-net
Log mel spectrogram을 Hidden representation으로 변환하는 linear layer입니다. Tacotron 2 TTS 모델에서 차용하였습니다.음성 디코더 post-net
출력되는 스펙트로그램에 더해질 잔차(Residual) 값을 계산하는데 사용됩니다. 동일하게 Tacotron 2 TTS 모델에서 차용하였습니다.
미세조정된 음성합성 모델의 구조는 다음과 같이 표현될 수 있습니다.
역자: 모델을 사용하는 방법에 대한 내용은 번역하지 않습니다. 원문을 참고해주세요.
음성 변환을 위한 Speech to Speech
SpeechT5를 통한 음성 변환은 음성 합성과 개념적으로 동일합니다. 간단하게 텍스트 인코더의 Pre-net을 음성 인코더 Pre-net으로 바꿔끼면 됩니다. 나머지 부분은 모두 동일합니다.
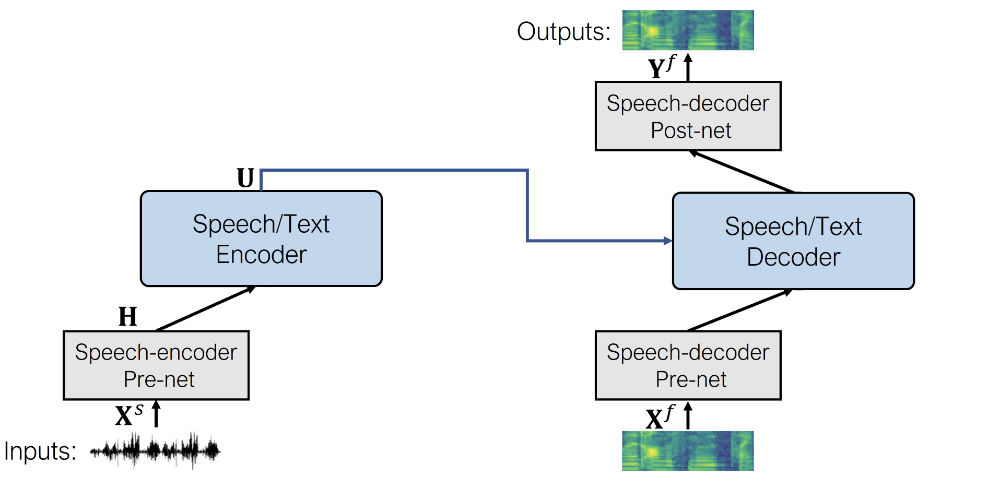
음성 인코더 pre-net은 Wav2Vec2의 Feature encoding module과 동일합니다. 입력되는 waveform을 audio frame representations의 sequence로 downsampling하는 컨볼루션 레이어로 구성됩니다.
역자: 동일하게 모델을 사용하는 방법에 대한 내용은 원문을 참고해주세요.
음성 인식을 위한 Speech to Text
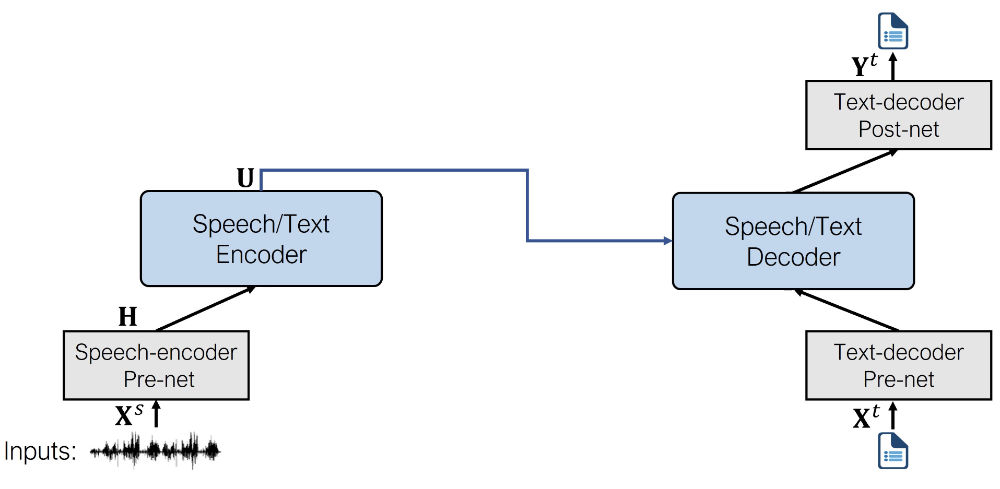
음성 인식 모델은 다음과 같은 pre/post-net을 사용합니다.
음성 인코더 pre-net
Speech to Speech 모델에 사용한 것과 동일한 pre-net입니다. wav2vec2에서 가져온 CNN Feature encoder 레이어들로 구성되어있습니다.텍스트 디코더 pre-net
음성 합성 모델에서 사용한 텍스트 인코더 pre-net과 동일하게, 임베딩 레이어를 통해 텍스트 토큰을 Hidden Representation으로 변환합니다. 사전학습 과정에서는 텍스트 인코더 pre-net과 텍스트 디코더 pre-net 사이에 임베딩이 공유됩니다.텍스트 디코더 post-net
트랜스포머에서 출력된 Hidden representation을 각 텍스트 토큰의 등장 확률로 변환해주는 single linear layer입니다.
역자: 동일하게 모델을 사용하는 방법에 대한 내용은 원문을 참고해주세요.
마무리
SpeechT5는 다른 모델들과 다르게, pre/post-net만의 교체를 통해 다양한 일을 하나의 아키텍쳐에서 수행할 수 있는 흥미로운 모델입니다. 여러 태스크를 한번에 사전학습했기에, 각 태스크에 대해 미세조정이 된 모델은 더 좋은 성능을 낼 수 있습니다.
음성합성, 음성인식, 음성변환에 대해서만 가중치를 공유했지만, 논문에서는 음성번역 / 음성향상 / 화자인식 태스크에서도 성공적이였다고 밝혔습니다.