
1. 한국어 GPT 모델 직접 증류해보기
DaramGPT: Knowledge Distillation으로 가벼운 GPT 만들기한양대학교, 디지스트 학부 입시 특기자전형에 제출했던 보고서를 공개합니다. 원본의 작성일자는 2022년 9월 18일 ~ 10월 14일입니다.
컴퓨터로 자연어 문제를 해결할 때에, 딥러닝 기반의 대규모 언어모델을 미세조정하여 활용하는 방법은 어느덧 대세가 되었습니다. 하지만 대규모 모델을 가동 하는 데에는 거대한 연산량이 필요합니다. 그렇기 때문에, 대규모 모델을 사용자의 디바이스에서 직접 실행하는 데에는 한계가 있습니다. 대규모 모델은 언어 이해 능력을 끌어올리기 위해 여러가지 조건을 희생합니다. 그 조건들에는 모델을 구동하는데 필요한 연산량, 파인튜닝을 하는데 소모되는 자원, 연산 지연시간, 에너지 소비 등이 포함됩니다.
이러한 문제를 해결하기 위해, 대규모 모델을 압축하는 방법을 사용할 수 있습니다. 대규모 모델을 압축하면 원본 모델의 성능은 거의 잃지 않으면서 많은 파라미터 수로 인한 단점들을 해소할 수 있습니다. 이번 연구에서는 Knowledge Distillation 기법을 활용하여 한국어 언어 생성 모델을 작게 압축하는 과정을 다루고자 합니다.
목차
대규모 언어모델의 동향\
Knowledge Distillation에 대해\
Distillation 직접 해보기\
실험 결과 및 측정치
자연어처리 문제에 딥러닝을 접목하는 분야는 폭발적으로 성장하고 있습니다. Transformers를 활용한 BERT 모델이 발표된 이후로 사전 학습된 언어모델의 가능성이 대두되었습니다. 이후 GPT, RoBERTa, XLNet, T5 등의 Transformers를 활용한 대규모 사전학습 모델들이 일부 태스크에서는 인간을 능가하는 언어 처리 능력을 입증하며, 여러 Downstream Task 모델들을 쉽게 개발할 수 있는 발판을 마련하였습니다.
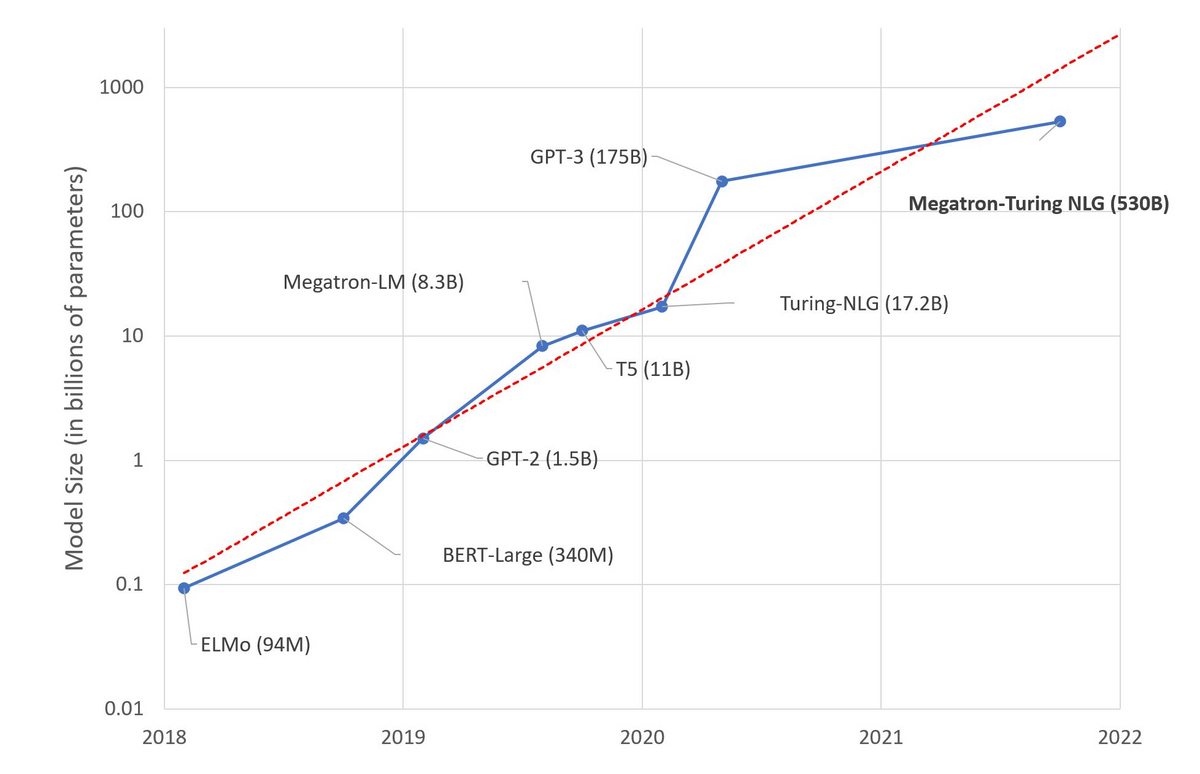
이러한 성장의 배경에는 개별 모델 파라미터 수의 증가가 있었습니다. 위 그래프는 대규모 언어모델들의 파라미터 수를 연도별로 시각화 한 그림입니다. 시간이 지날 수록 선형적으로 증가하는 것 처럼 보일 수 있지만, 우리는 y축이 10의 지수승이라는 것에 집중해야 합니다. 매년 평균 10배에 가깝게 파라미터 수가 증가하고 있습니다.
위 모델들의 성능 지표에 따르면, 대체로 모델의 크기가 커짐에 따라 각종 Downstream task의 성능도 높아지는 모습을 볼 수 있습니다. 심지어 GPT-3와 같은 대규모 생성형 모델에서는 별도의 미세조정 없이도 자연어 문맥을 통해 일부 Downstream Task를 SOTA급으로 수행해내는 성과를 보이기도 하였습니다.
이러한 성과에 비추어봤을 때, 앞으로 언어 모델은 “더 크게, 더 많이”의 대결이 될 가능성이 커보입니다. 하지만 많은 파라미터 수가 장점만 가지는 것은 아닙니다. 많은 파라미터 수는 많은 연산량을 뜻하고, 이는 필요한 전력과 컴퓨팅 자원의 상승으로 이어집니다. 그렇기 때문에 사용자의 디바이스는 물론, 일반적인 성능의 서버에서 대규모 모델을 구동하는 것은 불가능에 가깝습니다.
이러한 대규모 모델의 문제점을 해결하기 위해 모델 압축 기법을 사용할 수 있습니다. 모델 압축은 대규모 모델의 성능은 거의 유지하면서 많은 파라미터 수로 인한 실행 부담을 줄이는 방법입니다.